









提示:个人记录的主观感受,学疏才浅,请勿作为标准答案。我也正在学习Java,理解错误的地方恳请批评指正。
目录
为什么要引入双链表结构?(LinkedHashMap的存在意义?)
HashTable的小补充:KEY,VALUE均不能为null
前言
前文HashMap用法与原理详解中已经介绍了Map家族的绝对主角HashMap,今天来认识一下Map家族其他的常见成员们。
一、LinkedHashMap
我们已经知道了HashMap的基本结构,而LinkedHashMap长得和HashMap几乎一模一样,甚至在Java 1.8 后HashMap学会的“树化”这一技能,LinkedHashMap也跟着一并学会了。
LinkedHashMap的签名
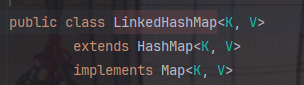
可以看出直接继承了HashMap
LinkedHashMap的结构
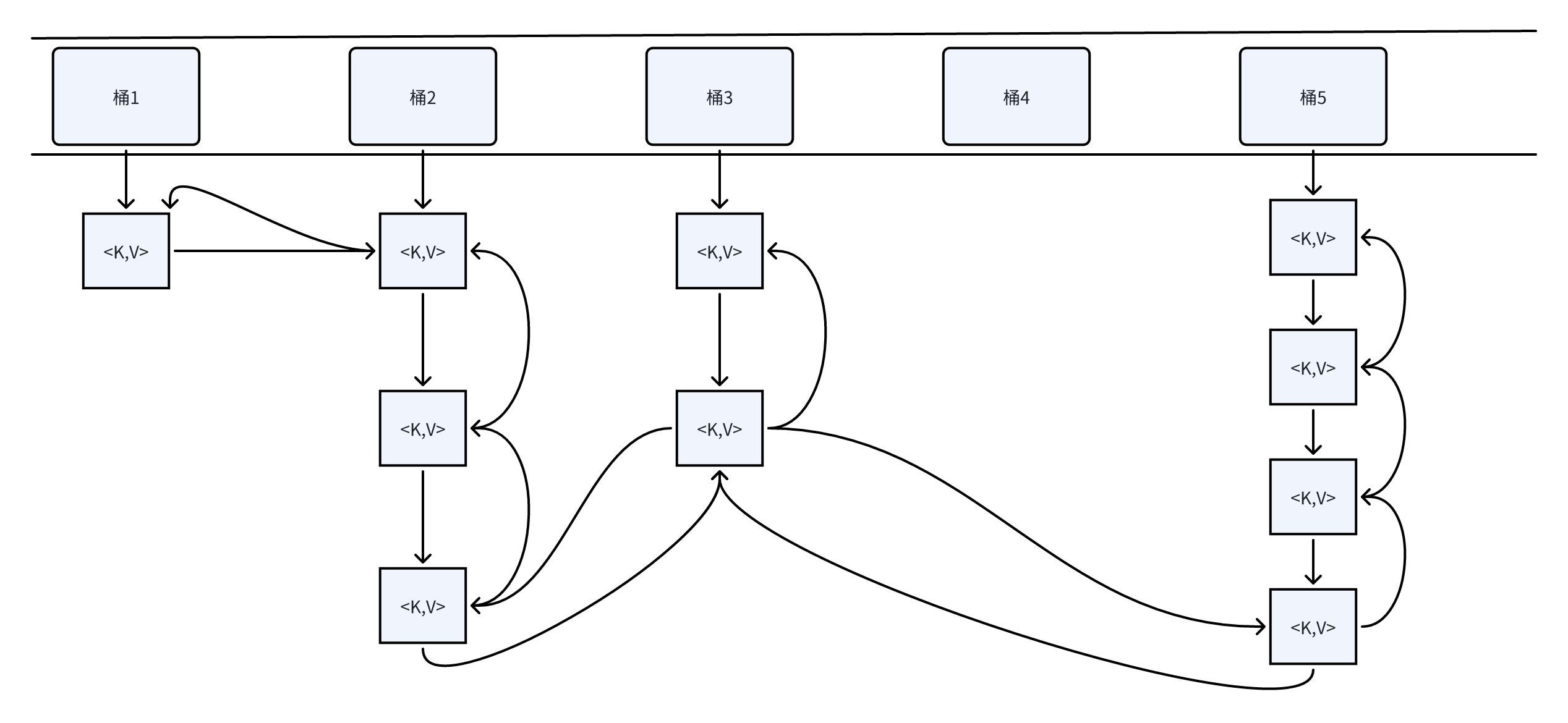
和HashMap长的几乎一模一样,不过桶中的每个HashEntry形成了双链表。
为什么要引入双链表结构?(LinkedHashMap的存在意义?)
