







使用爬虫爬取网页标题时,利用bs4解析p标签的内容后,某些标题里掺杂了 字符,该字符并没有以真正的空格显示,而是显示为字符串,所以我使用了replace()方法去除。
字符,该字符并没有以真正的空格显示,而是显示为字符串,所以我使用了replace()方法去除。
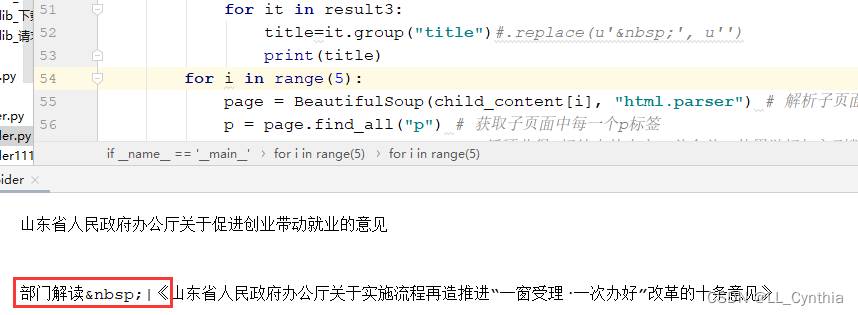
原代码:
for it in result3:
title=it.group("title")
print(title)
修改后:
for it in result3:
#通过replace()方法将字符串' '替换成了空字符串''
title=it.group("title").replace(u' ', u'')
print(title)
replace(u’需要被替换掉的字符串’, u’想要替换成的字符串’)
——END——














 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









