







与其埋头苦干地听取和记录大量的录音内容,不如让科技帮助你完成这项工作。没错,现在有一种强大的技术能够将录音实时转写成文本,让你更轻松地处理文字资料。想象一下,你只需要把录音文件导入到特定的软件中,它会实时将你说的话转化为文字,让你能够随时翻阅和编辑。那么,你是否好奇这些神奇的录音实时转写软件都有哪些呢?我今天将为你介绍三款好用的软件,一起来看看吧!

转录软件1:录音转文字软件
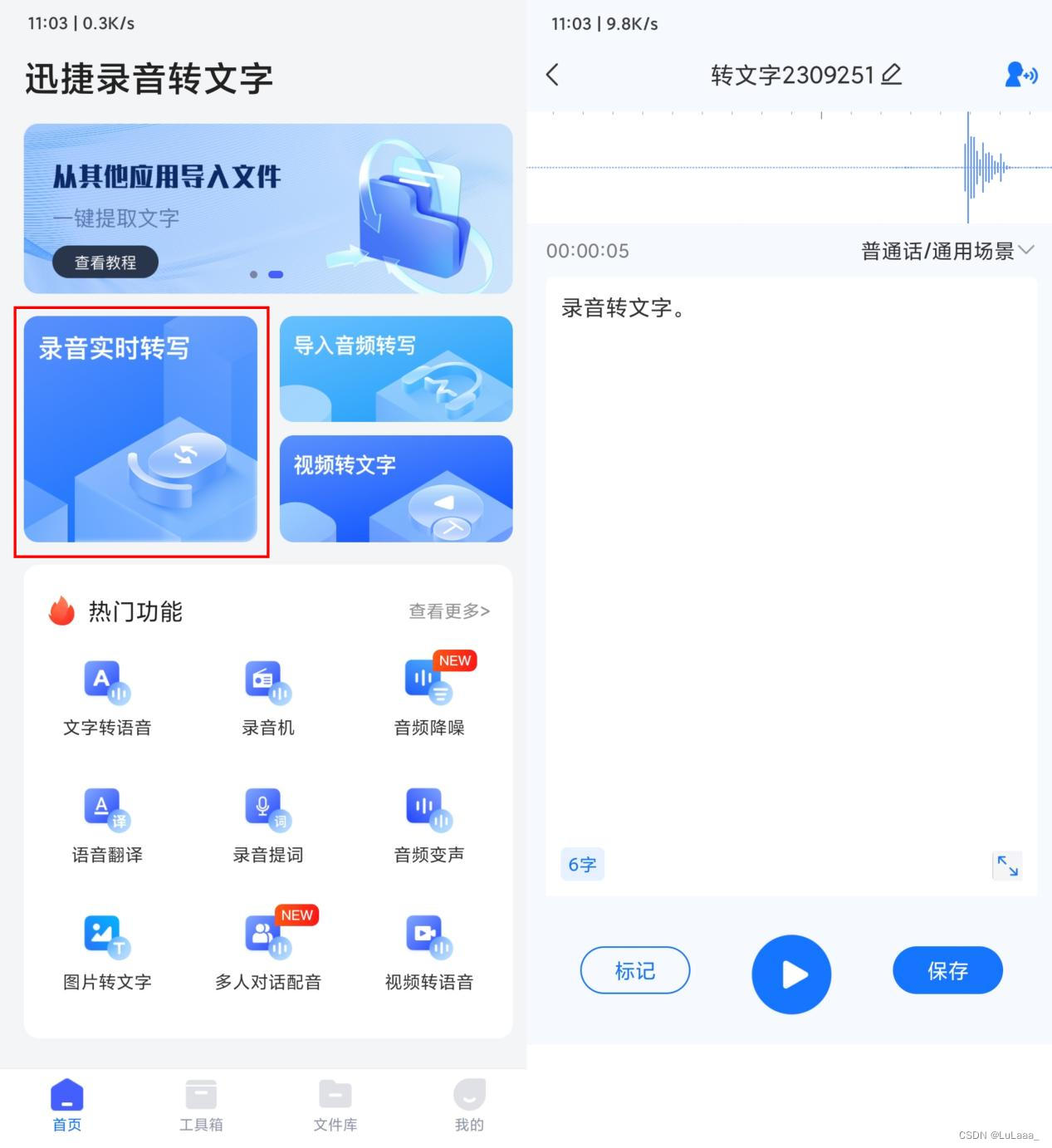
软件介绍:迅捷录音转文字是一款专为语音转写而设计的应用程序。它具备先进的语音识别技术,并结合了实时转写功能,可以将在录音过程中的语音内容实时转换为文字。这意味着你可以在录音时同时查看文本结果,无需等待转录完成。
