







目录
18、应用实例:图片文字识别ORC(Optical Character Recognition)
第一周
1、引言
- 1.2 好的学习问题
经验E中学习,解决任务T,达到性能度量值P。有了E,经过P评判,T性能提升。
- 1.3 监督学习
给出的数据集中样本都有正确答案,再对其他数据进行判断,分类问题/回归问题
- 1.4 无监督学习(聚类算法)
已知的数据集没有任何标签,自己处理。可能被分为不同的簇。
鸡尾酒宴声音划分代码:
2、单变量线性回归
- 2.1 单变量线性回归
假设h
- 2.2 代价函数
使之最小
- 2.5 梯度下降
不停寻找局部最小值,不同初始参数组合可能会找到不同的局部最小。
批量梯度下降公式
学习率α,太小速率太慢,太大可能无法收敛,更新时需要同时更新θ1和θ2。
当我们接近局部最低点,梯度下降法幅度自动变小,局部最低点导数为0.

- 2.7 梯度下降的线性回归
关键在于求出代价函数的导数
第二周
4、多变量线性回归
- 4.2 多变量梯度下降
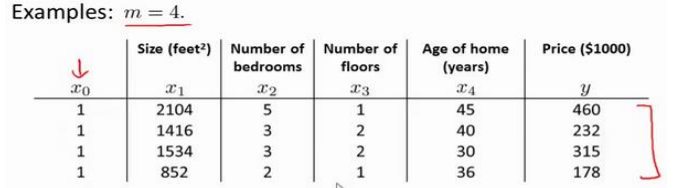
对比单变量,x0=1
当n>=1时
- 4.3 特征缩放-梯度下降法实践1
尝试将所有特征尺度缩放到[-1, 1],迭代速度更快。
方法如下,Un平均值,Sn标准差。
- 4.4 学习率-实践2
α通常可以考虑 0.01, 0.03, 0.1, 0.3, 1, 3, 10
- 4.6 正规方程
训练集特征矩阵为𝑋,并且我们的训练集结果为向量y。
利用正规方程求出向量θ

第三周
6、逻辑回归(分类算法)
- 6.1 分类问题
二元分类问题,因变量:正/负向类
使用线性回归输出值y可能y>>1||y<<0。逻辑回归算法让输出值永远在[0, 1]
- 6.2 假说表示
逻辑回归模型假设.X特征向量,g逻辑函数
hθ(x)给定输入变量,根据参数计算输出变量=1的可能性

- 6.3 判定边界
我们可以用非常复杂的模型来适应非常复杂形状的判定边界
- 6.4 代价函数
对逻辑回归 使用线性回归 代价函数(模型误差的平方和)得到一个非凸函数,有许多局部最小值。
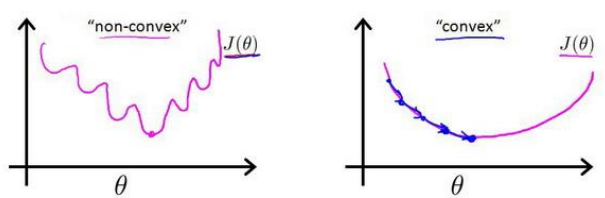
重新定义逻辑回归的代价函数如下:
将hθ带入得到cost,cost简化如下
代入代价函数
- 6.5 简化的成本函数和梯度下降
线性回归和逻辑回归不是同一个算法!!!
线性回归假设函数:
逻辑回归假设函数:
更新参数规则基本相同(见多变量梯度下降迭代),假设定义发生变化,两者线性下降是完全不同的两个东西。
但是线性回归的特征缩放等逻辑回归是可以使用的。
- 6.6 高级优化
换个角度看梯度下降。
最小代价函数J(θ),编写代码,输入参数θ,计算出J(θ)以及J=0、1到n的偏导。
梯度下降反复执行上述更新。我们可以只关注偏导不关注代价函数。
BFGS / L-BFGS算法用库实现,不建议手动编写。
- 6.7 多类别分类:一对多
将所有的类分成不同的2类进行划分,多类中一类作为正,其他全为负。
模型简记:
训练逻辑回归分类器输入x得到如下,选择可信度最高效果最好的分类器。
7、正则化
- 7.1 过拟合问题
处理策略:
- 丢弃一些对模型帮助不大的特征
- 正则化:保留所有特征,但是减少参数的大小
- 7.2 代价函数
一个简单防止过拟合的假设,入是正则化参数。
正则化处理和原模型对比:如果入过大,把虽有参数最小化,红色直线所示欠拟合。

