







简介
决策流又称规则流,它整个的结构类似于工作流,用来对已有的决策集、决策表、交叉决策表、决策树、评分卡、复杂评分卡或其它决策流的执行顺序进行编排,以清晰直观的实现一个大的复杂的业务规则。
URule Pro规则引擎中的决策流可以实现对已有的决策集、决策表、交叉决策表、决策树、评分卡、复杂评分卡或其它决策流进行编排执行;编排过程中既可以常见串行执行,也可以并行执行,或者是根据条件选择分支执行。URule Pro中提供了一个基于网页的流程设计器,通过简单拖曳就可以快速实现对已有的决策集、决策表、交叉决策表、决策树、评分卡、复杂评分卡或其它决策流执行顺序的编排。
一个设计好的规则流如下图所示:
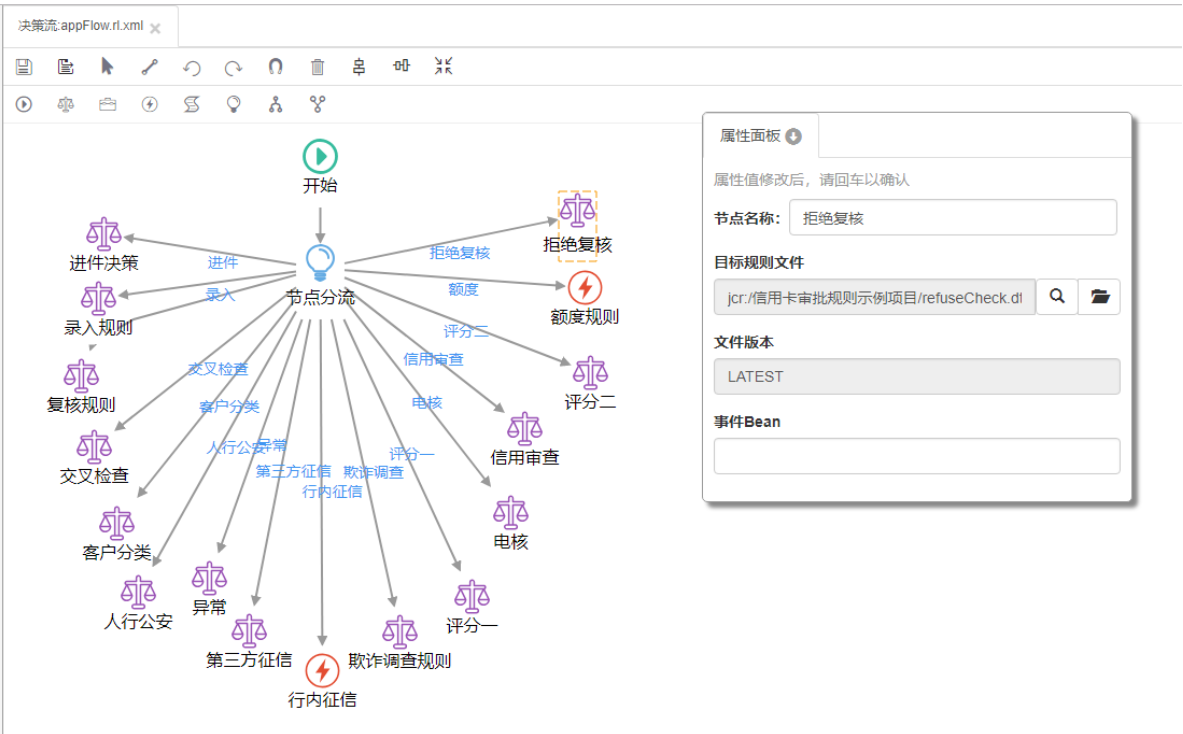
在这个流程设计器当中,上面是工具栏,下面是设计区,在工具栏第一排可实现流程模版的保存、选择、创建连接、重做、取消、网格吸附、删除、竖直居中对齐、水平居中对齐及将多个选中节点设置成相同尺寸等工具。 工具栏的第二排就是URule Pro中规则流支持的流程节点,URule Pro中规则流中共有八种类型的节点,分别是开始节点、规则节点、知识包节点、动作节点、向导式动作节点、决策节点、分支节点、聚合节点。 |
需要注意的是,URule Pro的决策流中没有结束节点,在URule Pro的决策流当中,决策流必须要以开始节点开始,可以在任何分支以任意节点结束,这点与类似UFLO 之类的工作流引擎不同,UFLO 之类的工作流引擎要求流必须要以开始节点开始,同时任何分支都必须要以结束节点结束。
一、创建决策流
打开URule Pro规则引擎控制台,在项目的决策流节点点右键,从右键菜单中选择添加决策流,创建一个新的决策流文件,如下图:
二、设计决策流
在设计器的设计区中,属性面板是可移动的,我们可以通过鼠标点击属性面板任何部位来移动它。点击工具栏第二行上的流程节点图标,然后在设计区单击,就可以在设计区添加对应节点。
在URule Pro的决策流中,节点图标的尺寸是可以通过鼠标改变的;节点创建完成后,可点击工具栏第一行上的连线图标,在节点间添加连接。点击工具栏上的选择图标,可实现节点或连线的选择,选择方式可以是点选,或拖选。
在定义好节点间的连线后,如需将连线变成折线,那么可以先采用拖选方式选中目标连线,如下图所示:

选中连线后,中连线中间就会出现可拖拽的锚点,拖动描点即可改变连线形状,如下图所示:
如不需要这个锚点,那么可以先取消连线的选择,然后再次选中连线,双击要删除的锚点,这样即可删除锚点对象,对应的连线也会回到没有锚点的状态。
