







摘要
We focus on the problem of training RL agents on multiple training environments to improve observational generalization performance. In prior methods, policy and value networks are separately optimized using a disjoint network architecture to avoid interference and obtain a more accurate value function. We identify that the value network in the multiple-environment setting is more challenging to optimize and prone to overfitting training data than in the conventional single-environment setting. In addition, we find that appropriate regularization of the value network is required for better training and test performance. To this end, we propose Delayed-Critic Policy Gradient (DCPG), which implicitly penalizes the value estimates by optimizing the value network less frequently with more training data than the policy network, which can be implemented using a shared network architecture. Furthermore, we introduce a simple self-supervised task that learns the forward and inverse dynamics of environments using a single discriminator, which can be jointly optimized with the value network. Our proposed algorithms significantly improve observational generalization performance and sample efficiency in the Procgen Benchmark.
我们专注于在多个训练环境中训练RL代理的问题,以提高观察泛化性能。在以往的方法中,策略网络和价值网络分别采用不相交的网络结构进行优化,以避免干扰,获得更准确的价值函数。我们发现,与传统的单一环境设置相比,多环境设置中的值网络在优化和容易过度拟合训练数据方面更具挑战性。此外,我们发现适当的正则化值网络是更好的训练和测试性能所必需的。为此,我们提出了DelayedCritic策略梯度(DCPG),它通过使用更多的训练数据来优化价值网络,从而隐式地惩罚价值估计,这可以使用共享网络架构来实现。此外,我们引入了一个简单的自我监督任务,使用单个鉴别器学习环境的正向和反向动态,可以与价值网络联合优化。我们提出的算法在Procgen基准中显著提高了观测泛化性能和样本效率。
研究背景
- 目前最先进的RL算法通常无法泛化到具有视觉变化的未见测试环境(即观察泛化),即使它们在训练环境中实现了高性能。
- 目前有几种方法试图通过采用源于监督学习的正则化技术或通过自监督学习训练健壮的状态表示来提高该框架中的泛化能力(集中在单一训练环境);同样存在一些针对多训练环境中策略和价值函数之间干扰的研究(解耦,PPG和IDAAC)。
- 文中作者认为,在多个环境中训练的价值网络更容易记住训练数据,而不能泛化到训练环境中未访问的状态
- 一些用于惩罚价值网络训练时过大的估计值的正则化方法,在防止过拟合的同时,会造成过早收敛,阻碍进一步提高性能。
文章贡献
