






在前两篇文章中,我们介绍了网络爬虫的基本概念和HTML的结构。有了这些基础知识,现在我们可以开始编写自己的第一个爬虫程序了。本文将带你一步步了解爬虫程序的基本结构、必要的组件以及一个简单实用的爬虫模板,帮助你快速入门爬虫开发。
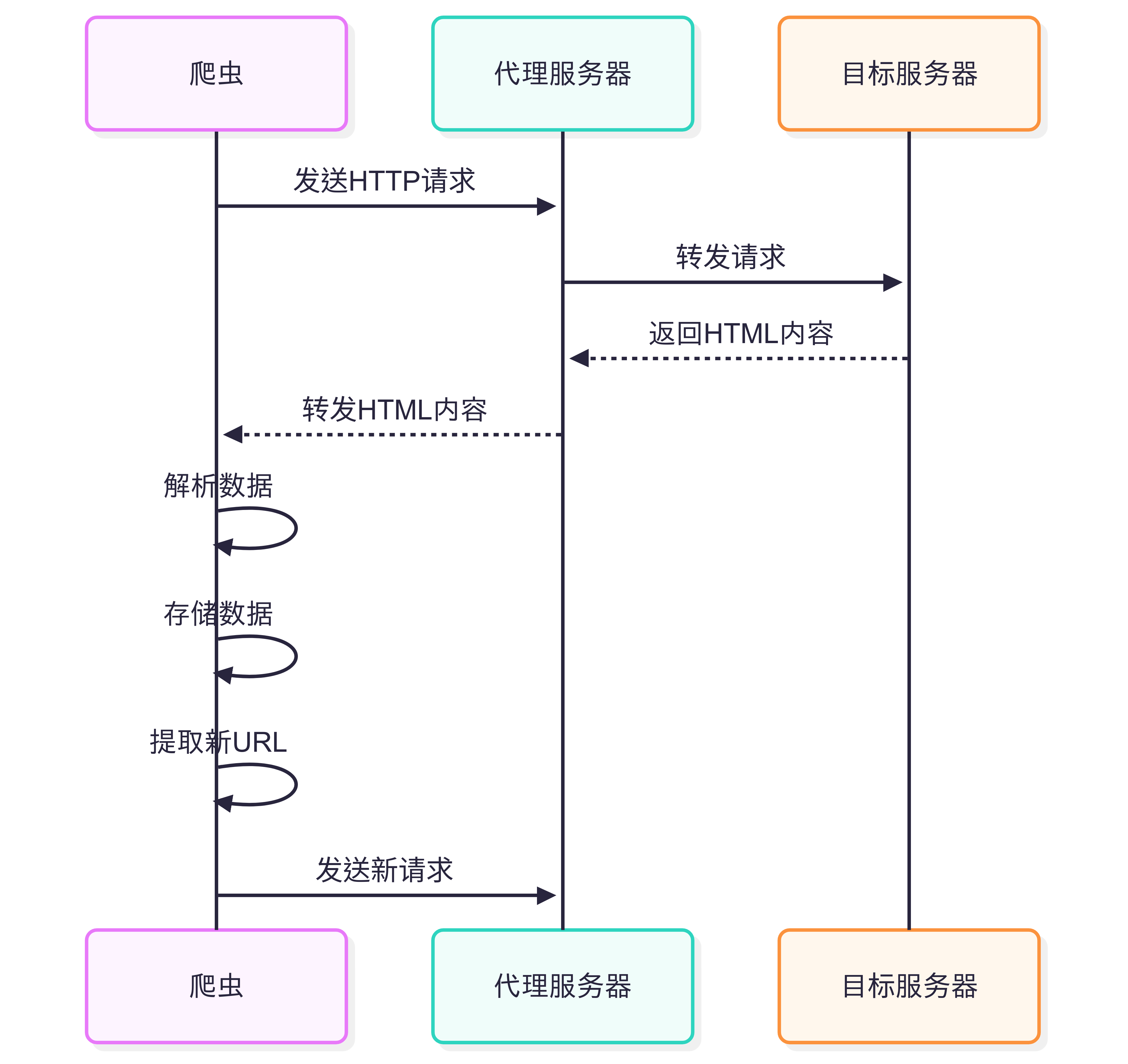
一、爬虫程序的基本流程
一个典型的爬虫程序通常包含以下几个步骤:
- 发送HTTP请求:向目标网站发送请求获取网页内容
- 接收服务器响应:接收并处理服务器返回的数据
- 解析HTML内容:从响应中提取出HTML,并进行解析
- 提取有用数据:从解析后的HTML中提取需要的信息
- 数据存储:将提取的数据保存到文件或数据库中
二、准备工作:安装必要的库
在开始编写爬虫之前,我们需要安装最基本的爬虫库——Requests。它是Python中最流行的HTTP库,设计简洁且功能强大,非常适合初学者。
pip install requests
如果你已经安装了Python,可以直接在命令行中运行上面的命令来安装Requests库。
三、最简单的爬虫示例
让我们从最简单的例子开始,爬取一个网页并打印其内容:
import requests
# 发送GET请求获取网页内容
url = "https://www.example.com"
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 输出网页内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
这段代码的工作流程是:
- 导入requests库
- 定义目标URL
- 使用
requests.get()方法发送GET请求 - 检查响应状态码是否为200(表示请求成功)
- 如果成功,打印网页内容;否则,打印错误信息
四、HTTP请求头与Cookie
在实际爬取过程中,很多网站会检查请求头信息,特别是User-Agent(用户代理),以确定请求来源。如果不设置适当的请求头,网站可能会拒绝我们的请求或返回不同的内容。
1. 添加请求头(Headers)
import requests
url = "https://www.example.com"
# 定义请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8"
}
# 发送带有请求头的GET请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
print("请求成功!")
