







本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习内容,尽在聚客AI学院。
一. Prompt设计的基本原则
1.1 核心三要素
-
明确性:精确描述任务需求(如"生成3条科技新闻标题" vs "写点科技内容")
-
可控性:通过指令约束输出格式(如JSON/XML/Markdown)
-
引导性:用示例引导模型风格(Few-shot Learning)
黄金法则:
明确任务 → 提供上下文 → 指定格式 → 示例示范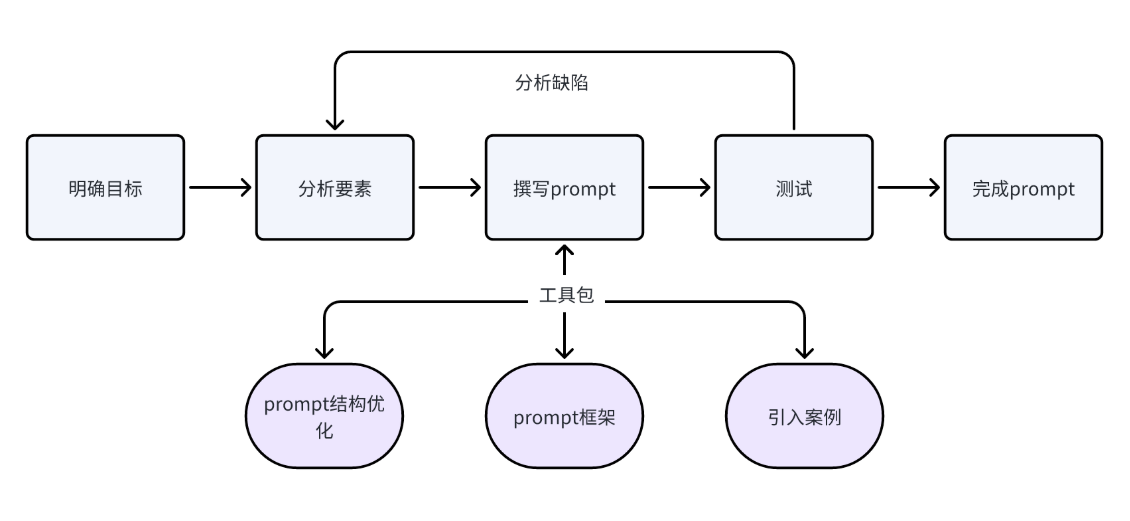
二. 简洁性与清晰度
2.1 简洁性设计技巧
-
去除冗余词:
-
劣质Prompt:
-
请帮我写一个关于机器学习在医疗领域应用的文章,要包含至少三个具体案例,每个案例需要详细描述技术原理和实际效果,总字数不少于1000字... 优质Prompt:
生成一篇机器学习在医疗应用的综述,包含3个案例(技术原理+效果数据),使用Markdown分章节排版 使用符号分隔:
角色:医疗科技记者
任务:撰写CT影像分析技术进展报告
要求:
- 分"技术演进"、"商业应用"、"伦理挑战"三部分
- 每个部分包含2个案例
- 输出为带标题的Markdown2.2 清晰度保障方法
-
量化指标:
生成5条新能源汽车广告文案:
- 每条不超过20字
- 包含"续航"、"智能"关键词
- 使用疑问句或感叹句式代码示例:使用LangChain构建清晰Prompt
from langchain.prompts import PromptTemplate
template = """
作为{role},请完成以下任务:
{task}
要求:
{requirements}
"""
prompt = PromptTemplate(
input_variables=["role","task","requirements"],
template=template
)
print(prompt.format(
role="资深产品经理",
task="撰写智能手环市场分析报告",
requirements="- 分3个章节\n- 包含SWOT分析\n- 输出Markdown格式"
))三. 上下文与语境设计
3.1 上下文注入策略
-
显式声明:
背景:2023年Q3中国手机市场数据(IDC报告)
- 出货量同比下降6%
- 折叠屏手机增长120%
任务:基于上述数据,分析未来趋势隐式引导:
假设你是马斯克,在2024年AI安全峰会的开幕致辞中提出3点监管建议3.2 语境长度控制
-
滑动窗口法:保留最近N条对话历史
-
关键信息提取:使用摘要模型压缩上下文
from transformers import pipeline
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
long_text = "..." # 长文本
summary = summarizer(long_text, max_length=100, min_length=30, do_sample=False)
print(summary[0]['summary_text'])四. 问题明确性保障
4.1 模糊Prompt案例分析