使用感受:我对这款软件的表现非常满意。它的录音实时转写功能准确率非常高,能够准确识别并转录语音内容。它还提供了编辑和标记功能,使得转录后的文本可以轻松进行修正和调整。这大大提高了我处理语音信息的效率和灵活性。
转录软件2:手机录音机
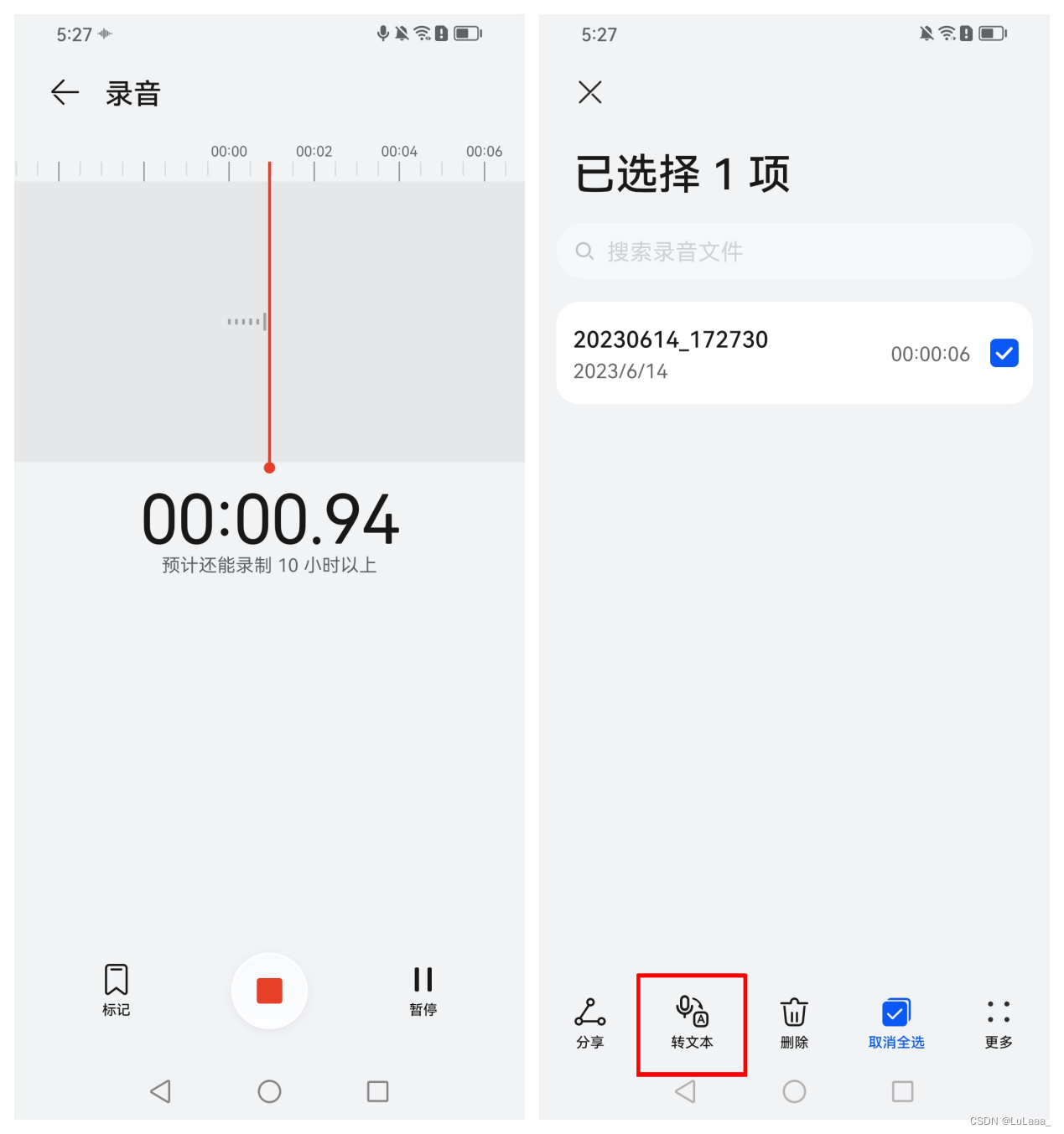
软件介绍:手机录音机是一种非常实用和方便的工具,可以帮助我们记录重要的讲话、会议或其他语音内容。它的录音转文本功能能够将录音内容快速而准确地转换为文字,这对于快节奏的工作环境和学习需求来说,无疑是一个巨大的帮助。
使用感受:我使用这个功能的感受非常良好。手机录音机的操作简单且方便,不需要额外的设备,随时可以记录下重要的语音内容。它的准确度让我印象深刻,转写的结果基本符合我所听到的,减少了我手动抄写的工作量。
转录软件3:AudioLab
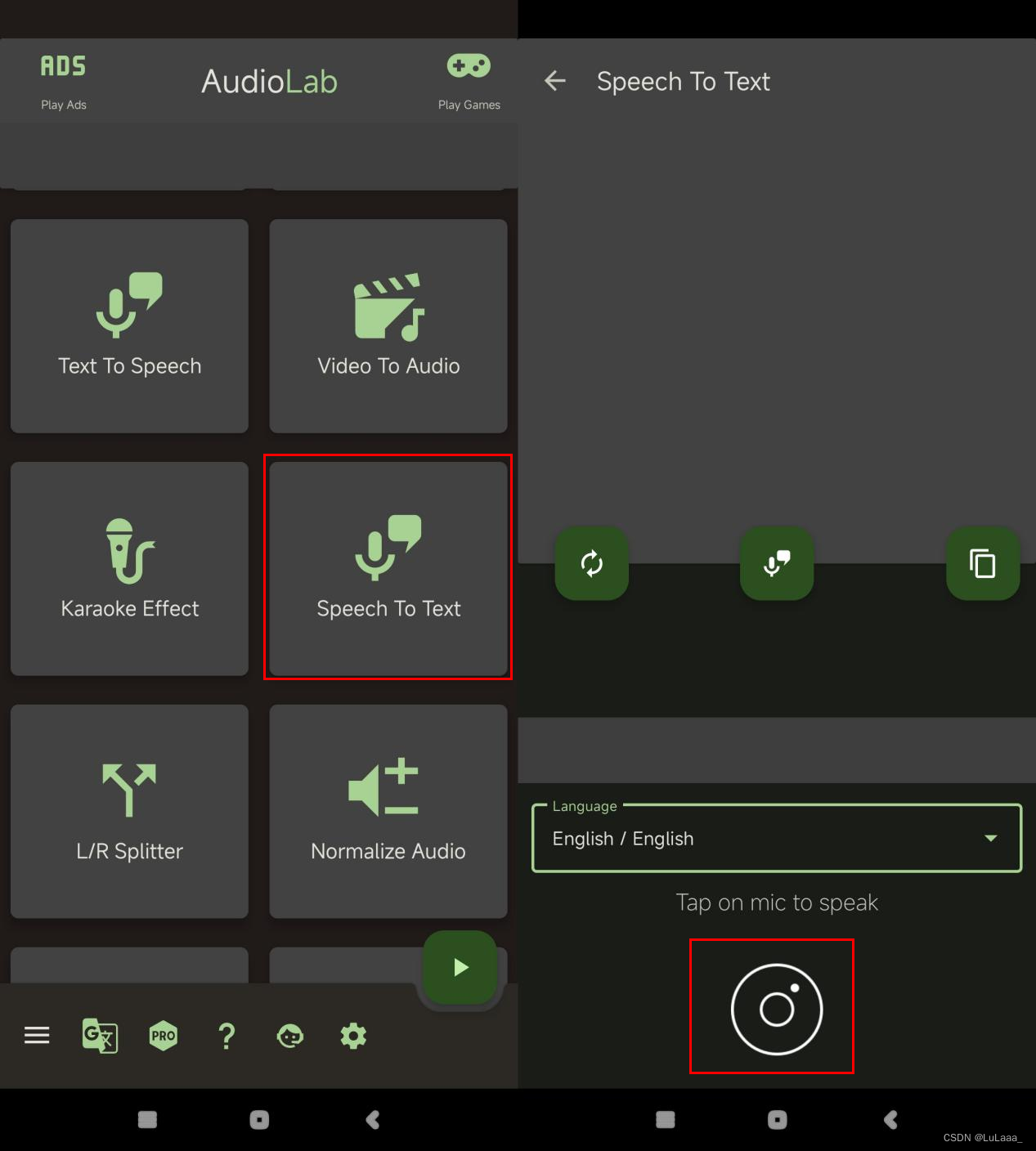
软件介绍:AudioLab是一款备受赞誉的应用程序,它提供了各种各样的功能,其中就包括录音转文字功能。它的录音转文字功能使用先进的语音识别技术,能够将录音文件迅速而准确地转换为文字形式。这项功能具有令人惊叹的准确度,能够识别和转录大部分的语音内容。
使用感受:在我个人使用AudioLab的经验中,我对它的表现非常满意。它的界面设计简洁直观,容易上手。而且,录音质量非常出色,无论是近距离对话还是远距离讲演,都能够保持清晰度和准确度。
无论你是记录会议笔记、整理采访素材还是备课演讲稿,这些录音实时转写软件都能大大地减轻你的负担。从此以后,你再也不必担心错漏听取重要内容,而且编辑和加工文本也变得更加灵活自由。赶快试试看,相信你会被这些先进的录音实时转写软件所深深折服!















 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