# 仅打印内容前100个字符
print(response.text[:100] + "...")
else:
print(f"请求失败,状态码:{response.status_code}")
常用的请求头字段及其作用:
- User-Agent:标识请求的浏览器类型和操作系统信息
- Accept:指定客户端能够接收的内容类型
- Accept-Language:指定客户端能够接收的语言
- Referer:指定请求来源页面的URL,有些网站会验证这个字段
- Connection:指定与服务器的连接类型(如keep-alive或close)
2. 使用Cookie
有些网站需要Cookie来维持会话状态或验证身份。以下是使用Cookie的简单示例:
import requests
url = "https://www.example.com/user-profile"
# 手动设置Cookie
cookies = {
"session_id": "abc123",
"user_token": "xyz789"
}
# 方法1:在请求中直接传入cookies参数
response = requests.get(url, cookies=cookies)
# 方法2:创建会话对象并设置Cookie
session = requests.Session()
session.cookies.update(cookies)
response = session.get(url)
print(response.text[:100] + "...")
3. 使用会话(Session)保持状态
如果需要在多个请求之间保持状态(如登录会话),可以使用Session对象:
import requests
# 创建会话对象
session = requests.Session()
# 设置会话级别的请求头
session.headers.update({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/91.0.4472.124"
})
# 登录
login_url = "https://www.example.com/login"
login_data = {
"username": "your_username",
"password": "your_password"
}
login_response = session.post(login_url, data=login_data)
# 使用同一会话访问需要登录的页面
profile_url = "https://www.example.com/profile"
profile_response = session.get(profile_url)
print(profile_response.text[:100] + "...")
五、处理不同类型的请求
1. GET请求(获取数据)
GET请求通常用于从服务器获取数据,可以通过URL参数传递数据:
import requests
# 不带参数的GET请求
response = requests.get("https://www.example.com")
# 带参数的GET请求
params = {
"q": "python爬虫",
"page": 1
}
response = requests.get("https://www.example.com/search", params=params)
# 上面的请求等同于访问:https://www.example.com/search?q=python爬虫&page=1
print(response.url) # 打印完整URL
2. POST请求(提交数据)
POST请求通常用于向服务器提交数据,如表单提交:
import requests
# 提交表单数据
form_data = {
"username": "test_user",
"email": "test@example.com",
"message": "Hello World!"
}
response = requests.post("https://www.example.com/submit", data=form_data)
print(response.text)
# 提交JSON数据
json_data = {
"name": "Test Product",
"price": 99.99,
"available": True
}
response = requests.post("https://www.example.com/api/products", json=json_data)
print(response.json()) # 如果响应是JSON格式,可以直接解析
六、一个实用的爬虫模板
下面是一个实用的爬虫模板,包含了基本的错误处理和重试机制:
import requests
import time
import random
import logging
from requests.exceptions import RequestException
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s'
)
def fetch_page(url, headers=None, cookies=None, max_retries=3, timeout=10):
"""
获取网页内容的函数,包含重试机制
参数:
url (str): 要爬取的URL
headers (dict): 请求头
cookies (dict): Cookie
max_retries (int): 最大重试次数
timeout (int): 请求超时时间(秒)
返回:
response对象 或 None(如果请求失败)
"""
# 默认请求头
if headers is None:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/91.0.4472.124 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
# 重试机制
for attempt in range(max_retries):
try:
logging.info(f"正在获取页面: {url}")
response = requests.get(
url,
headers=headers,
cookies=cookies,
timeout=timeout
)
# 检查响应状态
if response.status_code == 200:
return response
else:
logging.warning(f"请求失败,状态码: {response.status_code}")
except RequestException as e:
logging.error(f"请求异常: {e}")
# 如果不是最后一次重试,则等待后继续
if attempt < max_retries - 1:
# 随机等待1-3秒
sleep_time = 1 + random.random() * 2
logging.info(f"等待 {sleep_time:.1f} 秒后重试...")