回答这个问题也就回答了LinkedHashMap区别于HashMap的特殊之处,也正是它被设计出来的意义。
我们介绍过,HashMap并没有实现Navigable接口,也就是说它的HashEntry键值对之间是无序的。
通过维护一对头尾指针来保存链表信息,头是老节点,尾是新节点
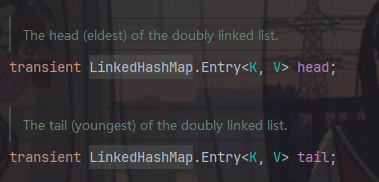
而LinkedHashMap通过双向链表,记录了键值对的插入顺序或者访问顺序,使得键值对之间具有了一种顺序性。而这带给我们的用处就是:
我们可以按照插入顺序或者访问顺序来打印LinkedHashMap。
至于是何种顺序,取决于一个参数字段accessOrder

true为访问顺序,false为插入顺序。
让我们再看看LinkedHashMap的构造函数,就可以马上清楚用法了。
/**
* Constructs an empty insertion-ordered {@code LinkedHashMap} instance
* with the specified initial capacity and a default load factor (0.75).
*
* @param initialCapacity the initial capacity
* @throws IllegalArgumentException if the initial capacity is negative
*/
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
/**
* Constructs an empty insertion-ordered {@code LinkedHashMap} instance
* with the default initial capacity (16) and load factor (0.75).
*/
public LinkedHashMap() {
super();
accessOrder = false;
}
/**
* Constructs an insertion-ordered {@code LinkedHashMap} instance with
* the same mappings as the specified map. The {@code LinkedHashMap}
* instance is created with a default load factor (0.75) and an initial
* capacity sufficient to hold the mappings in the specified map.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
/**
* Constructs an empty {@code LinkedHashMap} instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - {@code true} for
* access-order, {@code false} for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}从源码我们可以看到一些老朋友,如loadFactor,和HashMap一样默认值为0.75.
我们注意到,accessOrder默认为false,即LinkedHashMap默认的访问/打印顺序是按照插入顺序。
二、HashTable
HashTable的签名
HashTable是一种稍微过时的容器,因为它的效率非常低,原因我们马上会讲。
从整体上来说,HashTable和HashMap的长相是差不多的,都是数组+链表来解决哈希冲突。
但是也许是因为HashTable有点儿过时不好用所以作者不更新它(我猜的),所以HashTable并没有学会HashMap的"树化"技能。
HashTable效率很低
因为HashTable几乎所有的公共方法都使用了synchronized锁,这是一种基于JVM底层实现的锁。这样大粒度的加锁方式导致HashTable的使用效率非常低,比如我们一个线程抢到了一个HashTable方法A的锁,这时候,由于synchronized的特性:对实例级方法加锁等于对实例对象加锁,所以该HashTable的所有方法这时候都无法被其他线程使用,其余线程来了就被阻塞,又由于synchronized锁的阻塞特性和不可中断特性,只有等占有锁的线程释放锁后才可继续。
HashTable的小补充:KEY,VALUE均不能为null
事实上,并发安全的Map都是不允许Key,Value为null的,包括最好用的ConcurrentHashMap。
这是因为,key和value如果被允许为null,会导致二义性问题:
二义性问题:
1. 线程1put了一个键值对<A,null>,线程1自己是知道map中是有一个key为A的键值对的。
2. 线程2也来查这个A键值对,线程2非常谨慎,他在查之前还专门使用了containsKey,看到返回了true才放心下来,准备继续get。
3. 这时候线程1使坏,删掉了这个键值对。
4. 之后线程2来getA的键值对,返回的是null。这个时候线程2就不知道到底是因为这个键值对不存在还是因为值为null。
三、TreeMap
TreeMap采用红黑树实现Map功能,而非数组+链表+红黑树。所以它的增删改查原理与红黑树一致、
总结
今天大致介绍了LinkedHashMap、HashTable、TreeMap。我认为重要的部分都使用了小标题,如LinkedHashMap的双向链表,HashTable效率问题,二义性问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









