






最近,在复习一些机器学习算法,根据还是要通过归纳总结的方式来梳理,这样思维脉络才能很清晰~
决策树的定义:
决策树的构成——由节点和有向边组成;
节点包括根节点、(中间)内部节点和叶节点。内部节点代表一个特征或属性,叶节点代表一个类别。
决策树图示:

决策树学习的三个步骤:
特征选择、决策树的生成、树的剪枝
(1) 特征选择的标准: 信息增益、信息增益比、 基尼指数、 平方误差最小化;
(2)决策树的生成:根据属性(特征)找到最佳分裂点,将数据分成若干部分,递归执行上述过程,得到尽可能大的树;
(3)剪枝:得到尽可能大的树,对训练集拟合效果好,但存在较大的预测误差,导致过拟合问题,需要进行剪枝。
决策树中的基本概念:
(1)熵:度量了事物的不确定性,事物越不确定,熵越大!表达式如下:
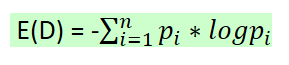
pi——D中取值为i时的概率;
n——D的n种不同的离散取值;
(2)条件熵:如H(D︱A),类似于条件概率,度量D在知道A后剩下的不确定性,表达式如下:
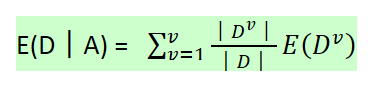
(3)E(D)-E(D|A),它度量了D在知道A以后不确定性减少程度,记为Gain(D,A)。在决策树ID3算法中,叫做信息增益。
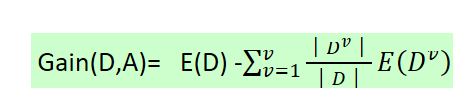
决策树算法的类型——ID3、C4.5、CART
根据不同的特征选择标准和处理的数据类型可分为: 普通决策树 & CART
普通决策树: ID3算法 & C4.5算法
改进过程: ID3——> C4.5 ——> CART
ID3算法:
根据信息增益作为特征选择的标准;
对于每一个特征,计算其信息增益,选择信息增益最大的特征来建立决策树当前的结点;
在此基础上,根据选择的特征的不同取值对数据进行划分,递归上述过程。
ID3的不足:
a) ID3没有考虑连续特征,不能处理连续型特征;
b) ID3采用信息增益大的特征优先建立决策树的节点,而用信息增益作为特征的标准,容易偏向于取值较多的特征;
c) ID3算法对缺失值没有做考虑;
d) 未考虑过拟合问题;
C4.5算法:
根据信息增益比作为特征选择的标准;
信息增益的缺点是比较偏向选择取值较多的属性,为解决该问题,引入信息增益比的概念;
什么是信息增益比?
它是信息增益和特征熵的比值,表达式如下:
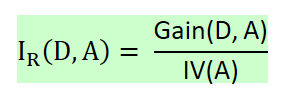
D为样本特征输出的集合,A为样本特征。
什么是特征熵?
其表达式如下所示:
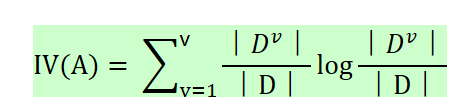
v为特征A中的类别数,??为特征A 中第i个取值对应的样本个数,D为样本个数
特征数越多的特征对应的特征熵越大,它作为分母,可以校正信息增益容易偏向于取值较多的特征的问题。
实例计算:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
17个样本,6个特征,最终2个类别!
以计算特征“色泽”的信息增益为例:
其可能取值——乌黑、青绿、浅白;
D1(色泽=青绿),包括编号为{1,4,6,10,13,17}—— 共6个样本,P1 = 3/6,P2 = 3/6
D2(色泽=乌黑),包括编号为{2,3,7,8,9,15} ——— 共6个样本,P1 = 4/6,P2 = 2/6
D3(色泽=浅白),包括编号为{5,11,12,14,16} ——— 共5个样本,P1 = 1/5,P2 = 4/5