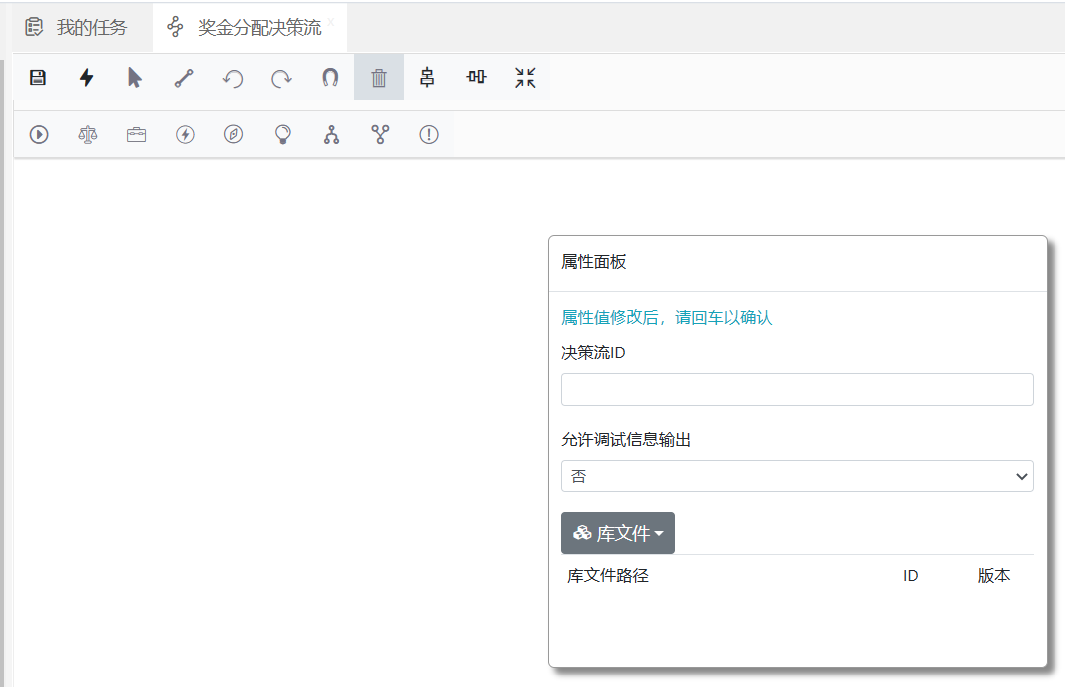
节点或连接选中后就可以在属性面板上修改它们的属性,点击选择图标后,在设计区空白处点击就可以配置决策流的全局属性,如定义决策流ID,需要导入的库文件等。
决策流的全局属性有两块,第一块就是决策流的ID,这个很重要,在一知识包中,如果有多个决策流,那么决策流ID要唯一;第二部分是导入相关库文件,这与之前介绍的决策集、决策表、决策树、评分卡一样,唯一不同是这里的库文件管理放在了属性面板上。
决策流工具栏按钮说明

开始节点
开始节点,是一个规则流开始的地方,在URule Pro当中,决策流必须要以开始节点开始,开始节点的属性比较简单,只有两个,如下表所示:
属性名 | 数据类型 | 描述 |
节点名称 | String | 设置当前节点名称 |
事件Bean | String | 一实现了com.bstek.urule.model.flow.NodeEvent接口配置在Spring中bean的id,一旦配置在流程进入及离开该节点时会触发这个实现类 |
package com.bstek.urule.model.flow;
import com.bstek.urule.model.flow.ins.FlowContext;
import com.bstek.urule.model.flow.ins.FlowInstance;
/**
* @author Jacky.gao
* @since 2015年4月20日
*/
public interface NodeEvent {
/**
* 规则流流入当前节点触发的方法
* @param node 当前节点对象
* @param instance 当前规则流实例对象
* @param context 规则流上下文件对象
*/
void enter(FlowNode node,FlowInstance instance,FlowContext context);
/**
* 规则流流出当前节点触发的方法
* @param node 当前节点对象
* @param instance 当前规则流实例对象
* @param context 规则流上下文件对象
*/
void leave(FlowNode node,FlowInstance instance,FlowContext context);
}开始节点出入连接线如下表所示:
流入的连接线数量 | 流出的连接线数量 |