- 提出了一种新的无模型策略梯度算法,称为延迟批评策略梯度(delay - critic policy gradient, DCPG),它以更少的更新频率训练价值网络,但比策略网络有更多的训练数据。
- 证明了它使用单一统一的网络体系结构为策略网络提供了更好的表示。
- 引入了一个简单的自监督任务,使用DCPG之上的单个鉴别器学习环境的正向和反向动态。
主要思想
- 提出的算法DCPG更像是PPO和PPG两种算法思想的整合
- DCPG延续了PPO使用共享参数的思想
- 共享参数的优势在于:每个目标训练的特征可以用来更好地优化另一个目标;
- 问题在于:
- 不清楚如何适当地平衡策略目标函数和价值目标函数的竞争(即存在优化一个目标对另一个目标造成干扰)
- 策略目标和价值目标使用相同的数据进行训练更新,各种超参数也一致(一种人为限制)
- DCPG没有采用PPG使用不同网络训练策略和价值函数的思想,采用了PPG分阶段训练的思想
- DCPG中与策略网络相比,用更少的更新频率训练价值网络,但训练数据更多
PPO

- 近端策略优化PPO,是一种无模型策略梯度方法,使用参数共享的方法,策略网络和价值网络的训练是共享参数的
- 训练过程:
- 更新之前,PPO首先使用旧的策略收集轨迹
- 更新时的目标函数,既包含了最大化策略目标函数,又包含的最小化价值目标函数
- 其中优势函数是通过GAE的方法求得的。
- 优缺点:
- 共享参数共同优化
- 优点:每个目标学到的表示也对其他目标有益,减少成本,加快训练
- 缺点:使优化变得复杂,单个编码器对多个目标进行优化(梯度有不同的规模和方向);限制了策略网络和价值网络在相同的训练超参数设置下进行优化
PPG
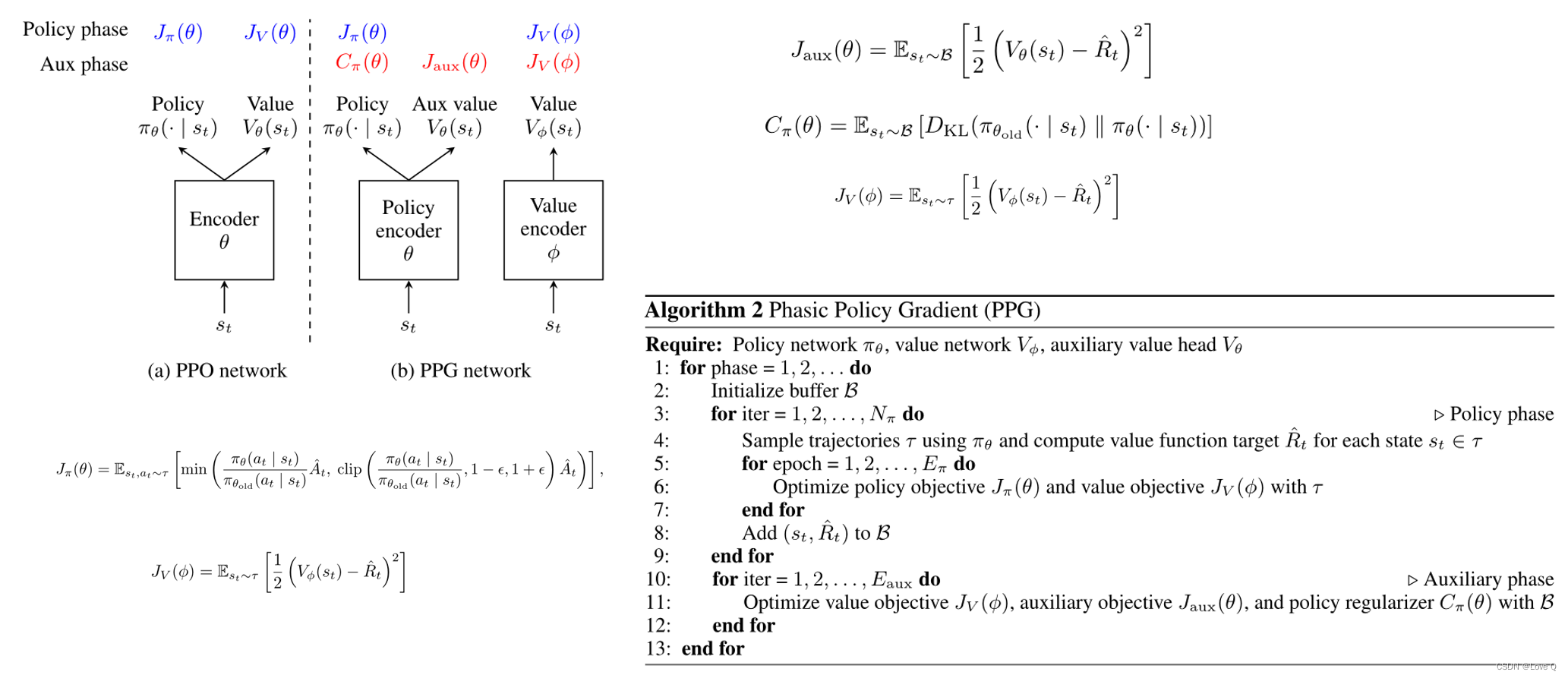
- PPG的提出和设计就是为了解决共享参数的问题
- PPG为策略网络和价值网络使用了单独的编码器,同时策略编码器引入了一个辅助值头,辅助值头的目的就在于从值网络中提取有用的表示给策略网络中
- PPG使用阶段性训练,训练分为策略阶段和辅助阶段
- 在策略阶段,使用新收集的轨迹训练策略和价值网络(使用PPO的目标函数)
- 之后将轨迹的所有状态和值函数存储在缓冲区中