C4.5对ID3的其他改进:
(1)对于ID3不能处理连续特征的问题,C4.5的做法是将连续特征离散化。
具体过程:
取值排序——>取每个相邻的两个取值的值平均——>计算该点作为二分类时的信息增益——>取信息增益最大的点作为连续特征的二元离散分裂点
注意事项——与离散性特征不同的是,如果当前节点为连续属性,则该属性后面还可以参与子节点的产生选择过程。
(2)对于缺失值处理的问题,含有缺失的样本集会导致三个问题:
① 构建树时,分裂属性如何选取?
当训练集中有些样本缺失部分属性,如何计算有缺失值的属性的信息増益率?
② 当已选择某属性作为分裂属性时,样本集根据该属性的值进行分支,但对于那些在该属性上有缺失值的样本,应将它分支到哪一棵子树上?
③ 决策树已构建完成,若待分类样本有些属性值缺失,该样本如何分类?
针对上述三个问题,C4.5算法有多种解决方案:
① 面对问题一,在进行特征选择,计算各属性的信息増益率时,若某些样本的该属性值缺失,则计算时:
a)忽略掉缺失了此属性的样本;
b) 或通过此属性的样本中出现频率最高的属性值,賦值给缺失了此属性的样本。
② 面对问题二,假设已选择属性A作为一分支节点,在对样本集进行分支时,对于那些属性A缺失的样本,则:
a) 忽略这些样本;
b) 或根据属性A的其他样本取值,对未知样本赋值;
c)或为缺失属性A的样本单独创建一个分支;
③ 面对问题三,根据己生成的决策树模型,对一个待分类的样本进行分类时,若此样本的属性A的值未知,可以这样处理:
a)待分类样本在到达属性A的分支结点时即可结束分类过程,此样本所属类别为属性A的子树中概率最大的类别;
b) 或者把待分类样本的属性A赋予一个最常见的值,然后继续分类过程。
(3) 对于ID3的过拟合问题,C4.5进行剪枝操作(ID3不剪枝,得到尽可能大的树)
剪枝包括 预剪枝 和 后剪枝
预剪枝——在决策树生成过程中,对树进行剪枝,提前结束树的分支生长
预剪枝依据:
作为叶结点或作为中间结点进行划分需要包含的最少样本个数:min_samples_leaf 、 min_samples_split
达到决策树的一定层数停止生长: max_depth
结点的经验熵小于某个阈值才停止生长:min_impurity_split
后剪枝——先生成决策树,然后产生所有可能的剪枝后的CART树,再使用交叉验证来检验各种剪枝得效果,选择泛化能力最好的子树
后剪枝的方法包括四种:
(1)悲观错误剪枝(PEP) (Pessimistic Error Pruning);
(2)最小错误剪枝(MEP)(Minimum Error Pruning);
(3)代价复杂度剪枝(CCP)(Cost Complexity Pruning);
(4)基于错误的剪枝(EBP)(Error Based Pruning);
C4.5的剪枝算法选择的是PEP剪枝算法!(悲观错误剪枝)
悲观错误剪枝(PEP) (Pessimistic Error Pruning)