0 | 1 |
规则节点
所谓规则节点,用来绑定URule Pro当中提供的决策集、决策表、交叉决策表、决策树、评分卡、复杂评分卡或其它决策流文件的节点。一个规则节点可以与一个或多个当前项目或公共项目中的决策集、决策表、交叉决策表、决策树、评分卡、复杂评分卡或其它决策流文件绑定,这样一旦决策流流转到当前节点,那么就可以执行与这个规则节点绑定的决策集、决策表、交叉决策表、决策树、评分卡、复杂评分卡或其它决策流文件。
在设计器中,选中目标规则节点,就可以在属性面板中设置其相关属性,规则节点属性如下:
属性名 | 数据类型 | 描述 |
节点名称 | String | 设置当前节点名称 |
事件bean | String | 一实现了com.bstek.urule.model.flow.NodeEvent接口配置在Spring中bean的id,一旦配置在流程进入及离开该节点时会触发这个实现类 |
规则节点出入连接下如下表所示:
流入的连接线数量 | 流出的连接线数量 |
1~n | 0~1 |
添加规则节点属性面板上的选择文件按钮,就可以给当前节点绑定一个或多个其它类型的规则文件。
知识包节点
与规则节点不同,知识包节点是用来与具体的知识包绑定的,这样就可以实现复杂规则调用。知识包节点与某个知识包绑定之后,运行时规则流流转到这个节点后,就会执行与之绑定的知识包,如果绑定的知识包中包含决策流,那么引擎会自动执行其中的决策流,如果规则包中包含的规则流有多个,那么默认只会执行其中的第一个规则流,否则只执行触发规则动作。
知识包节点属性如下表所示:
属性名称 | 数据类型 | 描述 |
节点名称 | String | 设置当前节点名称 |
事件bean | String | 一实现了com.bstek.urule.model.flow.NodeEvent接口配置在Spring中bean的id,一旦配置在流程进入及离开该节点时会触发这个实现类 |
知识包 | String | 要与当前节点绑定的具体的知识包,我们可以通过下拉列表选择当前项目下已创建好的可用知识包。可以选择当前项目中或公共项目中所有状态为已启用的知识包。 |
知识包节点出入连接线如下表所示:
流入的连接线数量 | 流出的连接线数量 |
1~n | 0~1 |
动作节点
动作节点可以与一个实现了com.bstek.urule.model.flow.FlowAction接口并配置到Spring中的Bean绑定,这样在运行时,规则流执行到这个动作节点时就会执行与之绑定的FlowAction实现类,动作节点属性如下表所示:属性名称 | 数据类型 | 描述 |
