







文章目录
第2章 算法基础
2.1 插入排序(Insertion sort)
输入: n n n个数的序列 < a 1 , a 2 , ⋯ , a n > <a_1,a_2,\cdots,a_n> <a1,a2,⋯,an>
输出:输入序列的一个排列 < a 1 ′ , a 2 ′ , ⋯ , a n ′ > <a_1^{'},a_2^{'},\cdots,a_n^{'}> <a1′,a2′,⋯,an′>,满足 a 1 ′ ≤ a 2 ′ ≤ ⋯ ≤ a n ′ a_1^{'} \le a_2^{'} \le \cdots \le a_n^{'} a1′≤a2′≤⋯≤an′
被排序的数称为关键字。在本书中,使用**伪代码(pseudocode)**对算法进行描述。
对于少量元素的排序,插入排序是一个有效的算法。插入排序的工作方式类似于排序扑克牌。

每次右手从桌子上拿一张扑克牌插入到左手中正确的位置,为了找到一张牌的准确位置,需要从右向左将它与在手中的每张牌进行比较。

#include <iostream>
#include <vector>
void insertion_sort(std::vector<int> &array) {
for (int j = 1; j < array.size(); j++) {
int key = array.at(j);
int i = j - 1;
while (i >= 0 && array[i] > key) {
array[i + 1] = array[i];
i--;
}
array[i + 1] = key;
}
}
int main(void) {
std::vector<int> array = {5, 2, 4, 6, 1, 3};
insertion_sort(array);
for (int elem: array) {
std::cout << elem << " ";
}
return 0;
}
import java.util.Arrays;
public class InsertionSort {
public static void insertionSort(int[] A) {
for (int j = 1; j < A.length; j++) {
int key = A[j];
int i = j - 1;
while (i >= 0 && A[i] > key) {
A[i+1] = A[i];
i--;
}
A[i+1] = key;
}
}
public static void main(String[] args) {
int[] array = {5, 2, 4, 6, 1, 3};
InsertionSort.insertionSort(array);
System.out.println(Arrays.toString(array));
}
}
循环不变式与插入排序的正确性
循环不变式主要用来帮助我们理解算法的正确性。关于循环不变式,必须证明三条性质:
- 初始化(Initialization):循环第一次迭代之前,循环不变式为真
- 保持(Maintenance):如果循环的某次迭代之前它为真,那么下次迭代之前它仍为真
- 终止(Termination):在循环终止时,不变式返回正确的结果,并且能够证明算法的正确性。
2.2 分析算法(Analyzing algorithms)
分析算法的模型:单处理器计算模型——随机访问机,random-access machine (RAM)。
在RAM模型中,指令一个接一个地执行,没有并发操作。RAM模型假设每个指令与任何其他指令所花费的时间相同,并且每个数据访问,使用一个变量的值或存储到一个变量中,所花费的时间与任何其他数据访问相同。
插入排序算法时间分析
影响时间的因素:
- 输入规模(size)
- 输入数据分布

该算法的运行时间是执行每条语句的运行时间之和:
T ( n ) = c 1 n + c 2 ( n − 1 ) + c 4 ( n − 1 ) + c 5 ∑ i = 2 n t i + c 6 ∑ i = 2 n ( t i − 1 ) + c 7 ∑ i = 2 n ( t i − 1 ) + c 8 ( n − 1 ) T(n)=c_1n+c_2(n-1)+c_4(n-1)+c_5\sum_{i=2}^nt_i+c_6\sum_{i=2}^n(t_i-1)+c_7\sum_{i=2}^n(t_i-1)+c_8(n-1) T(n)=c1n+c2(n−1)+c4(n−1)+c5i=2∑nti+c6i=2∑n(ti−1)+c7i=2∑n(ti−1)+c8(n−1)
