







action recognition/activity recognition/行为识别/动作识别+经典论文/网络框架+阅读小总结
基于2D图像和视频的行为识别
1. two-stream related(双流方法)
1)Two-stream convolutional networks for action recognition in videos
论文:https://arxiv.org/abs/1406.2199
未公开代码
年份:2014
这篇论文是双流方法的开山之作。
论文所提出的网络使用以单帧RGB作为输入的CNN来处理空间维度的信息,使用以多帧密度光流场作为输入的CNN来处理时间维度的信息。并通过多任务训练的方法将两个行为分类的数据集(UCF101与HMDB)联合起来,去除过拟合进而获得更好效果。
贡献有三点:
1)提出结合时间和空间网络的双流ConvNet网络结构;
2)证明在缺少训练集的情况下,ConvNet在多帧密集光流中依然能取得非常好的训练效果;
3)实验表明,应用于两个不同的识别训练集,这种多任务学习方法不仅可以用于增加训练数据,还可以提升两者的性能。
视频能分成空间域和时间域,空间域以单帧的形式携带有关视频中描绘的场景和对象的信息,时间域以多帧之间的动作变化,传达观察者(相机)和物体的运动。
具体的双流结构如下图所示。将视频识别架构分为两个流,每一个流(时间流,空间流)使用deep ConvNet,softmax函数后紧跟late fusion。
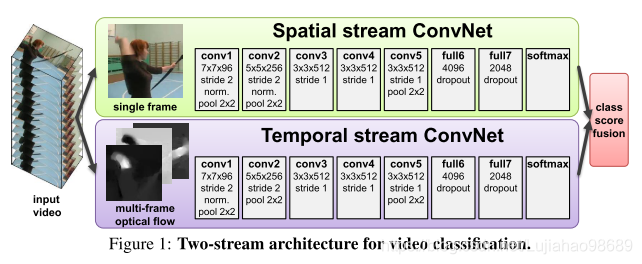
Spatial stream ConvNet:
空间流ConvNet对单个视频帧进行操作。因为一些行为与特定的场景和物体有很强的关联,所以可以有效地从静止图像中进行行为识别。 由于CNN网络已经是一个强大的图像识别算法,所以可以基于大规模图片的识别算法构建视频识别网络,还可以利用现有的图像分类数据集上预训练网络。
Optical flow ConvNets:
不同于普通的CNN网络,时间流ConvNet的输入需要是通过在几个连续帧之间堆叠光流位移场而形成的。这种输入带有视频帧之间的动作特征,使得识别过程变得更加容易(不需要网络再隐式估计动作)
论文在介绍光流位移场时,引入了光流叠加和轨迹叠加的两种表示方式的比较。下左图是Optical flow stacking;下右图是Trajectory stacking。
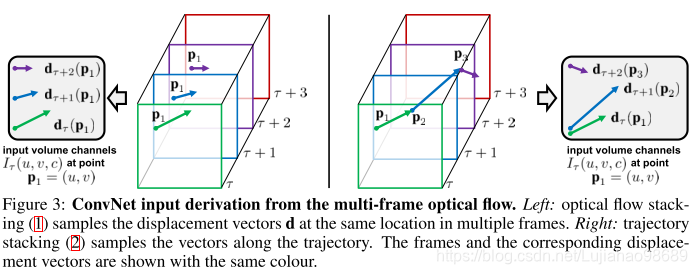
Optical flow stacking:
光流信息可以被看作是连续帧之间的位移矢量场,用𝑑_𝑡 (𝑢,𝑣)表示某帧t上的一点(u,v)变化到下一帧t+1相应的位置时的位移矢量的变化。𝑑_𝑡^𝑥 和𝑑_𝑡^𝑦 分别表示位移矢量的水平和垂直分量,如下图所示