节点名称 | String | 设置当前节点名称 |
事件bean | String | 一实现了com.bstek.urule.model.flow.NodeEvent接口配置在Spring中bean的id,一旦配置在流程进入及离开该节点时会触发这个实现类 |
动作bean | String | 一个实现了com.bstek.urule.model.flow.FlowAction接口并配置到Spring中的Bean的ID。 |
FlowAction接口源码如下所示:package com.bstek.urule.model.flow;
import com.bstek.urule.model.flow.ins.FlowContext;
import com.bstek.urule.model.flow.ins.FlowInstance;
/**
* @author Jacky.gao
* @since 2015年2月28日
*/
public interface FlowAction {
/**
* @param node 当前节点对象
* @param context 规则流上下文件对象
* @param instance 当前规则流实例对象
*/
void execute(ActionNode node,FlowContext context,FlowInstance instance);
}有了动作节点,那么在规则流中就可以执行具体的Java类中的方法,因为该Java类是配置在Spring上下文中的,所以类中可访问Spring环境所有信息,这样就可以做一些更为复杂的业务操作。动作节点出入连接线如下表所示:
流入的连接线数量 | 流出的连接线数量 |
1~n | 0~1 |
在代码中获取工作区中的变量或者参数数据
KnowledgeSession ks = (KnowledgeSession) flowContext.getWorkingMemory();
Map<String,Object> factMap = ks.getFactManager().getFactMap();
//取工作区中变量
User user = (User) factMap.get("com.bstek.urule.sample.pojo.User");
//如果变量不存在对应的java pojo类,用GeneralEntity
