






KMP
考虑在字符串 S S S 中找到所有字符串 P P P 的出现位置。
1.暴力算法
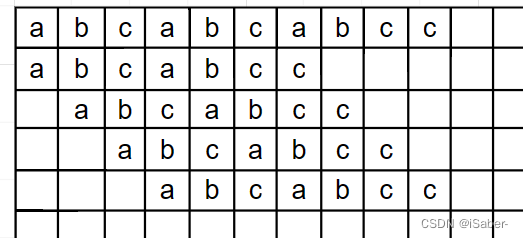
首先最直接的想法就是逐位比较,不一样则 P P P 向右移动一位就从头开始
设 S = a b c a b c a b c c S = abcabcabcc S=abcabcabcc T = a b c a b c c T = abcabcc T=abcabcc, 则过程为
2.优化
每次失配时, T T T 只向右移动一位,且 S S S 都要退回到 T T T 开头对应位置重新开始匹配,这样会使得时间复杂度变成 O ( N M ) O(NM) O(NM)。
现在我们需要匹配时 S S S 不退回,每次都从失配时的位置开始匹配,且 T T T 向右移动多位,这样大大优化时间。
假设我们在某一段已经匹配好了,但是下一位出现失配,我们考虑如何优化
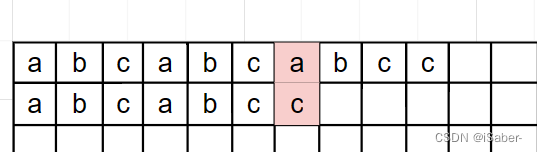
比如这里 a a a 和 c c c 失配了, 考虑将 T T T 向后移动
我们要保证 S S S 不回退,那么就需要我们把 T T T 向后移动到一个特别的位置,使得 S S S 以 a a a 前面一位结尾的后缀已经和 T T T 的前置匹配好了,这样我们就不用回退 S S S 。
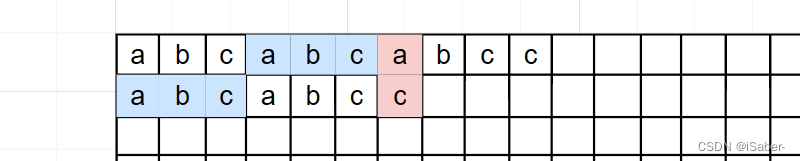
如上图的 刚好以 a a a 前一个位即 c c c 结尾的后缀 a b c abc abc 和 T T T 中的前缀 a b c abc abc 一样,所以我们只需把 T T T 移动到相应位置 S S S 就不用回退了。
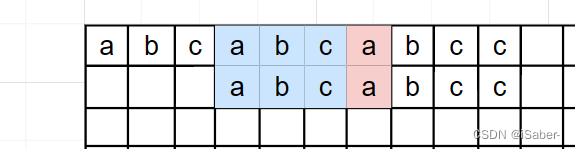
因为前面已经匹配好了。
那么现在的问题就是怎么找 T T T 移动多少位?

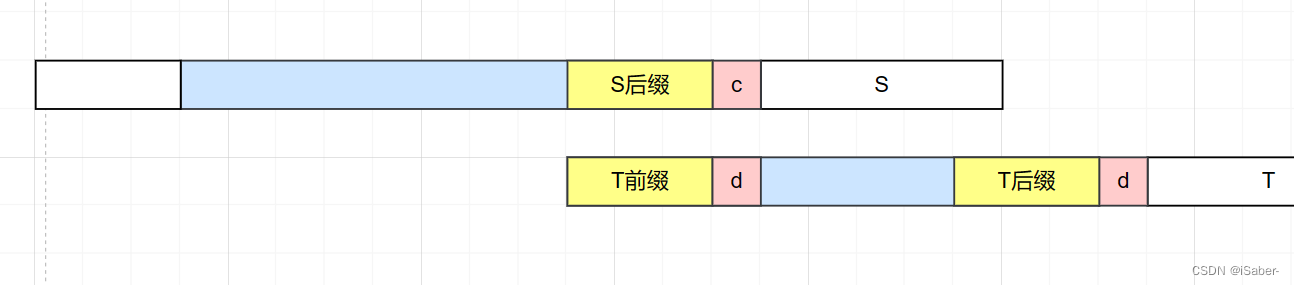
考虑上图,蓝色部分为已经匹配了,在 T T T 等于 d d d 时失配,假设找到了一处 S S S 后缀和 T T T 前缀相等(下图黄色部分),
那么必定有** T T T 的后缀和 T T T 的前缀相等**(如下图),因为在失配的字符前都是已经匹配好了的,即上图蓝色的部分是对应相等的。

所以我们只需要在 T T T 中找到它前缀和后缀相等的最长串称为最长公共前后缀(为什么要最长?),然后移动到相应位置即可。
但是如果我们发现还是不匹配怎么办呢?就重复刚才的过程,只是刚刚黄色的部分变成了蓝色的部分。

我们只要先预处理出来在 T T T 每个位置失配时这个最长公共前后缀的长度,每次失配时就知道该移动多少,就能大大加快算法了。
到目前为止我们就了解了 K M P KMP KMP 算法的主要思路了
即失配时, T T T 向右移动到合适位置,使得 S S S 不退回,每次都从失配时的位置开始匹配!
3.Next 数组
我们要先预处理出来在 T T T 每个位置失配时这个最长的前缀后缀的长度,不妨叫这个数组为 n e x t next next 数组
我们考虑通过递推的方式求出这个数组,假设箭头 p p p 前的最长前缀后缀的长度都求出来了,
通过前面的这些信息我们求出 p p% p 处的最长前缀后缀等于多少。

假设蓝色部分就是 p − 1 p - 1 p−1处即上一位的最长公共前后缀。
如果说他们的下一位都相等,即红色部分相等,那么
p
p
p 处的最长公共前后缀等于
p
−
1
p - 1
p−1 处的加一 (next[p] = next[p - 1] + 1)
如果不相等就要找一个最长的黄色的部分 S 1 S1 S1 他要和 T T T 的同样长的前缀 S 2 S2 S2 相等(如下图),
然后我们知道 S 3 = S 2 S3 = S2 S3=S2, 因为上图蓝色部分对应相等。
S 1 S1 S1 的长度就等于 S 3 S3 S3 结尾处的最长公共前后缀的长度 ,

然后比较
p
p
p 处的字符是否和
S
2
S2
S2 后一个相等,相等了 next[p] 就等于
S
2
S2
S2 长度加一。
如果还是不等就重复前面的过程直到相等或者公共前后缀为零。















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









