







 本文介绍了决策树模型中的ID3、C4.5和CART算法,包括信息熵、信息增益、信息增益率和基尼系数等概念。ID3算法易偏向取值较多的特征,C4.5通过信息增益率改进此问题,而CART算法使用基尼系数并能处理回归问题。
本文介绍了决策树模型中的ID3、C4.5和CART算法,包括信息熵、信息增益、信息增益率和基尼系数等概念。ID3算法易偏向取值较多的特征,C4.5通过信息增益率改进此问题,而CART算法使用基尼系数并能处理回归问题。
决策树模型是一种常用的有监督的学习模型,其主要用来解决分类问题,但是也可用来解决回归问题。
信息熵和信息增益
我们先来了解两个概念,信息熵与信息增益。
信息熵
信息熵用来表示事物的不确定性或不纯性,信息熵越大,则表示该事物的不确定性或不纯性越大。
信息熵的公式为: H ( x ) = − ∑ i = 1 n p i l o g p i H(x)=-\sum_{i=1}^{n}p_ilogp_i H(x)=−∑i=1npilogpi
举个例子:有两个集合,A集合[1,1,1,1,1,1,3],B集合[1,2,3,4,5,6,7],显然A集合的熵值要比B集合小得多,因为A集合只有两类,B集合有七类,相对来说A集合的不确定性要比B集合小,因此A集合的熵值更小。同样,我们在进行分类问题时,也希望通过节点分类后,数据的不确定性变小。
信息增益
简单来说,信息增益就是熵值变化的大小,即一个特征带来的熵值变化。
信息增益公式: I ( x , y ) = H ( x ) − H ( x ∣ y ) I(x,y)=H(x)-H(x|y) I(x,y)=H(x)−H(x∣y)
信息熵和信息增益计算方法:
举个例子:
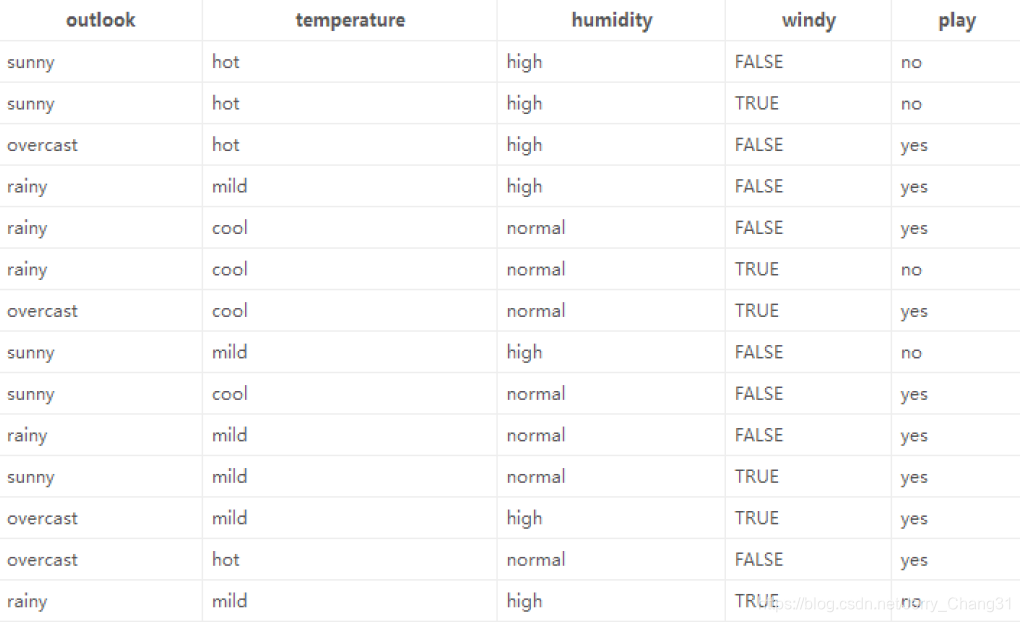
这是一份一个同学这14天打球的情况,其中“play”是标签,其他是特征。在分裂之前,14天中,有9天打球,5天不打球,所以,此时的熵值为:
− 9 14 l o g 2 9 14 − 5 14 l o g 2 5 14 = 0.940 -\frac{9}{14}log_2\frac{9}{14}-\frac{5}{14}log_2\frac{5}{14}=0.940 −149log2149−145log2<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