GeneralEntity cust = (GeneralEntity) factMap.get("com.bstek.urule.sample.pojo.Cust");
//取工作区中参数double total = (double) ks.getParameter("total");在代码中往工作区中添加变量或者参数数据
//如果需要往工作区中添加变量数据
GeneralEntity newUser = new GeneralEntity("com.bstek.urule.sample.pojo.User");
ks.getFactManager().getFactMap().put("com.bstek.urule.sample.pojo.User",newUser);
//如果需要往工作区中添加参数数据
ks.getParameters().put("totalScore", 100);向导式动作节点
顾名思义,向导式动作节点就是可以在这个节点上绑定一个或多个向导式动作,这样在运行时,规则流流转到该节点时就可以执行绑定的动作。如下图所示:
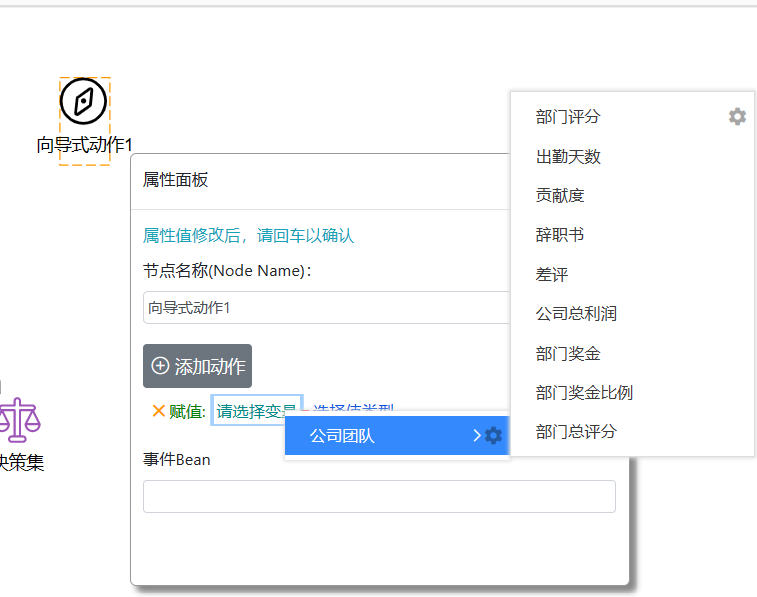
决策流中如果需要用到变量参数,也需要导入库文件可以看到绑定的向导式动作与在决策表中定义动作完全相同,我们可以参照决策集中定义动作的方式来绑定这里要执行的动作。
向导式动作节点出入连接线如下表所示:
流入的连接线数量 | 流出的连接线数量 |
1~n | 0~1 |
决策节点
决策节点就是指在运行时根据为其下流出连接配置的条件来决定究竟应该走哪条连接的节点,所以根据这一特性,决策节点下流出连接至少要有两条,否则决策节点就没有意义了。
选中决策节点,在其右边属性面板中就可以看到针对决策节点的配置,如下图所示:
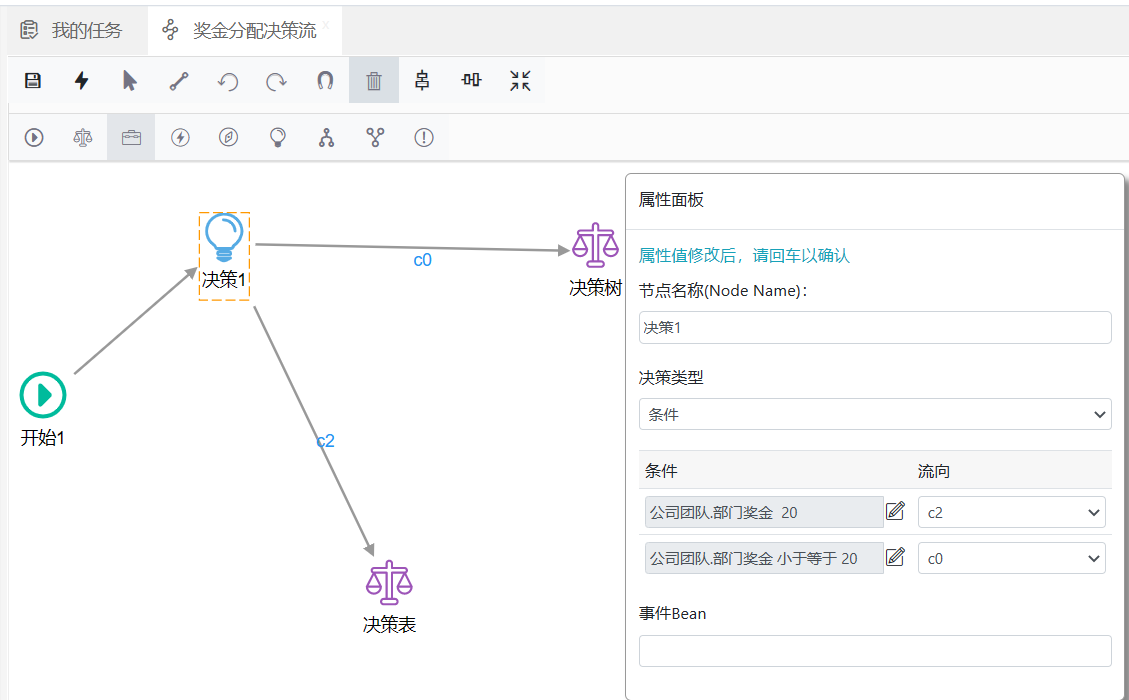
需要重点介绍的是“决策类型”属性,决策节点的有两种决策类型,分别是"条件"和"百分比"。
当选择决策类型为条件时,就会看到如上图所示效果。选择“条件”类型时,在下面出现的在决策项当中,可以根据当前决策节点下流出连接的数量添加对应的决策项,对于每条决策项,都有两个属性,分别是"条件脚本"和“流向”,在条件列当中,我们可以编写具体的条件,在流向列中选择当条件列中定义的条件满足时要流出连线名称,所以对于决策节点下流出的连线,我们必须要为其设置名称,否则就无法为其定义决策项。
为连线定义名称,需要首先用拖选的方式选中它,然后就可以在属性面板上为其定义名称。
在条件表格中,点击条件编辑按钮,就会弹出条件编辑窗口,在这个窗口里,可以为流转到该条路径定义条件。