time.sleep(sleep_time)
logging.error(f"已达到最大重试次数 {max_retries},获取页面失败")
return None
def save_to_file(content, filename):
"""保存内容到文件"""
try:
with open(filename, 'w', encoding='utf-8') as f:
f.write(content)
logging.info(f"内容已保存到文件: {filename}")
return True
except Exception as e:
logging.error(f"保存文件时出错: {e}")
return False
def main():
# 目标网页URL
url = "https://www.example.com"
# 获取页面内容
response = fetch_page(url)
if response:
# 保存页面内容
save_to_file(response.text, "example_page.html")
# 这里可以添加解析页面内容的代码
# 在下一篇文章中我们将使用解析库来提取数据
logging.info("爬取任务完成")
else:
logging.error("爬取失败")
if __name__ == "__main__":
main()
这个模板包含:
- 基本的请求发送函数,带有重试机制
- 错误处理和日志记录
- 随机延迟,避免请求过于频繁
- 文件保存功能
- 主函数结构
七、常见问题与解决方案
1. 请求被拒绝(403 Forbidden)
可能原因:网站检测到爬虫行为或缺少必要的请求头。
解决方案:
- 添加或修改User-Agent等请求头
- 降低请求频率,添加随机延迟
- 使用代理IP(进阶方法,本文不详述)
2. 超时错误
可能原因:网络连接不稳定或服务器响应慢。
解决方案:
- 增加超时时间
- 实现重试机制
- 检查网络连接
3. 网站需要登录
可能原因:内容只对已登录用户可见。
解决方案:
- 使用Session对象和模拟登录
- 手动获取并设置Cookie
八、实际案例:爬取百度热搜榜
最后,让我们用一个实际案例来展示如何使用上述知识爬取百度热搜榜:
import requests
import time
import logging
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
def get_baidu_hot_search():
"""获取百度热搜榜"""
url = "https://top.baidu.com/board?tab=realtime"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/91.0.4472.124 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8"
}
try:
logging.info("开始获取百度热搜榜...")
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
logging.info("获取成功!")
# 将响应内容保存到文件中
with open("baidu_hot_search.html", "w", encoding="utf-8") as f:
f.write(response.text)
logging.info("已保存热搜页面HTML到baidu_hot_search.html")
return response.text
else:
logging.error(f"请求失败,状态码:{response.status_code}")
return None
except Exception as e:
logging.error(f"获取百度热搜时出错: {e}")
return None
if __name__ == "__main__":
content = get_baidu_hot_search()
if content:
logging.info("爬取完成!在下一篇文章中,我们将学习如何解析这个页面的HTML内容并提取热搜榜数据。")
else:
logging.error("爬取失败!")
这个案例展示了如何使用请求头来模拟浏览器访问百度热搜榜,并将获取到的HTML内容保存到文件中。在下一篇文章中,我们将学习如何使用解析库(如BeautifulSoup)来提取这个HTML中的热搜榜数据。
九、总结与注意事项
本文介绍了编写第一个爬虫程序的基本步骤:
- 准备环境:安装requests库
- 发送请求:使用GET或POST方法获取网页内容
- 设置请求头和Cookie:模拟真实浏览器行为
- 错误处理与重试:处理可能出现的网络问题
- 保存数据:将获取的内容保存到文件中
在编写爬虫时,需要注意以下几点:
- 尊重网站规则:查看并遵守robots.txt文件
- 控制请求频率:避免频繁请求对服务器造成负担
- 异常处理:妥善处理可能出现的各种错误
- 模拟真实用户:设置合理的请求头和Cookie
- 代码可维护性:编写清晰、结构化的代码
通过本文的学习,你应该已经掌握了编写一个基本爬虫的方法。在下一篇文章中,我们将介绍如何使用BeautifulSoup等解析库,从HTML中提取所需的数据。
下一篇:【Python爬虫详解】第四篇:使用解析库提取网页数据


















 63万+
63万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