- 辅助阶段,辅助值头和策略网络与缓冲区中的所有数据联合训练,优化辅助值目标Jaux和策略正则化器Cπ
- 辅助值目标函数的目的是,为了将价值网络提取到的特征与策略网络进行共享;策略正则化则是在这种共享的同时对策略进行限制,尽量保持原始策略。
- 辅助阶段同样会使用缓冲区的数据对价值网络进行优化,辅助阶段的训练数据大小是策略阶段的Nπ倍(每一回合开始会清空缓冲区),这种对价值网络进行的额外训练可以提高性能和样本效率。
DCPG
动机
多训练环境下价值网络的过拟合
- 事实证明,在给定的训练环境中,学习一个更接近真实价值函数的价值网络可以导致更好的训练表现
- agent在单一环境中进行训练,价值网络易于过拟合,并且这种过拟合问题在增加了训练环境数量后会进一步加剧(增加训练环境数量会进一步加剧过拟合问题)
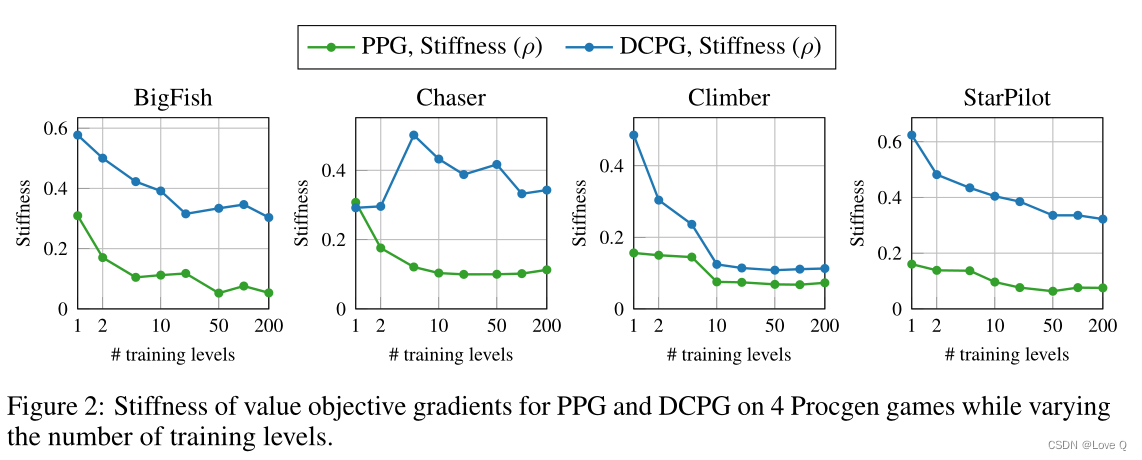
- 为了证明上述问题的存在,引入了状态(s, s`)之间的值目标梯度的刚度
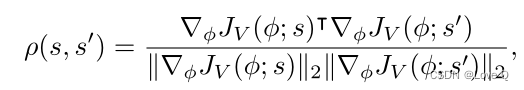
- 低刚度表示:
- 更新网络参数以最小化一个状态的值目标会损害最小化其他状态的值目标
- 具有较低刚度的值网络更容易记住训练数据
- 低刚度表示:
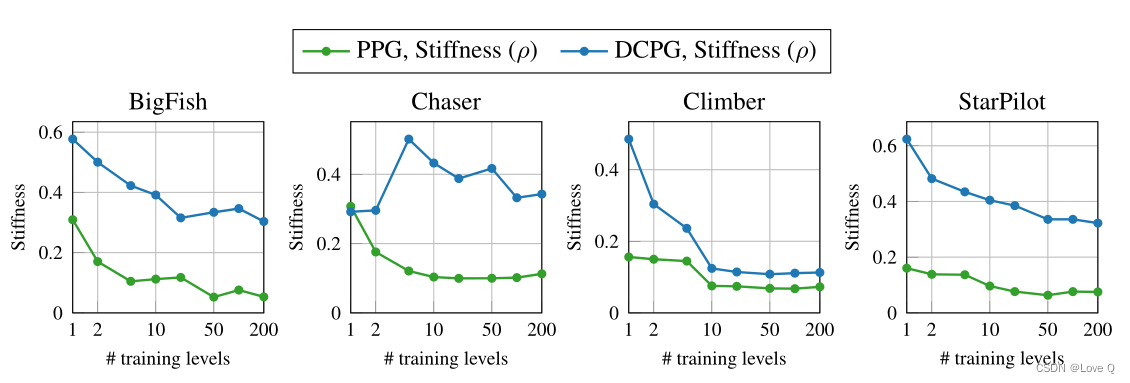
- 如图所示:
- 不同的level代表不同的训练环境
- 绿线表示:值目标梯度的刚度值随着训练环境数量的增加而减小,也就是说在多个环境中训练的值网络更容易记住训练数据,过拟合问题也更加严重
- 同时图中也表示了DCPG的效果要比PPG更好,即文中方法有效缓解了记忆问题
- 这个过拟合问题让我们训练一个具有足够正则化的价值网络
显式正则化训练值网络
- 这一部分主要证明了关于价值网络正则化在多环境设置中的有效性,同时又证明了正则化存在的收敛到次优的问题
- 两种常见用于防止值网络过拟合的方法
- 折扣正则化(DR):训练折扣因子的价值网络的方法
- 激活正则化(AR):对输出进行L2惩罚的值网络训练
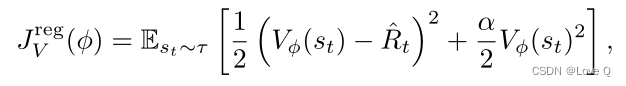