如果将决策类型改为“百分比”,则可以看到如下图所示效果:
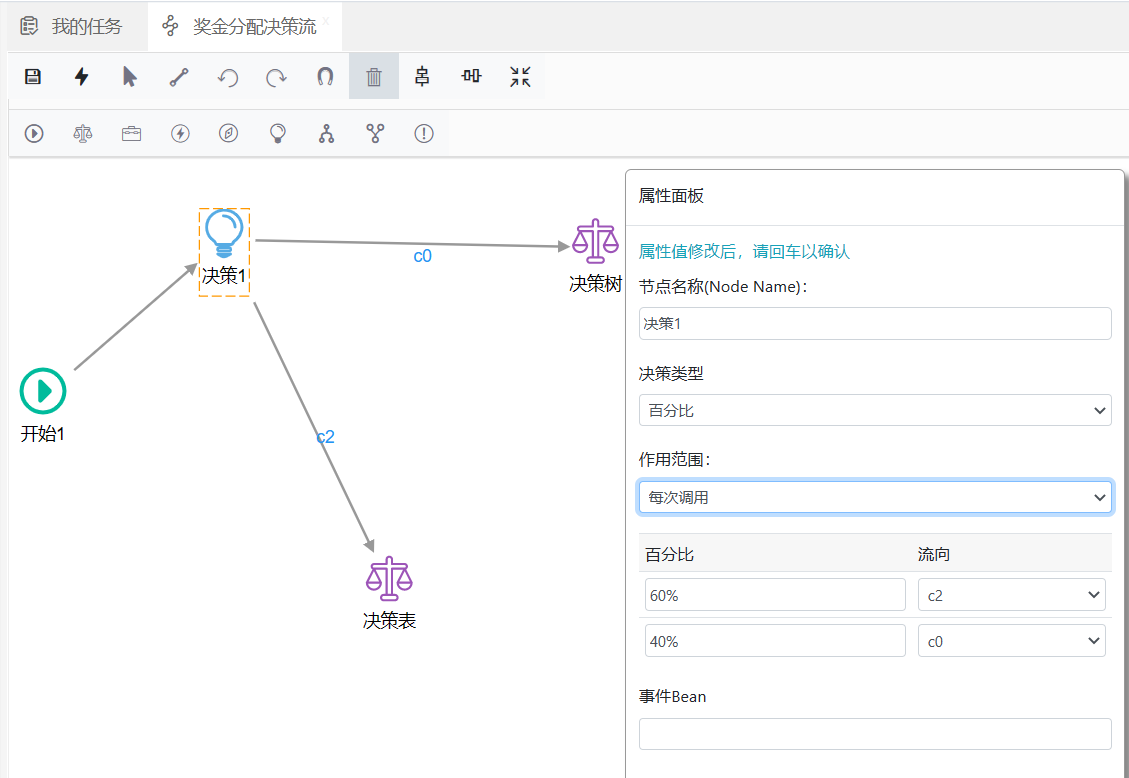
如上图所示,一旦将决策类型改为“百分比”,那么就可以为每个流向设置流量百分比,如上图当中,在实际规则流运行时,将有40%走"c0"连线,60%走"c2"连线。配置时无论决策节点下有多少离开连线,最终所有的百分比加在一起要达到100%, 百分比这里一定要是一个合法的整数,否则会出现错误。
百分比模式下还有一个名为“作用范围”的选项,默认值为“批处理”,表示“百分比”类型的计算有效期为当前线程,一旦有新线程开启,那么这个百分比的值将开始重新计算;如果将“作用范围”改为“每次调用”,那么生效就不再局限于当前线程,每次调用在经过这个决策节点时都会根据百分比进行分流计算。
值得注意的时,当选择决策类型为“条件”,在运行时,当决策流流转到当前节点时,如果决策项中定义的各个条件都不满足,那么规则流到此就结束了,相反,如果有多个决策项满足时,那么系统将取第一条满足条件的决策项对应的流向连线进行向下流转,而不会选择所有满足条件的连线向下流转。
需要注意的是,百分比类型的“批处理”作用范围下决策方式,必须要在代码中通过批处理的方式执行才会生效,必须要使用后面章节里介绍的BatchSession来一次性处理一批数据,或者一个KnowledgeSession一次性处理一批数据,否则规则流永远都只会走默认的百分比占比最高的那条路径。 当然如果百分比类型的作用范围改为“每次调用”,那么规则的每次调用都会根据百分比来计算分流。
决策节点出入连接线下如下表所示:
流入的连接线 | 流出的连接线 |
1~n | 1~n |
分支节点
分支节点是URule Pro当中提供的一种可实现规则流多条并行的节点,通过这个节点,可以根据当前节点下流出连线数量,将当前规则流实现拆分成若干条子的规则流实例并行运行,根据这一特性,分支节点下至少要有两条流出的连线才有意义。
在决策流实例流转到分支节点时,分支节点会根据其下流出的连接线数量将主的实例拆分成与连线对应的若干个子实例,以并行方式继续运行产生的多个流实例。
分支节点出入连接线如下表所示:
流入的连接线数量 | 流出的连接线数量 |
1~n | 1~n |
默认情况下,分支节点会将主流程拆分成若干子流程执行,在实际执行的时候还是在一个线程内先后执行各个分支。