4.2 明确性检查清单
是否指定了输出格式(JSON/CSV/表格)?
是否限定了内容范围(时间/地域/行业)?
是否明确了风格要求(专业/口语化/幽默)?
是否设置了长度限制(字数/条目数)?
五. 指令设计技巧
5.1 指令类型化模板
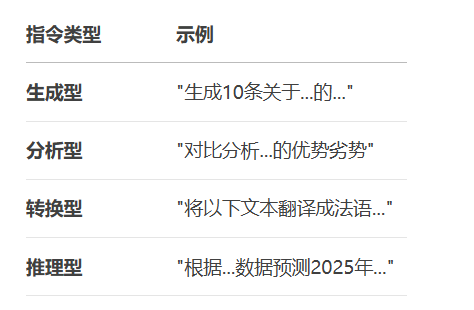
5.2 多步骤指令设计
1. 从维基百科提取"量子计算"发展历史时间线
2. 标注每个阶段的关键技术突破
3. 生成可视化建议(图表类型+数据维度)
按JSON格式输出:
{
"timeline": [{year:, event:, technology:}],
"visualization": [{type:, data:}]
}代码示例:结构化指令实现
def create_tech_prompt(topic):
return f"""
执行以下分析任务:
主题:{topic}
步骤:
1. 识别三个主要发展阶段
2. 每个阶段列出2项关键技术
3. 评估当前技术成熟度(1-5分)
按如下JSON格式输出:
{{
"stages": [
{{"name": "", "technologies": [], "maturity": }}
]
}}
"""
print(create_tech_prompt("基因编辑"))六. 结构化与非结构化Prompt
6.1 结构化Prompt模板
{
"task": "产品描述生成",
"product": "无线降噪耳机",
"requirements": {
"length": "150字",
"keywords": ["Hi-Res认证", "40小时续航", "自适应降噪"],
"style": "科技感",
"exclude": ["价格信息", "促销内容"]
}
}6.2 非结构化Prompt优化
-
标记系统:
#角色# 资深影评人
#任务# 分析《奥本海默》的叙事结构
#要求#
- 对比诺兰前作
- 聚焦非线性别事手法
- 输出带时间码的案例分隔符号:
[BEGIN PROMPT]
作为历史学家,用学术论文风格解释工业革命的影响:
- 分经济/社会/技术三个维度
- 每个维度包含2个数据案例
- 禁用第一人称
[END PROMPT]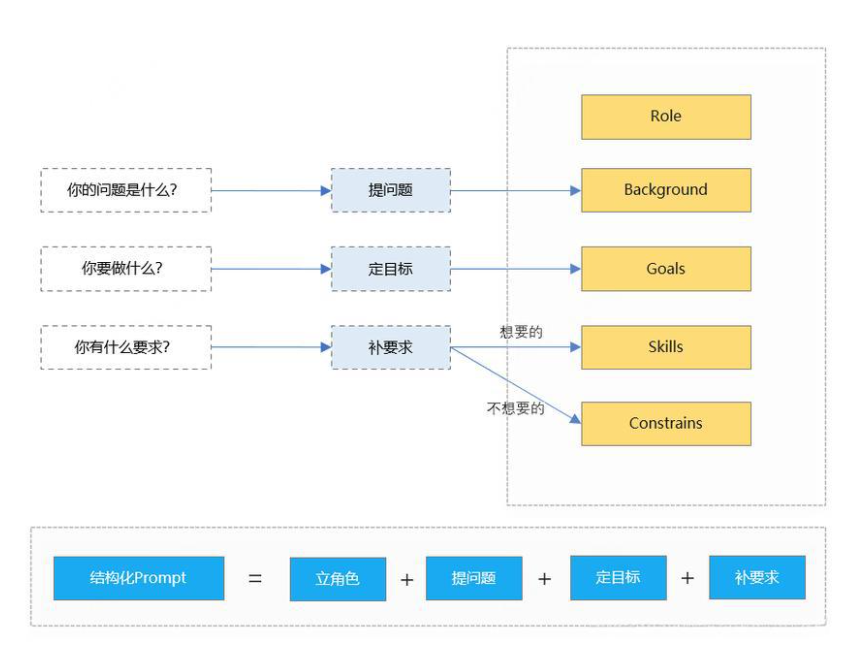
代码示例:Prompt效果评估
import evaluate
rouge = evaluate.load('rouge')
references = ["这是一条标准答案"]
predictions = ["模型生成的回答"]
results = rouge.compute(
predictions=predictions,
references=references,
rouge_types=['rougeL']
)
print(f"ROUGE-L分数:{results['rougeL']}")附:Prompt设计检查清单
任务目标是否用动词明确描述(生成/分析/转换)?
是否包含负面约束(不要包含/避免提及)?
是否有示例演示预期格式?
专业术语是否有明确定义?
长度/数量等是否量化指定?
注:本文代码需安装以下依赖:
pip install langchain transformers evaluate更多AI大模型应用开发学习内容,尽在聚客AI学院。


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