- 图a展示值网络正则化一定程度上提高PPG的训练和测试性能(DR中γ从0.999降低到0.995,AR使用α值为0.05,在Procgen游戏上使用200个level训练)
- 图b展示,随着环境步骤数量增加,显式正则化可能导致次优的解决方案,这表示过度的正则化会阻碍价值网络学习准确的价值函数
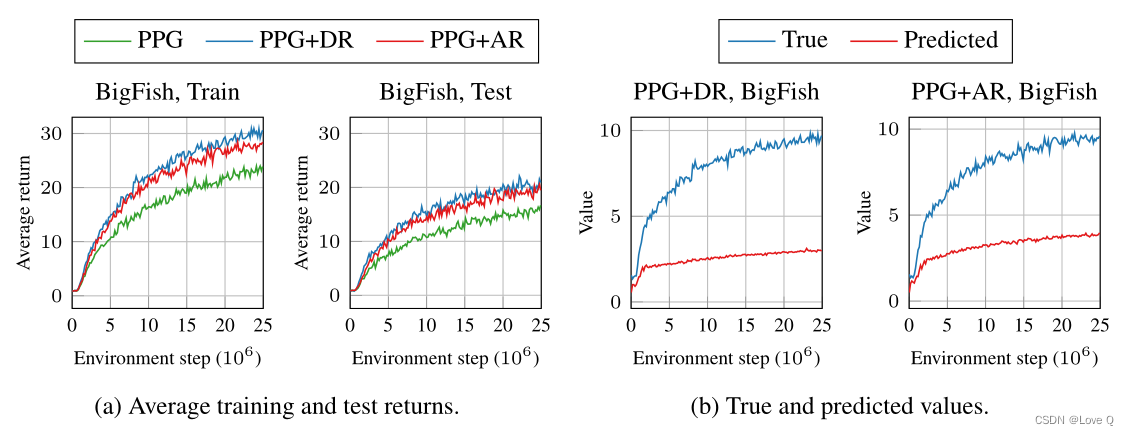
- 因此我们需要寻找更灵活的正则化,提高训练性能的同时,价值网络可以收敛到真实值。
DCPG思想
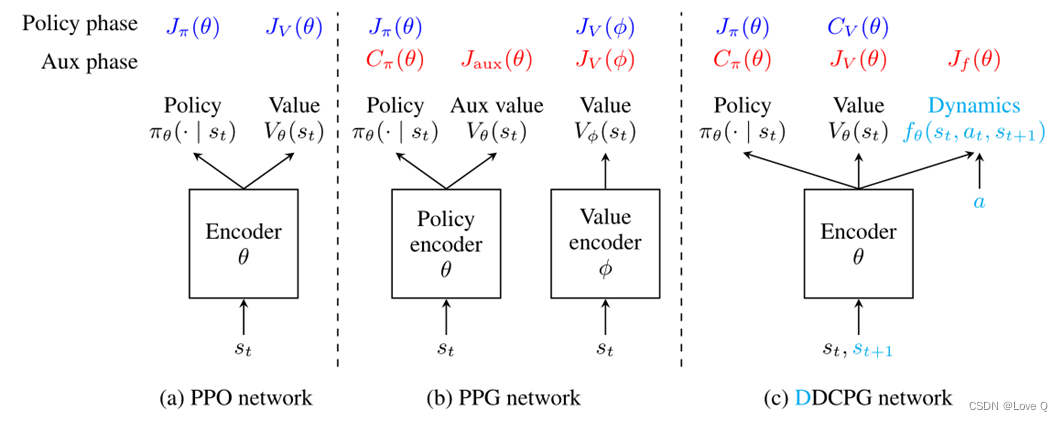
- 处理值函数的过拟合问题
- 价值网络的优化频率应当低于策略网络(抑制价值估计并减少过拟合)
- 使用更多的数据进行训练(防止过度拟合到最近的训练数据)
- C作为正则化项主要目的是使其尽量保持不变
- 因此策略网络更新频率要高于价值网络,同时更新价值网络时使用的数据规模更大
- 由于使用共享参数,不需要辅助值头实现特征共享
- DCPG中的延迟评论家更新可以作为价值网络的隐式正则化。由于政策改进不会立即反映在价值网络中,因此它会促使价值估计值小于真实值。
- 在训练的早期阶段,值估价值保持低于真实值,但随着训练的进行,值估价值恢复到真实值。
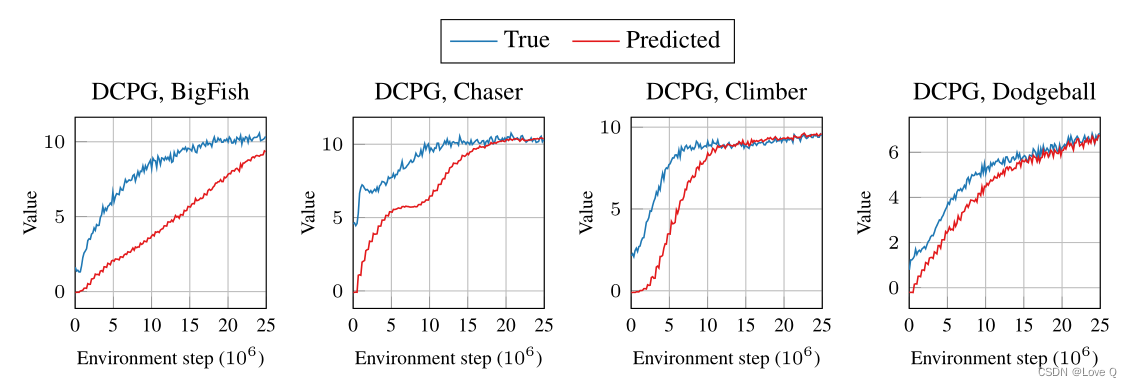
- 得出结论,DCPG中的延迟评论家更新是一个很好的价值网络正则化器。
DDCPG( Dynamics-aware Delayed-Critic Policy Gradient 动态感知延迟评论)
- 在多任务学习的背景下,学习辅助任务可以作为一个正则器,用于防止过拟合;本文考虑使用编码器的表示学习辅助任务,与辅助目标联合学习值网络
- 假设辅助阶段中使用的缓冲区B包含一个转换元组(st, at, st+1)。由于假设来自每个环境的转换函数具有相同的底层结构,因此训练一个神经网络来模拟编码器潜在空间中的环境的正向动态是很自然的。
- 辅助任务:
- 动态头fθ将当前状态的嵌入置于当前动作的位置作为输入,并预测下一个状态st的嵌入
- 作者使用鉴别器学习正向动态该鉴别器在给定当前状态和动作的情况下确定下一个状态是否有效(因为使用神经网络的前向动力学模型往往会过度拟合少量训练数据,并对未见状态的预测很差)
