







 本文详细介绍了Kafka如何从生产者角度(ISR、ACK、幂等性、事务)保证数据不丢失和不重复,以及Spark Streaming如何通过数据处理后手动提交偏移量和组成事务来达到精确一次消费Kafka。重点讨论了幂等性、事务的优缺点及适用场景。
本文详细介绍了Kafka如何从生产者角度(ISR、ACK、幂等性、事务)保证数据不丢失和不重复,以及Spark Streaming如何通过数据处理后手动提交偏移量和组成事务来达到精确一次消费Kafka。重点讨论了幂等性、事务的优缺点及适用场景。
1、Kafka如何保证数据不丢失和数据重复
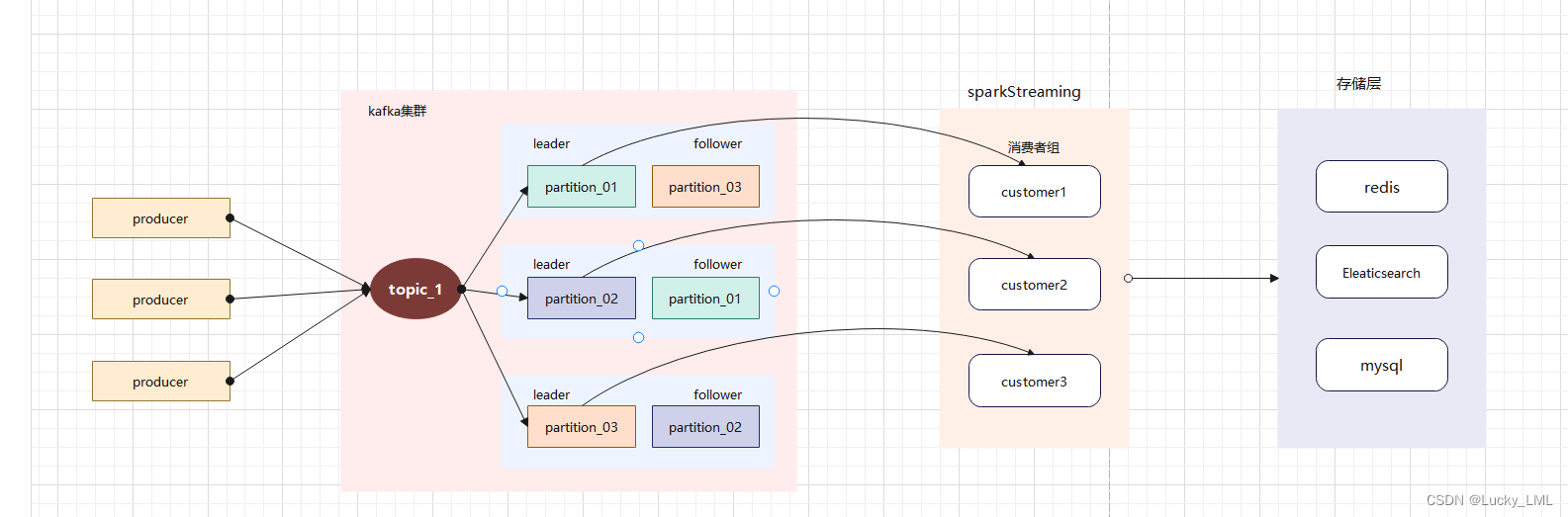
kafka分为生产者和消费者,所以kafka保证数据不丢失需要从以下三个方面保证:
1.1、生产者角度:
1.1.1、什么是ISR
光是依靠多副本机制能保证Kafka的高可用性,但是能保证数据不丢失吗?不行
因为如果leader宕机,但是leader的数据还没同步到follower上去,此时即使选举了follower作为新的leader,但是刚才的数据已经丢失了。
-
ISR是:跟leader 保持同步的follower 集合,当 ISR 中的 follower 完成数据的同步之后,leader 就会给producer 发送 ack。如果 follower长时间未向leader同步数据,则该 follower 将被踢出 ISR,该时间阈值由
replica.lag.time.max.ms(这个参数的含义是 follower 副本能够落后 leader副本的最长时间间隔,当前默认值是 10 秒)参数设定 -
只有处于ISR列表中的follower才可以在leader宕机之后被选举为新的leader,因为在这个ISR列表里代表他的数据跟leader是同步的
1.1.2、什么是ACK
acks参数,其实是控制发送出去的消息的持久化机制的,参数为:
- 0:只要把消息发送出去,不管消息是否写入成功到broker中
- 1:只要leader写入成功,就认为消息成功了,不管follwer有没有同步过去(kafka默认设置)
- all或-1:这个leader写入成功以后,必须等待其他ISR中的副本都写入成功,才可以返回响应说这条消息写入成功了。
- 要真正不丢数据, 需要配合参数:min.insync.replicas: ack 为-1 时生效, ISR 里应答的最小 follower 数量。默认为 1( leader 本身也算一个!), 所以当 ISR 里除了 leader 本身, 没有其他的 follower,即使 ack 设为-1, 相当于 1 的效果, 不能保证不丢数据。需要将 min.insync.replicas 设置大于等于 2, 才能保证有其他副本同步到数据。
1.1.3、生产者保证数据不丢失和数据重复的方法:
ack参数配置为-1
1.2、broker 角度
- 副本数大于 1
- min.insync.replicas 大于 1
1.3、Kafka 幂等性原理 :(缺点:单分区单会话)