在INSERTION-SORT中,若输入数组已排好序,则出现最佳情况。这时,对于每个 i = 2 , 3 , . . . , n i=2,3,...,n i=2,3,...,n,我们发现在第5行,恒有 A [ j ] ≤ k e y A[j] \le key A[j]≤key,从而对 i = 2 , 3 , ⋯ , n i=2,3,\cdots,n i=2,3,⋯,n,有 t i = 1 t_i=1 ti=1,该最佳情况的运行时间为:
T ( n ) = c 1 n + c 2 ( n − 1 ) + c 4 ( n − 1 ) + c 5 ( n − 1 ) + c 8 ( n − 1 ) = ( c 1 + c 2 + c 4 + c 5 + c 8 ) n − ( c 2 + c 4 + c 5 + c 8 ) T(n)=c_1n+c_2(n-1)+c_4(n-1)+c_5(n-1)+c_8(n-1)=(c_1+c_2+c_4+c_5+c_8)n-(c_2+c_4+c_5+c_8) T(n)=c1n+c2(n−1)+c4(n−1)+c5(n−1)+c8(n−1)=(c1+c2+c4+c5+c8)n−(c2+c4+c5+c8)
可以把运行时间表示为 a n + b an+b an+b,其中常量 a a a和 b b b依赖与语句代价 c i c_i ci。因此它是 n n n的线性函数。
若数组已反向排好序,则导致最坏情况。我们必须将元素 A [ i ] A[i] A[i]与整个已排序的子数组 A [ 1.. i − 1 ] A[1..i-1] A[1..i−1]中的每个元素进行比较,所以对 i = 2 , 3 , ⋯ , n i=2,3,\cdots,n i=2,3,⋯,n,有 t i = i t_i=i ti=i。注意到
∑ i = 2 n i = n ( n + 1 ) 2 − 1 \sum_{i=2}^{n}i=\frac{n(n+1)}{2}-1 i=2∑ni=2n(n+1)−1
∑ i = 2 n ( i − 1 ) = n ( n − 1 ) 2 \sum_{i=2}^{n}(i-1)=\frac{n(n-1)}{2} i=2∑n(i−1)=2n(n−1)
因此,最坏运行时间为
T ( n ) = c 1 n + c 2 ( n − 1 ) + c 4 ( n − 1 ) + c 5 ( n ( n + 1 ) 2 − 1 ) + c 6 ( n ( n − 1 ) 2 ) + c 7 ( n ( n − 1 ) 2 ) + c 8 ( n − 1 ) = ( c 5 2 + c 6 2 + c 7 2 ) n 2 + ( c 1 + c 2 + c 4 + c 5 2 − c 6 2 − c 7 2 + c 8 ) n − ( c 2 + c 4 + c 5 + c 8 ) T(n)=c_1n+c_2(n-1)+c_4(n-1)+c_5(\frac{n(n+1)}{2}-1)+c_6(\frac{n(n-1)}{2})+c_7(\frac{n(n-1)}{2})+c_8(n-1)=(\frac{c_5}{2}+\frac{c_6}{2}+\frac{c_7}{2})n^2+(c_1+c_2+c_4+\frac{c_5}{2}-\frac{c_6}{2}-\frac{c_7}{2}+c_8)n-(c_2+c_4+c_5+c_8) T(n)=c1n+c2(n−1)+c4(n−1)+c5(2n(n+1)−1)+c6(2n(n−1))+c7(2n(n−1))+c8(n−1)=(2c5+2c6+2c7)n2+(c1+c2+c4+2c5−2c6−2c7+c8)n−(c2+c4+c5+c8)
可以把最坏运行时间表示为 a n 2 + b n + c an^2+bn+c an2+bn+c,其中常量 a a a、 b b b和 c c c又依赖于语句代价 c i c_i ci。因此它是 n n n的二次函数。
最坏情况与平均情况分析
为什么往往只集中于求最坏情况的运行时间?