在分支节点上有一个名为“启用多线程”的属性,默认情况下,如果不设置该属性,那么它的值为“系统默认”,这时将采用系统中定义的名为urule.flowForkMultiThread参数的值,由这个参数值来决定当前分支下是否采用多线程运行, urule.flowForkMultiThread参数值默认为false,也就是不开启多线程运行。
如果希望其下所有子分支以多线程形式并行,那么可以选中当前分支节点,将其“启用多线程”属性设置为“是”,或者将urule.flowForkMultiThread参数设置值为true,这样引擎在执行到分支节点时会在不同的线程中执行其下各个分支,这对于各个分支业务逻辑不相关的业务,同时各个分支执行比较耗时,通过这样的配置让分支在不同线程里执行,所以可以明显提高系统执行性能。
需要注意的是分支节点的“启用多线程”属性值为“系统默认”时采用的是名为urule.flowForkMultiThread参数的值,否则就会覆盖这个全局参数的值,由当前分支节点自主决定是否开启多线程。
注意,当设置了参数 urule.flowForkMultiThread=true 或配置了分支节点的“启用多线程”属性值为“是”时,分支节点下必须要添加一个聚合节点,将所有分支连接到聚合节点上,否则执行会出现错误。
注意:一般情况下,我们不推荐启用多线程,因为多线程开启后需要处理很多问题,无形中增加了运行的复杂度,所以不推荐开启多线程。
聚合节点
聚合节点就是用来聚合由分支节点拆分出来的多个子的规则流的,所以有聚合节点,就一定要有分支节点,但有分支节点却不一定需要聚合节点(但如果设置了参数urule.flowForkMultiThread=true,,或配置了分支节点的“启用多线程”属性值为“是”时,分支节点如果启用了多线程执行功能,这样分支节点下一定需要一个聚合节点,否则会出现错误),对于URule Pro的决策流来说,拆分出子的决策流后是否有聚合节点是可选的,但聚合节点的出现则一定要有分支节点来配合,否则聚合节点就没有意义了。
如果在决策流通过某个分支节点将一个主流程拆分成若干个分支,在分支中运行了几个需要并行处理的节点后,后面还有其它需要在主流程上运行的节点,那么就需要通过一个聚合节点将所有拆分出来的分支进行聚合,然后再在该聚合节点之后添加其它需要在主流程上处理的节点。
聚合节点出入连接线如下表所示:
流入的连接线数量 | 流出的连接线数量 |
1~n | 0~n |
异常捕获节点
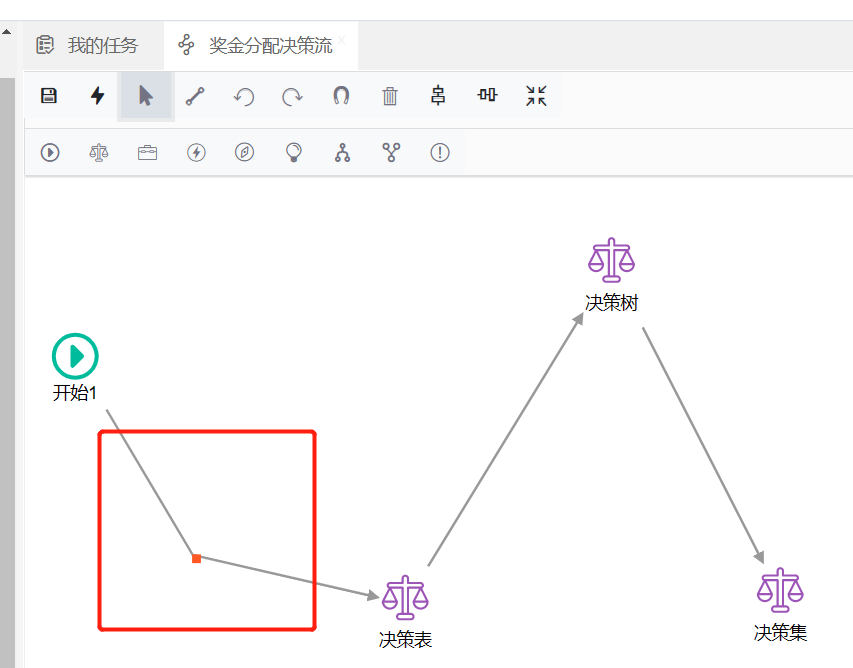
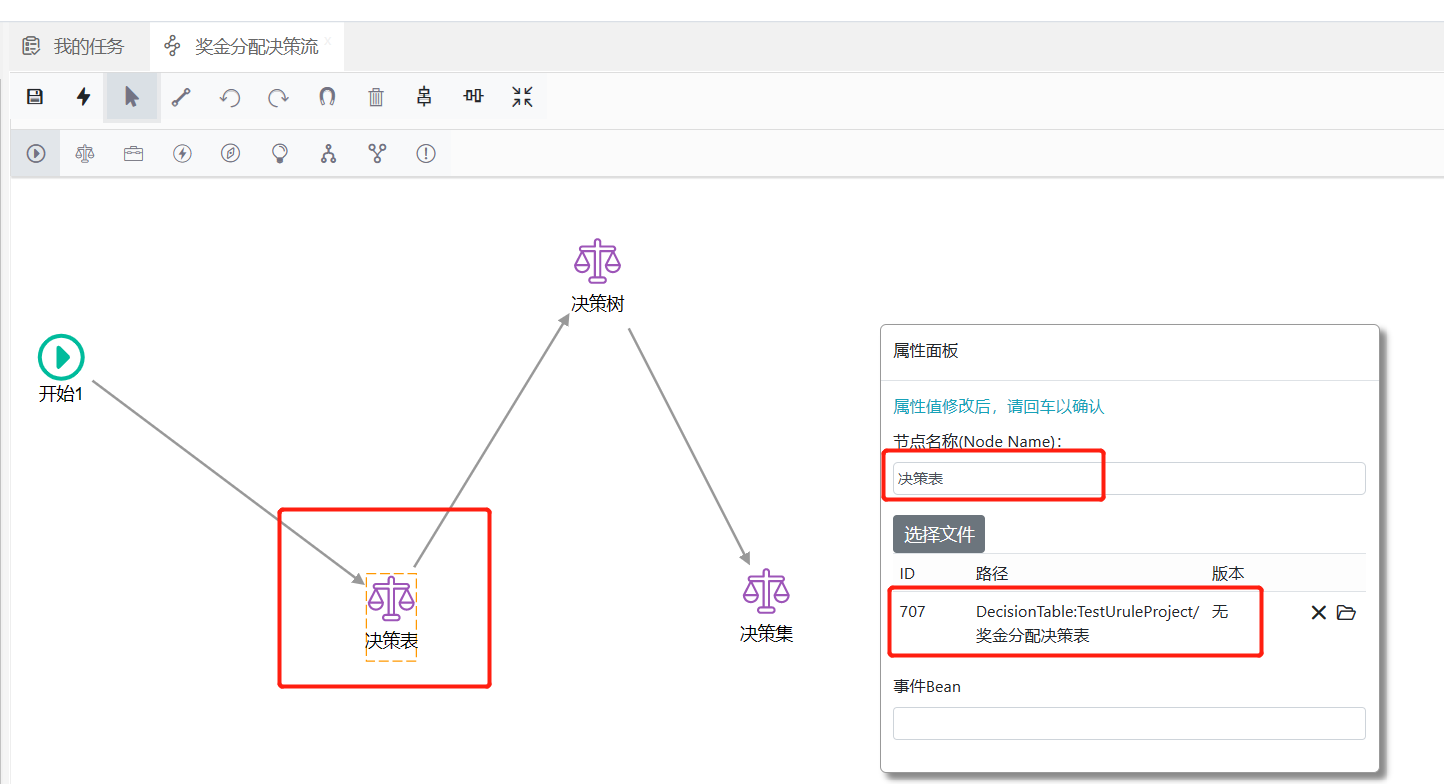
