






我选择网页是B站上搜索”回放“1-15页的网页,代码如下:
import requests
import re
import sys
import urllib
def request_bilibili(url):
try:
# 同步请求
response = requests.get(url)
if response.status_code == 200:
return response.text
except requests.RequestException:
return None
def parse_result(html):
pattern = re.compile('.*?class="title">(.*?)</a', re.S)
items = re.findall(pattern, html)
return items
def write_item_to_file(item):
text = ''
item = resub(item)
text += item + '\n'
print('开始写入数据 ====> ' + str(text))
with open('../title.txt', 'a', encoding='UTF-8') as f:
f.write(text)
# 以下根据网页来剔除不需要的部分
def resub(item):
item = re.sub(r'^<span>.*\n?', '', item, flags=re.MULTILINE) ## 去掉本站特有的<span>
item = re.sub('<em class=\"keyword\">', '', item) ## 去掉 搜索关键词标签
item = re.sub('</em>', '', item) ## 去掉 /标签
item = re.sub('"', '"', item)
return item
def key2url(data):
keyword = urllib.parse.quote(data.encode('utf-8').decode(sys.stdin.encoding).encode('utf8'))
return keyword
def main(page):
url = 'https://search.bilibili.com/all?keyword=' + key2url("回放") + '&from_source=web_search&page=' + str(page)
html = request_bilibili(url)
items = parse_result(html)
for item in items:
write_item_to_file(item)
if __name__ == "__main__":
for i in range(1, 15):
main(i)
效果图:
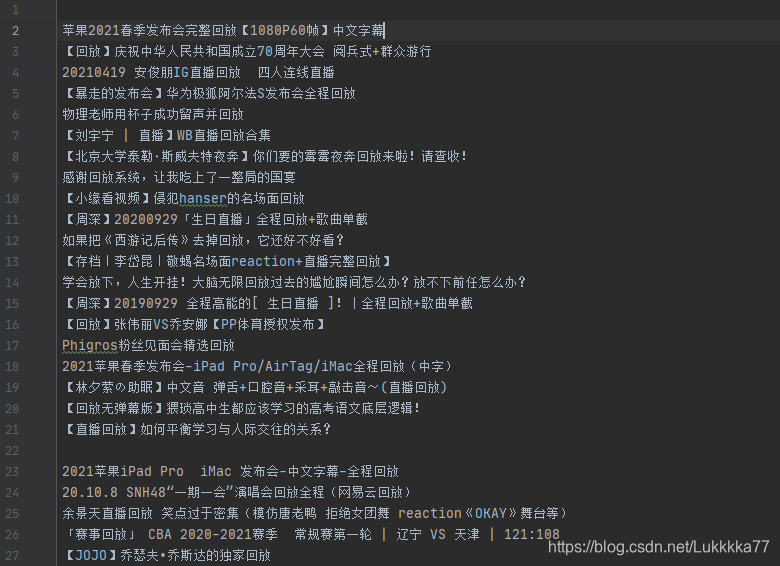
发现了一个小问题:
关于range()函数的问题,是获取到二者之间的数。
例如range(1,10)就只会获取1到9。
修改办法:改成range(10)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