为了显示一系列帧之间的动作变化,堆叠L个连续帧,计算得到相应的光流矢量场的水平和垂直两个分量的光流信息。这样对于视频数据输入到时间流的每一帧来说,就会产生2L个输入通道输入网络。每个通道的表示形式如下公式所示:
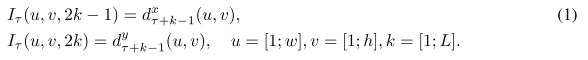
Trajectory stacking:
光流矢量场,是在不同几帧的相同位置进行采样;而轨迹堆叠是沿着动作的轨迹进行采样。如左上图的右图所示。也将轨迹矢量分成水平和垂直两个分量,并堆叠L个连续帧,则时间流网络的输入可以表示为下式:
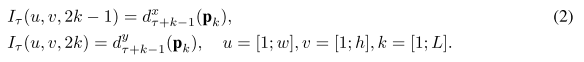
考虑到光流的时序有可能是正向,也有可能是反向。所以这里设置为双向光流,即对于某一帧,堆叠前L/2帧和后L/2帧光流信息,总共仍保持2L个输入通道。
并且在这里不考虑相机移动带来的影响。
Multi-task learning:
由于temporal ConvNet需要在视频数据集上训练,但现有的数据集UCF-101 和 HMDB-51上的视频很少。为了减少过拟合,考虑将这两个数据集组合成一个。一种更加可靠的方法是基于多任务学习的方式进行数据集的合并。
文中的temporal ConvNet网络结构是,在最后全连接层前有两个softmax层,两个softmax分别计算在UCF-101 和 HMDB-51学习的分数,各自有自己的损失函数,整个网络总的损失函数就是两个不同损失函数的和。网络的权值由反向传播计算得到。
Implementation details:
1)ConvNets configuration
网络结构类似于CNN-M-2048;全部的隐藏层激活函数使用ReLU;时间流ConvNet和空间流ConvNet唯一不同的配置是去除了空间流ConvNet的第二正则化层,来减少内存开销。
2)Training
网络的权重通过学习率为0.9的mini-batch stochastic gradient descent方法进行学习。在每次迭代中,通过对256个训练视频(均匀地跨越类)进行采样来构建小批量的256个样本,从每个训练视频中随机选择单个帧。在两个网络学习的过程会根据迭代次数的增加,减小学习率。
3)这里是基于Caffe toolbox开发;光流数据是使用现有的GPU实现的opencv工具箱计算得到;在训练前预先计算好光流数据;将光流的水平和垂直分量线性标准化到[0,255]范围内,并使用jpeg进行压缩,这使得UCF-101数据集的光流数据大小从1.5TB减少到27GB。
Evaluation:
1)Spatial ConvNets
这里考虑通过三种方法得到性能指标来评价空间流CNN的表现和选择训练方案:i) 在UCF-101上从头开始完整训练;i) 空间流CNN先在ILSVRC-2012上进行预培训,然后在UCF-101数据集上进行微调;iii) 保留在ILSVRC-2012上预训练的网络参数,仅仅训练最后一层(分类层)。同时这里考虑两个不同的dropout regularisation ratio:0.5和0.9。实验结果如下表所示:
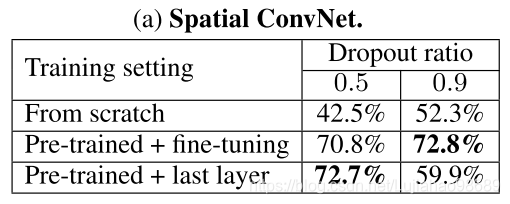
分析得:单独在UCF-101数据集上训练,得到的网络存在过拟合现象;经过预训练的网络有效抑制了过拟合;经过预训练后,只在分类层进行训练的训练方法,比起预训练后微调整个网络参数的训练方法得到的结果更加优异。所以接下来的实验都采用第(iii)方法训练Spatial ConvNets。
2)Temporal ConvNets
在这里,暂时还不考虑多数据集学习带来的影响。主要是在UCF-101数据集上单独学习,来考虑了以下几点的选择:i)测试了两种堆叠的帧数量5和10,来选择最优;ii)比较光流场堆叠和轨迹堆叠的效果,来选择最优;iii)mean displacement subtraction的影响;iv)使用双向(正负)光流信息的效果。这里设置dropout ratio为0.9来提高网络的学习效率。实验结果如下表所示:

分析得:多帧堆叠光流信息比堆叠一帧的光流信息的效果有明显提高;将堆叠帧数从5提高到10,效果的提升较少,所以在接下来的实验中固定堆叠10帧;mean subtraction对结果提升很大,它能减少两帧之间全局动作的影响,在接下来的实验中,默认设置mean subtraction;光流堆叠和轨迹堆叠的效果差不多,光流堆叠稍微更好一点;利用了双向光流的结果比非双向光流的结果有小的提升;对比spatial ConvNet和temporal ConvNet训练的情况,空间流的识别准确率远远比不上时间流,由此得出多帧信息对于行为识别的重要性。
3)Multi-task learning of temporal ConvNets
在这里评估了以下几种不同提升HMDB-51训练集大小的方法,以及训练方案:i)在UCF-101上预训练后,在HMDB-51上对网络参数进行微调;ii)人工从UCF-101数据集中选取与HMDB-51中没有交叉的78个类出来;iii)基于UCF-101和HMDB-51两个数据集,利用多任务学习,学习整个网络参数。实验结果如下表所示:

分析得:基于两个数据集得多任务学习得到得效果最好,这种训练方案可以让训练过程更加有效得挖掘可以利用的所有训练数据。
这里考虑的是在HMDB-51数据集的基础上利用多任务学习联合UCF-101数据集训练。作者还在UCF-101数据集基础上利用多任务学习联合HMDB-51数据集训练,得到的准确度为81.5%。
4)Two-stream ConvNets
在这里评估如何将双流结构模型组合起来。采用两种方法来融合两个流最后的softmax层输出的分数:平均值和线性SVM。实验结果如下表所示:

分析得:时间流和空间流两个网络是有互补的效果,融合以后相较于原先独立的两个网络在识别准确率上都有很大的提升;利用SVM来融合softmax的分数要比用平均的方法得到的效果更好;利用双向光流信息在网络融合时效果较差;利用多任务学习得到的时间流,要比单独一个数据集训练并融合了空间流的网络,表现得更好。
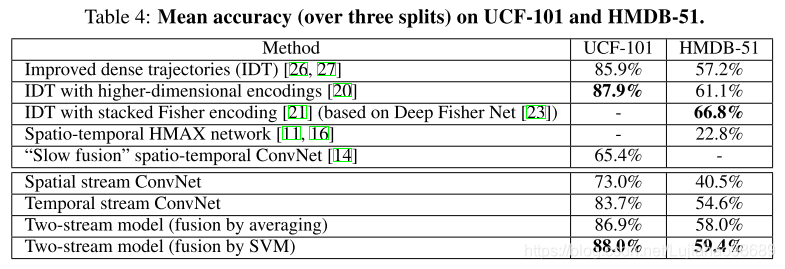
5)Comparison with the state of the art
这里整体的网络结构:
i)空间流网络:先在ILSVRC数据集上预训练,在UCF或HDMB数据集上对最后一个分类层进行训练;
ii)时间流网络:利用多任务学习在UCF和HMDB两个数据集上训练,输入是利用有mean subtraction操作的单向光流信息堆叠得到的10通道光流数据;
iii)两个网络最后的softmax分数采用平均或SVM融合。比较如下表所示。
可以看出这篇文章中提出的双流结构的行为识别网络在当时是state of the art。
可以提升的地方:
i)将网络在更大的数据集上进行训练,由于数据量巨大,有一定的挑战;
ii)有些先进的好方法没有在这个双流网络中使用,例如 local feature pooling over spa
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