C4.5算法的不足:
(1)C4.5同ID3一样,生成的是多叉树,其运算效率没有二叉树高;
(2)C4.5只能用于分类;
(3)C4.5基于熵进行计算,且有大量对数运算,若有连续特征,还涉及大量排序,十分耗时。
CART(分类回归树):
CART在C4.5的基础上进一步改进!
(1)CART既可用于分类,也可用于回归;
(2)分类树使用基尼系数,回归树使用平方误差;
CART与普通决策树的区别:
(1)普通决策树(ID3,C4.5)——多元切分,CART——二元切分;
(2)特征选择的标准不同:分类树使用基尼系数,回归树使用平方误差,ID3使用信息增益,C4.5使用信息增益比;
CART分类树算法:
使用基尼系数作为特征选择的算法;
基尼系数——代表了模型的不纯度,基尼系数越小,不纯度越低,特征越好!
基尼系数的表达公式:
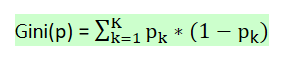
对于样本D,根据特征A的某个值a,把样本D分成两个部分D1和D2,则在特征A 的条件下,D的基尼系数为:
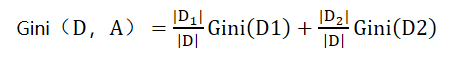
(1)CART分类树对连续特征的处理:
和C4.5相同,区别仅在于,选择划分点时,分类树采用基尼系数,而C4.5采用信息增益;
注意——如果当前节点为连续属性,则该属性后面还可以参与子节点的产生选择过程;
(2)CART分类树对离散特征的处理:
以特征A 为例,假设他有A1,A2,A3三种类别。
CART分类树会考虑把A分成{A1}和{A2,A3},{A2}和{A1,A3},{A3}和{A1,A2}三种情况,找到基尼系数最小的组合,比如{A2}和{A1,A3},然后建立二叉树节点,同时,由于没有把特征A的取值完全分开,该离散特征有机会在子节点继续选择到特征A来划分A1和A3。
注意——这和ID3或者C4.5不同,在ID3或者C4.5的一棵子树中,离散特征只会参与一次节点的建立。
CART回归树算法:
使用平方误差最小化作为特征选择的算法;
对于CART分类树,采用基尼系数大小度量特征各划分点的优劣;
对于CART回归树,通过计算任意划分成的数据集的各自的均方差,使两部分的均方差各自最小,同时两者之和最小来判断特征划分点的优劣,
表达式如下:
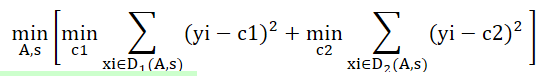
其中,c1和c2为划分后的样本集的均值。
CART树算法的剪枝:
CART树的剪枝采用的办法是后剪枝法!
CART树使用CCP剪枝法(代价复杂度剪枝)!
代价复杂度剪枝算法(CCP):
- 权衡利弊——希望减少树的大小防止过拟合,又担心去掉一些节点后预测误差增大;
- 定义损失函数:
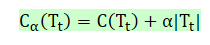
Tt表内部任一节点t的子树;
C(Tt)为子树的预测误差;
??为子树 ?的叶子节点个数
?权衡拟合程度与树的复杂度。
当α=0时,原始生成的CART树即为最优子树;
当α=∞时,由原始生成的CART树的根节点组成的单节点树为最优子树。
如何找到最合适的α?
将α从0取到正无穷,对于每一个固定的α,我们都可以找到使得Cα(T)最小的最优子树T(α)
剪枝的两个步骤:
(1)生成子树序列
每次剪枝剪的只是某个内部节点的子节点,将该内部节点作为叶子节点;
此时,计算整体损失函数时,该节点外的值均保持不变,仅该节点的局部损失发生改变,
因此,只需要计算该节点剪枝前和剪枝后的损失函数。

注意:这里的节点t为变量,而推α时,t为某一特定的t!
g(t) ——表示剪枝后整体损失函数减少的程度;
根据g(t)的大小,我们选择剪切g(t)最小的Tt。
通过这种方式生成一个子树序列 {T0, T1 , T2, …. , Tm },
T0代表最初充分生长的树,Tm代表根节点树。
(2)交叉验证法在子树序列中选取最优子树
将独立测试集放入每一颗子树中进行测试,计算每颗子树的整体的损失函数,选择损失函数最小的子树作为最优子树~
CART的不足:
(1)无论是ID3, C4.5还是CART,做特征选择时,都是选择最优的一个特征来做分类决策,但大多数情况下,分类决策不应由某一个特征决定,而是应由一组特征决定的;
(2)如果样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习里的随机森林之类的方法解决。
三种决策树类型的小结:
| 算法 | 支持模型 | 树结构 | 特征选择 | 连续值处理 | 缺失值处理 | 剪枝 | 剪枝方法 |
| ID3 | 分类 | 多叉树 | 信息增益 | 不支持 | 不支持 | 不支持 | ----------------- |
| C4.5 | 分类 | 多叉树 | 信息增益比 | 支持 | 支持 | 支持 | 悲观错误剪枝(通过伯努利分布的期望和标准差) |
| CART | 分类,回归 | 二叉树 | 基尼系数,均方差 | 支持 | 支持 | 支持 | 代价复杂度剪枝(通过定义损失函数) |















 2511
2511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