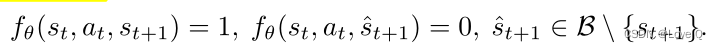
- 这样的鉴别器可能会丢弃有关操作的信息,以区分转换是否有效。例如,鉴别器可以通过仅使用当前状态和下一个状态的接近性来预测有效的转换
- 因此又增加了逆动力学的鉴别器(训练鉴别器来联合区分当前动作是否有效,给定当前和下一个状态(即逆动力学))
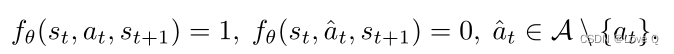
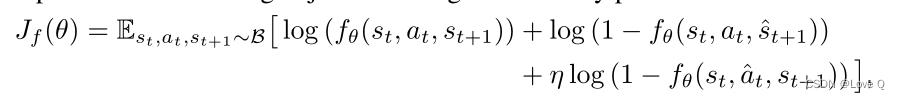
- 作者使用鉴别器学习正向动态该鉴别器在给定当前状态和动作的情况下确定下一个状态是否有效(因为使用神经网络的前向动力学模型往往会过度拟合少量训练数据,并对未见状态的预测很差)
- 动态头fθ将当前状态的嵌入置于当前动作的位置作为输入,并预测下一个状态st的嵌入
实验
消融实验
延迟评论家:为了解决延迟批评更新对学习策略网络的可泛化表示的影响

- 使用单独的编码器(separate DCPG)用附加值网络Vφ训练DCPG代理
- 分离值网络Vφ训练方法与PPG相同,没有延迟更新,仅用于策略优化。
- 原始值网络Vθ采用延迟更新训练,仅用于策略网络的学习表示。
- 是在PPG的基础上又增加了延迟更新的训练,最终效果证明了这种延迟更新批评的方法有利于学到效果更好的表示
证明使用单个鉴别器学习正向和反向动力学的有效性
- 进行了DCPG正向动力学学习(DCPG+F)、
- 反向动力学学习(DCPG+I)
- 使用两个独立鉴别器(DCPG+FI)正向和反向动力学学习的实验
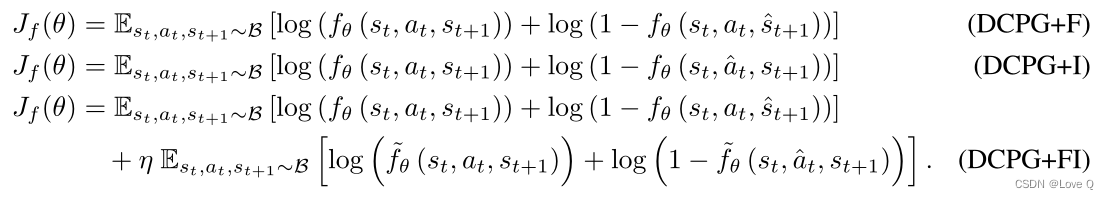
- 我们对使用单一鉴别器联合学习正向和逆向动力学的直觉是,单纯地学习正向动力学会丢弃动作的信息,只捕捉潜在空间中两个连续状态的接近性,而不是动力学。另外,使用单独的鉴别器进行逆动力学训练也不能完全解决这一问题。















 4733
4733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