在 0.11 版本以前的 Kafka,只能保证数据不丢失,再在下游消费者对数据做全局去重。对于多个下游应用的情况,每个都需要单独做全局去重,这就对性能造成了很大影响。0.11 版本的 Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指 Producer 不论向 Server 发送多少次重复数据,Server 端都只会持久化一条。幂等性结合 At Least Once 语义,就构成了 Kafka 的 Exactly Once 语义。即:
At Least Once(ACK=-1) + 幂等性 = Exactly Once
要启用幂等性,只需要将 Producer 的参数中 enable.idompotence 设置为 true 即可。Kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的 Producer 在初始化的时候会被分配一个 PID,发往同一 Partition 的消息会附带 Sequence Number。而Broker 端会对<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时,Broker 只会持久化一条。
但是 PID 重启就会变化,同时不同的 Partition 也具有不同主键,所以幂等性无法保证跨分区跨会话的 Exactly Once。那么跨分区跨会话的精准一次性如何实现呢,可以引入kafka事务概念。
1.4、kafka事务
Kafka 从 0.11 版本开始引入了事务支持。事务可以保证 Kafka 在 Exactly Once 语义的基础上,生产和消费可以跨分区和会话,要么全部成功,要么全部失败。
Producer事务:
为了实现跨分区跨会话的事务,需要引入一个全局唯一的 Transaction ID,并将 Producer获得的PID 和Transaction ID 绑定。这样当Producer 重启后就可以通过正在进行的 Transaction ID 获得原来的 PID。
为了管理 Transaction,Kafka 引入了一个新的组件 Transaction Coordinator。Producer 就是通过和 Transaction Coordinator 交互获得 Transaction ID 对应的任务状态。Transaction Coordinator 还负责将事务所有写入 Kafka 的一个内部 Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行。
Consumer事务:
上述事务机制主要是从 Producer 方面考虑,对于 Consumer 而言,事务的保证就会相对较弱,尤其时无法保证 Commit 的信息被精确消费。这是由于 Consumer 可以通过 offset 访问任意信息,而且不同的 Segment File 生命周期不同,同一事务的消息可能会出现重启后被删除的情况。
而由于性能等原因,在当前笔者项目使用中kafka本身不会开启事务,事务由下游消费者开启:这里以Spark streaming为例:
2、下游系统(sparkStreaming如何精确一次消费kafka)
默认消费kafka后是自动提交偏移量的, 但是这样就有可能有两种情况发生:
- 先提交偏移量,再处理消息