异常捕获节点的作用是捕获规则流中其它节点在执行时可能产生的异常,默认情况下在不添加异常捕获节点时,如果某个节点在运行时出现了异常,那么这个异常就会直接抛出,从而导致执行中断,为某个规则节点添加异常捕获节点后,一旦这个节点执行时出现异常, 那么异常会流向其下的异常捕获节点,我们可以在这个异常捕获节点中处理相应异常,也可以将规则流引流到其它的节点之后,从而避免由于异常而导致的执行中断,如下图所示:
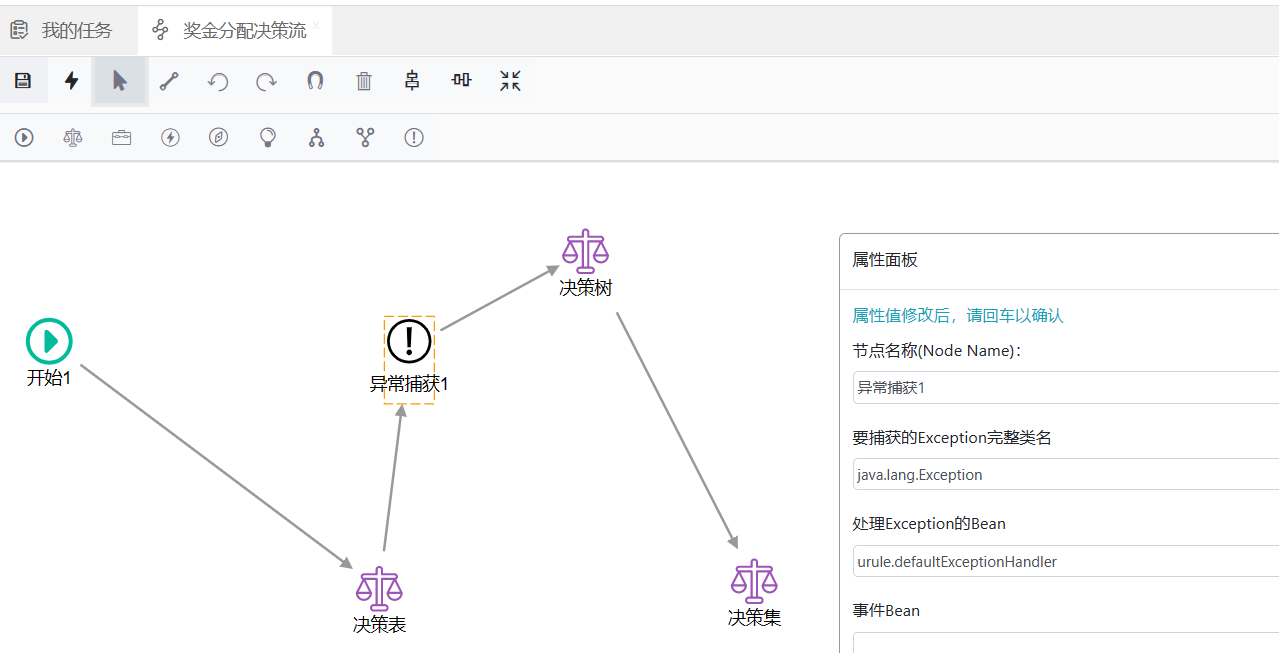
在上图当中我们为“决策表”节点添加了一个异常捕获节点,这样,在运行时,一旦“决策表”节点产生异常,那么规则流不会流转到“决策树”节点,而是流转到“异常捕获1”节点,然后再流转到“决策树”节点。 运行时我们会发现,如果“决策表”节点正常运行,那么规则流会正常流转到“决策树”节点,一旦发生异常,规则流就会流向其下的异常捕获节点,从而改变了规则流向,同时规则计算也不会中断。
异常捕获节点有两个属性需要我们注意:
属性名 | 含义 |
要捕获的Exception完成类名 | 默认它的值是java.lang.Exception,也就是说所有的异常都会被捕获,当然我可以修改这个属性,以使得当前节点只会捕获某个特定的Exception,需要注意的是我们需要输入完整的类名(包含包名),且必须是java.lang.Exception类或子类,该属性不能为空 |
处理Exception的Bean | 一个实现了com.bstek.urule.model.flow.ExceptionHandler接口并配置到Spring中的Bean的ID,默认值为urule.defaultExceptionHandler,引擎提供的一个会向控制台输出异常堆栈的默认实现,当然我们可以根据需要自己实现一个,该属性可以为空 |
三、测试决策流
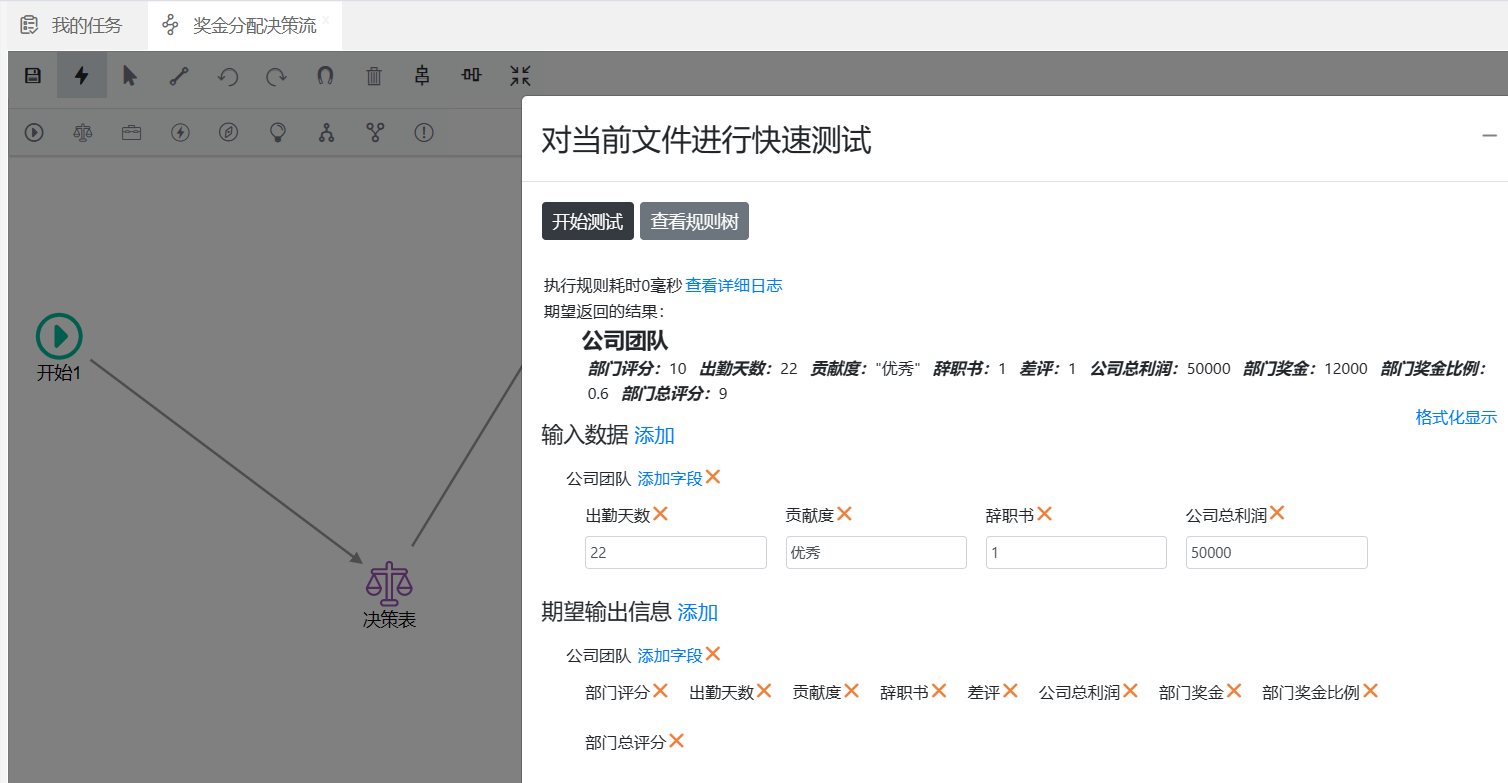
从测试结果看决策流可以实现对已有的设计规则进行编排执行(相当于java中代码的执行顺序,执行完毕后得出最终结果)
四、总结:
决策流可以实现对已有的决策集、决策表、交叉决策表、决策树、评分卡、复杂评分卡或其它决策流进行编排执行;编排过程中既可以常见串行执行,也可以并行执行,或者是根据条件选择分支执行,避免了调用复杂。

















 1695
1695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









