






Hadoop生态圈
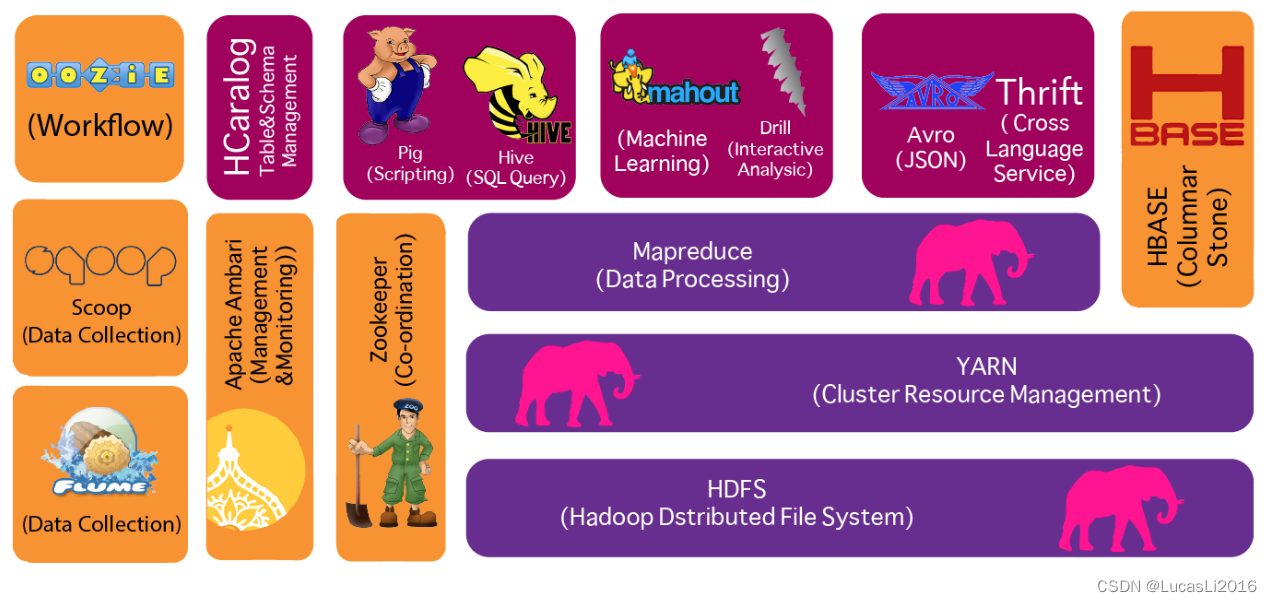
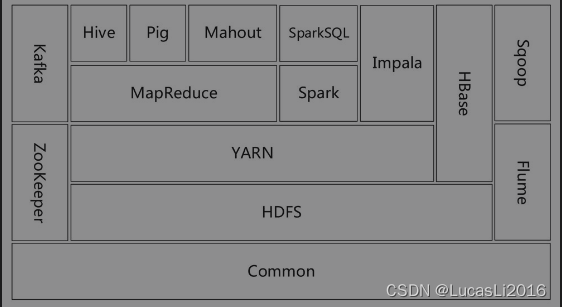
一般来说,狭义的Hadoop仅代表了Common、HDFS、YARN和MapReduce模块。但是开源世界的创造力是无穷的,围绕Hadoop有越来越多的软件蓬勃出现,方兴未艾,构成了一个生机勃勃的Hadoop生态圈。在特定场景下,Hadoop有时也指代Hadoop生态圈
Hadoop Common
是Hadoop体系最底层的一个模块,为Hadoop各子项目提供各种工具,如系统配置工具Configuration、远程过程调用RPC、序列化机制和日志操作等,是其他模块的基础。
HDFS
(Hadoop Distributed File System, Hadoop分布式文件系统)是Hadoop的基石。HDFS是一个具有高度容错性的文件系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
YARN
(Yet Another Resource Negotiator,另一种资源协调器)是统一资源管理和调度平台,它解决了上一代Hadoop资源利用率低和不能兼容异构的计算框架等多种问题。它提供了资源隔离方案和双调度器的实现。
MapReduce
是一种编程模型,利用函数式编程的思想,将对数据集处理的过程分为Map和Reduce两个阶段。MapReduce的这种编程模型非常适合进行分布式计算。Hadoop提供了MapReduce的计算框架,实现了这种编程模型,用户可以通过Java、C++、Python、PHP等多种语言进行编程。
Spark
是加州伯克利大学AMP实验室开发的新一代计算框架,对迭代计算很有优势,和MapReduce计算框架相比性能提升明显,并且都可以与YARN进行集成,Spark也提供支持SQL的组件SparkSQL等。
HBase
来源于谷歌的Bigtable论文,HBase是一个分布式的、面向列族的开源数据库。采用了Bigtable的数据模型——列族。HBase擅长大规模数据的随机、实时读写访问。在所有分布式系统中,都需要考虑一致性的问题,ZooKeeper作为一个分布式的服务框架,基于Fast Paxos算法,解决了分布式系统中一致性的问题。ZooKeeper提供了配置维护、名字服务、分布式同步、组服务等。
Hive
最早是由Facebook开发并使用,是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,提供简单的SQL查询功能,并将SQL语句转换为MapReduce作业运行。其优点是学习成本低,对于常见的数据分析需求不必开发专门的MapReduce作业,十分适合大规模数据统计分析。Hive对于Hadoop来说是非常重要的模块,大大降低了Hadoop的使用门槛。
Pig
和Hive类似,也是对大型数据集进行分析和评估的工具,不过与Hive提供SQL接口不同的是,它提供了一种高层的、面向领域的抽象语言:Pig Latin, Pig也可以将Pig Latin脚本转化为MapReduce作业。与SQL相比,Pig Latin更加灵活,但学习成本稍高。
Impala
由Cloudera公司开发,可以对存储在HDFS、HBase的海量数据提供交互式查询的SQL接口。除了和Hive使用相同的统一存储平台,Impala也使用相同的元数据、SQL语法、ODBC驱动程序和用户界面。Impala还提供了一个熟悉的面向批量或实时查询的统一平台。Impala的特点是查询非常迅速,其性能大幅领先于Hive。Impala并没有基于MapReduce的计算框架,这也是Impala可以大幅领先Hive的原因,Impala的定位是OLAP,是Google的新三驾马车之一Dremel的开源实现。
Mahout
是一个机器学习和数据挖掘库,它利用MapReduce编程模型实现了k-means、Native Bayes、Collaborative Filtering等经典的机器学习算法,并使其具有良好的可扩展性。
Flume
是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Sqoop
是SQL to Hadoop的缩写,主要作用在于在结构化的数据存储(关系型数据库)与Hadoop之间进行数据双向交换。也就是说,Sqoop可以将关系型数据库(如MySQL、Oracle等)的数据导入到Hadoop的HDFS、Hive,也可以将HDFS、Hive的数据导出到关系型数据库中。Sqoop充分利用了Hadoop的优点,整个导出导入都是由MapReduce计算框架实现并行化,非常高效。
Kafka
是一种高吞吐量的分布式发布订阅消息系统,具有分布式、高可用的特性,在大数据系统里面被广泛使用,如果把大数据平台比作一台机器的话,那么Kafka这种消息中间件就类似于前端总线,它连接了平台里面的各个组件。















 9330
9330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