- 一个算法的最坏情况运行时间给出了任何输入的运行时间的一个上界。知道了这个界,就能确保该算法绝不需要更长的时间。
- 对于某些算法,最坏情况经常出现。例如,在数据库中检索某一条信息时,数据库中不存在这条信息。这样对缺失信息的检索可能是频繁的。
- “平均情况”往往与最坏情况大致一样差。
2.3 设计算法
插入排序使用了增量方法:在子数组 A [ 1.. j − 1 ] A[1..j-1] A[1..j−1]有序后,将单个元素 A [ j ] A[j] A[j]插入子数组的适当位置,产生排好序的子数组 A [ 1.. j ] A[1..j] A[1..j]。
2.3.1 分治法
分治法(divide-and-conquer method)思想:将原问题分解(divide)为几个规模较小但类似于原问题的子问题,递归的(recursive)求解这些子问题,然后再合并(combine)这些子问题的解来建立原问题的解。
分治法每层递归的三步骤(以归并排序算法为例):
- 分解(Divide):将原问题分解为若干子问题,这些子问题是与原问题相似的规模较小的实例。
- 分解待排序的 n n n个元素的序列为2个包含 n 2 \frac{n}{2} 2n个元素的子序列。
- 解决(Conquer):递归的求解这些子问题。当子问题的规模足够小,则直接求解。
- 使用归并排序递归的排序两个子序列。
- 合并(Combine):将子问题的解合并为原问题的解。
- 合并两个已排序的子序列得到原序列的排序结果。


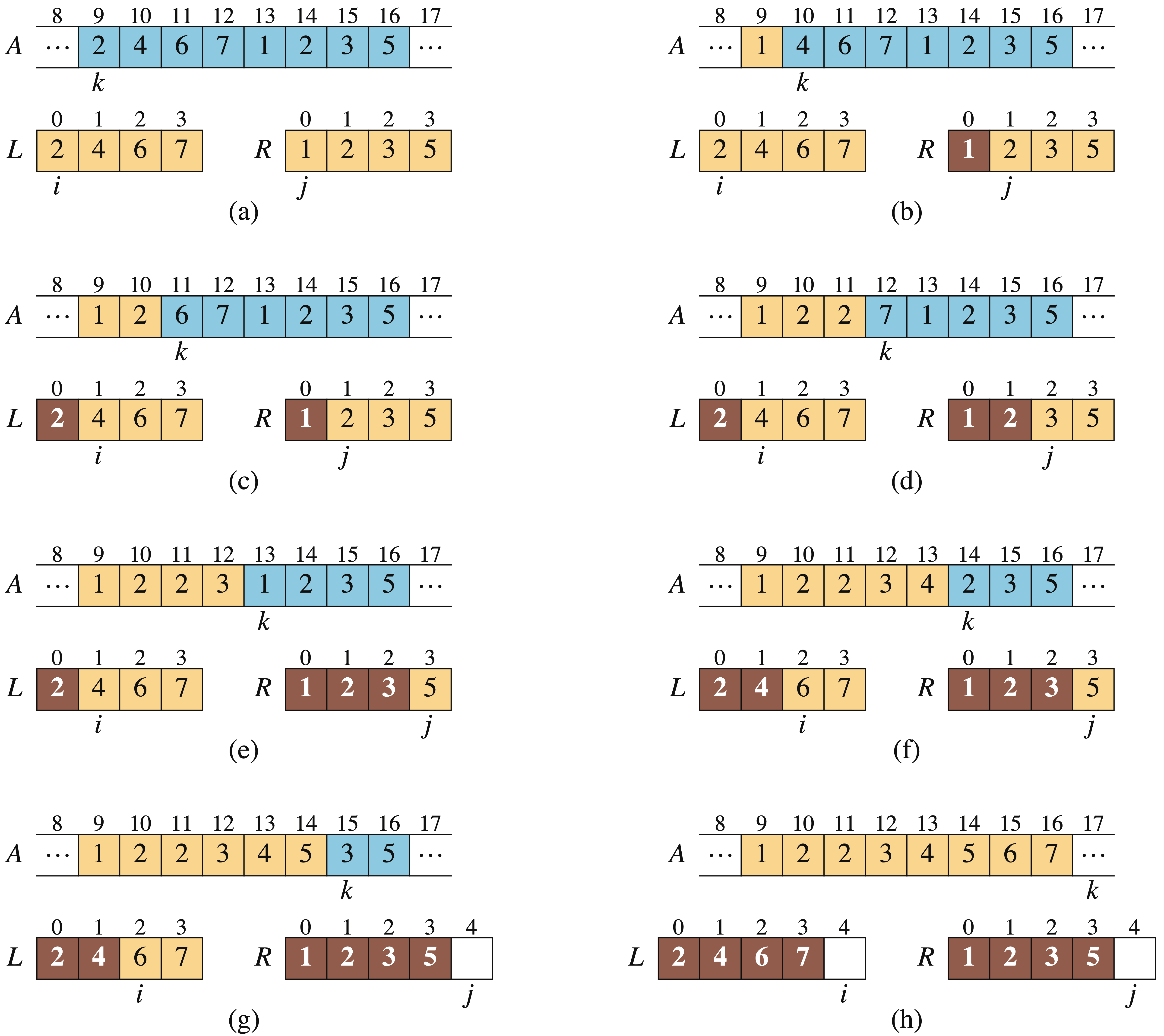
import java.util.Arrays;
public class MergeSort {
public static void mergeSort(int[] A, int p, int r) {
if (p < r) {
int q = (int) Math.floor((p + r) / 2);
mergeSort(A, p, q);
mergeSort(A, q + 1, r);
merge(A, p, q, r);
}
}
public static void merge(int[] A, int p, int q, int r) {
int lLength = q - p + 1; // 数组A[p..q]的长度
int rLength = r - q; // 数组A[q+1..r]的长度
int[] L = new int[lLength + 1]; // 左新数组,最后一位设置“哨兵”
int[] R = new int[rLength + 1]; // 右新数组,最后一位设置“哨兵”
for (int i = 0; i < lLength; i++) { // copy A[p..q] 到 L[0..lLength-1]
L[i] = A[p + i];
}