如果先提交了偏移量后, 处理数据后准备落盘的过程中进程挂了. 但是此时已经提交了偏移量, 那么下次会从最新的偏移量位置开始消费, 所以之前没有落盘的数据就丢失了
- 先处理消息,再提交偏移量
如果再处理完消息后, 进程挂了, 无法提交最新消费的偏移量, 那么下次还是会继续从旧的偏移量位置开始消费, 那么就有可能导致数据的重复消费
- 解决方案:
2.1、方法1:数据处理完后再手动提交偏移量+幂等性去重处理
我们知道如果能够同时解决数据丢失和数据重复问题,就等于做到了精确一次消费。那就各个击破。
首先解决数据丢失问题,办法就是要等数据保存成功后再提交偏移量,所以就必须手工来控制偏移量的提交时机。
但是如果数据保存了,没等偏移量提交进程挂了,数据会被重复消费。怎么办?那就要把数据的保存做成幂等性保存。即同一批数据反复保存多次,数据不会翻倍,保存一次和保存一百次的效果是一样的。如果能做到这个,就达到了幂等性保存,就不用担心数据会重复了。
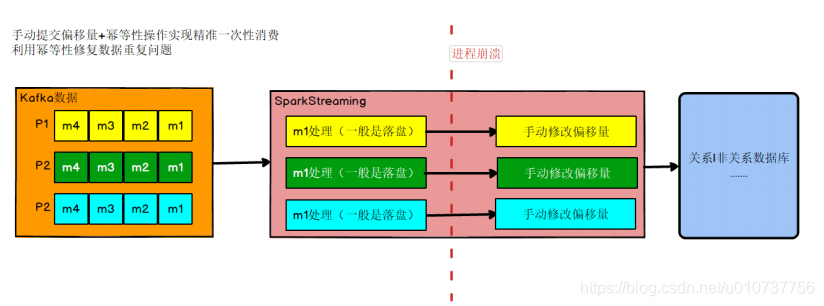
➢ 难点
话虽如此,在实际的开发中手动提交偏移量其实不难,难的是幂等性的保存,有的时候并不一定能保证,这个需要看使用的数据库,如果数据库本身不支持幂等性操作,那只能优先保证的数据不丢失,数据重复难以避免,即只保证了至少一次消费的语义。一般有主键的数据库都支持幂等性操作 upsert。
➢ 使用场景
处理数据较多,或者数据保存在不支持事务的数据库上
2.2、方法2:(数据处理+修改偏移量)组成事务
出现丢失或者重复的问题,核心就是偏移量的提交与数据的保存,不是原子性的。如果能做成要么数据保存和偏移量都成功,要么两个失败,那么就不会出现丢失或者重复了。这样的话可以把存数据和修改偏移量放到一个事务里。这样就做到前面的成功,如果后面做失败了,就回滚前面那么就达成了原子性,这种情况先存数据还是先修改偏移量没影响。
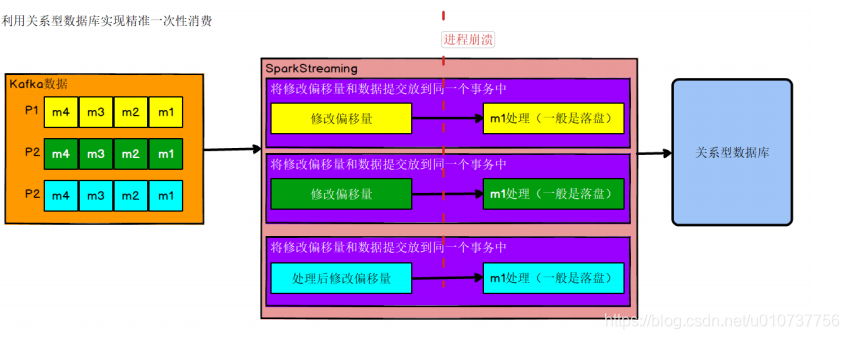
➢ 好处
事务方式能够保证精准一次性消费
➢ 问题与限制
◼ 数据必须都要放在某一个关系型数据库中,无法使用其他功能强大的 nosql 数据
库
◼ 事务本身性能不好
◼ 如果保存的数据量较大一个数据库节点不够,多个节点的话,还要考虑分布式事务的问题。分布式事务会带来管理的复杂性,一般企业不选择使用,有的企业会把分布式事务变成本地事务,例如把 Executor 上的数据通过 rdd.collect 算子提取到Driver 端,由 Driver 端统一写入数据库,这样会将分布式事务变成本地事务的单线程操作,降低了写入的吞吐量。
➢ 使用场景
数据足够少(通常经过聚合后的数据量都比较小,明细数据一般数据量都比较大),并且支持事务的数据库
2.3、基于scala的代码实现demo
pom.xml
<dependency>
<groupId>org.scalikejdbc</groupId>
<artifactId>scalikejdbc_2.11</artifactId>
<version>3.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1375
1375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