for (int j = 0; j < rLength; j++) { // // copy A[q+1..r] 到 R[0..rLength-1]
R[j] = A[q + 1 + j];
}
L[lLength] = Integer.MAX_VALUE;
R[rLength] = Integer.MAX_VALUE;
int i = 0; // L中剩余元素中最小元素的索引
int j = 0; // R中剩余元素中最小元素的索引
for (int k = p; k <= r; k++) { // 两个有序的数组L和R合并为一个有序的数组
if (L[i] <= R[j]) {
A[k] = L[i];
i++;
} else {
A[k] = R[j];
j++;
}
}
}
public static void main(String[] args) {
int[] A = {2, 4, 5, 7, 1, 2, 3, 6};
MergeSort.mergeSort(A, 0, A.length-1);
System.out.println(Arrays.toString(A));
}
}
#include <iostream>
#include <vector>
#include <cmath>
void merge(std::vector<int> &A, int p, int q, int r) {
int l_length = q - p + 1;
int r_length = r - (q + 1) + 1;
std::vector<int> L(l_length + 1);
std::vector<int> R(r_length + 1);
for (int i = 0; i < l_length; i++) {
L[i] = A[p + i];
}
for (int j = 0; j < r_length; j++) {
R[j] = A[q + 1 + j];
}
L[l_length] = INT_MAX;
R[r_length] = INT_MAX;
int i = 0;
int j = 0;
for (int k = p; k <= r; ++k) {
if (L[i] <= R[j]) {
A[k] = L[i];
i++;
} else {
A[k] = R[j];
j++;
}
}
}
void merge_sort(std::vector<int> &A, int p, int r) {
if (p < r) {
int q = std::floor((p + r) / 2);
merge_sort(A, p, q);
merge_sort(A, q + 1, r);
merge(A, p, q, r);
}
}
int main() {
std::vector<int> A = {2, 4, 5, 7, 1, 2, 3, 6};
merge_sort(A, 0, A.size());
for (int elem: A) {
std::cout << elem << " ";
}
return 0;
}
上面的C++/Java代码实现了伪代码的思想,其中有一个变化是使用了“哨兵”技术,用于简化代码。即再左右两个数组中最后位置各设置一个哨兵 ∞ \infty ∞,每当比较到最后时,意味着所有非哨兵的元素都已排好序。因为我们事先可以知道我们要排序 r − p + 1 r-p+1 r−p+1个元素,所以一旦执行了 r − p + 1 r-p+1 r−p+1个基本步骤,算法就可以停止了。
2.3.2 分析分治算法
当一个算法包含对其自身的递归调用时,我们可以用**递归方程(recurrence equation)或递归式(recurrence)**来描述其运行时间。然后,使用数据工具来求解该递归方程并给出算法性能的界。
若问题规模足够小,如对于某个常量 c c c, n ≤ c n \le c n≤c,则直接求解需要常量时间,我们将其写作 Θ ( 1 ) \Theta(1) Θ(1)。
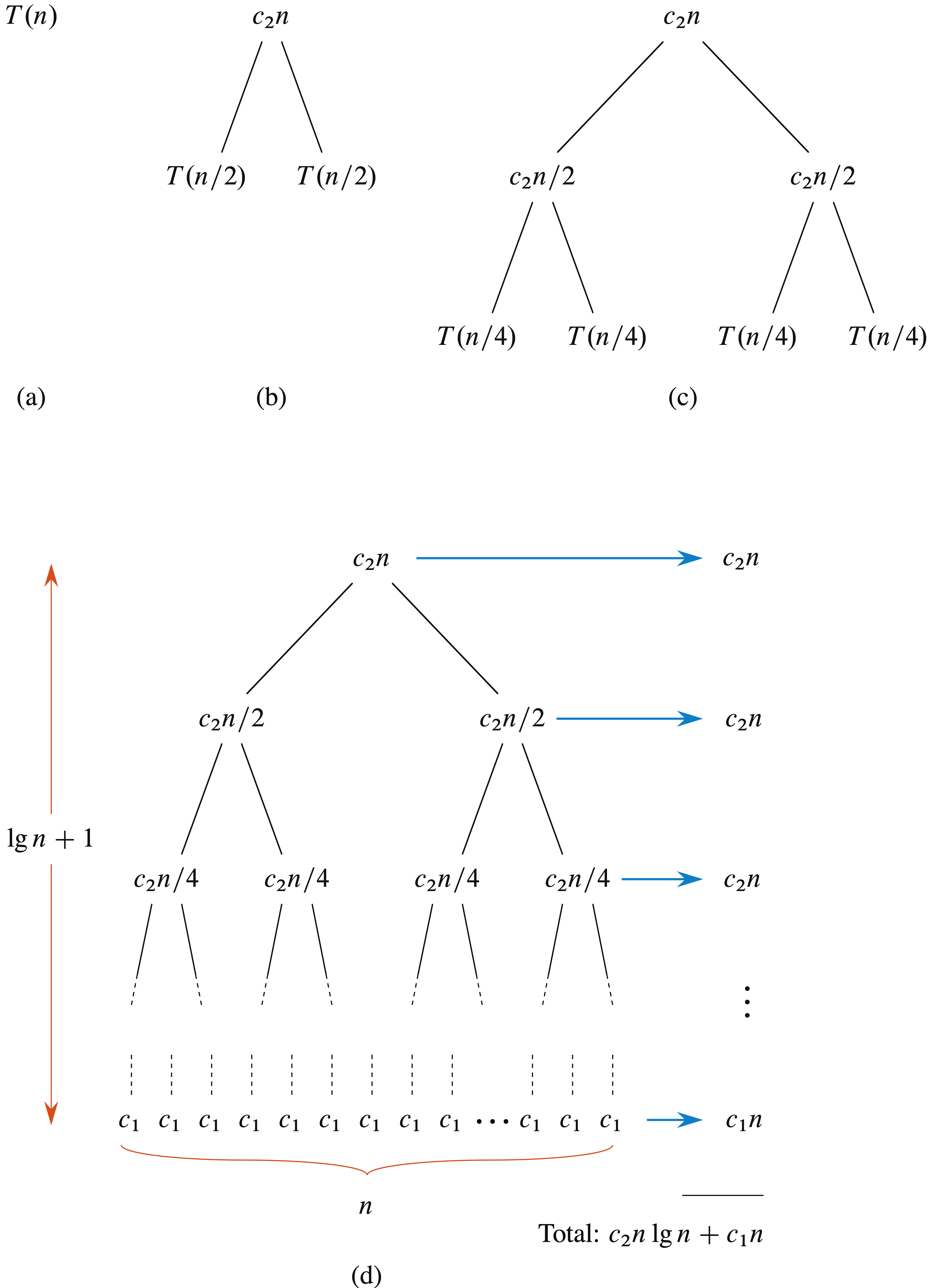
假设原问题分解成 a a a个子问题,每个子问题的规模是原问题的 1 / b 1/b 1/b(对于归并排序, a = b = 2 a=b=2 a=b=2,然而,许多分治算法中,可能 a ≠ b a \ne b a=b),为了求解一个规模为 n / b n / b n/b的子问题,需要 T ( n / b ) T(n/b) T(n/b)的时间,所以需要 a T ( n / b ) aT(n/b) aT(n/b)的时间来求解 a a a个子问题。如果分解(divide)问题为子问题需要时间 D ( n ) D(n) D(n),合并(combine)子问题的解成原问题的解需要 C ( n ) C(n) C(n),那么得到递归方程
T ( n ) = { Θ ( 1 ) n ≤ c a T ( n / b ) + D ( n ) + C ( n ) 其他 T(n) =\begin{cases} \Theta(1) & n \le c \\ aT(n/b)+D(n)+C(n) & 其他 \end{cases} T(n)={Θ(1)aT(n/b)+D(n)+C(n)n≤c其他
归并排序运行时间的递归方程
T ( n ) = { c n = 1 2 T ( n / 2 ) + c n n > 1 T(n) =\begin{cases} c & n=1 \\ 2T(n/2)+cn & n \gt 1 \end{cases} T(n)={c2T(n/2)+cnn=1n>1















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