- 7.3 正则化线性回归
梯度下降使代价函数最小,未使用正则化,分为两种情况

更新式子得到
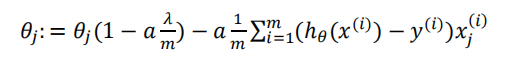
每次都在原有算法更新规则的 基础上令𝜃值减少了一个额外的值
也可以用正规方程求解4.6
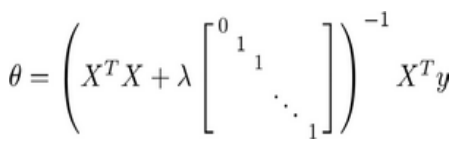
- 7.4 正则化的逻辑回归模型
代价函数代入cost见6.4
第四周
8、神经网络
- 8.1 非线性假设
图像识别难,计算机看到的是灰度矩阵/RGB存储量x3
- 8.2 神经元和大脑
假设大脑思维方式不需要成千上万算法,而只需要一个。
躯体感觉皮层进行神经重接(视觉)实验,该皮层也能学会看。
如果人体有同一块脑组织可以处理光、声或触觉信号,也许存在一种学习算法,可以同时处理视觉、听觉和触觉。
- 8.3 模型展示1
神经元(激活单位),输入/树突,输出/轴突


第(2)层第i个激活单元,θ权重矩阵
每一个𝑎都是由上一层所有的𝑥和每一个𝑥所对应的θ决定的。从左到右的算法称为前向传播算法。
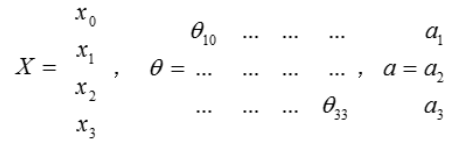
8.4 模型展示2

右半部分其实就是以𝑎0, 𝑎1, 𝑎2, 𝑎3, 按照逻辑回归的方式输出ℎ𝜃(𝑥)
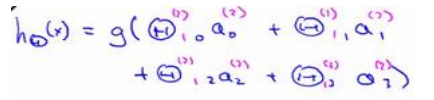
神经网络 vs 逻辑回归
只是把逻辑回归的输入向量变成中间层
- 8.5 特征和直观理解1

单层神经网络和逻辑回归很像
- 8.6 样本和直观理解2
若要实现逻辑非,在预计得到非结果的变量前放一个很大的负权重。
将表示 AND 的神经元和表示(NOT x1) AND (NOT x2)的神经元以及表示 OR 的神经元进行组合,得到了一个能实现 XNOR 运算符功能的神经网络如下。

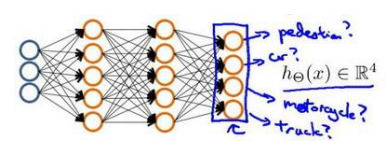
- 8.7 多类分类
输出层 4 个神经元分别用来表示 4 类,也就是每一个数据在输出层都会出现[𝑎 𝑏 𝑐 𝑑]𝑇,且𝑎, 𝑏, 𝑐, 𝑑中仅有一个为 1,表示当前类。
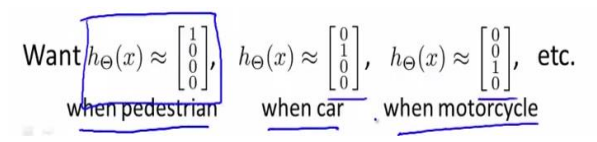
第五周
9、神经网络的学习
- 9.1 代价函数

- 9.2 反向传播
信息前向传播,误差反向传播
- 9.7 综合起来
训练神经网络:
- 参数的随机初始化
- 利用正向传播方法计算所有的ℎ𝜃(𝑥)
- 编写计算代价函数 𝐽 的代码
- 利用反向传播方法计算所有偏导数
- 利用数值检验方法检验这些偏导数
- 使用优化算法来最小化代价函数
第六周
10、应用机器学习的建议
- 10.2 评估一个假设
70%数据做训练集,30%数据做测试集
- 10.3 模型选择和交叉验证集
60%数据训练集:用来训练θ
20%数据交叉验证:选择多项式
20%数据测试集:判断泛化能力


- 10.4 偏差和方差

训练集误差和交叉验证集误差近似时:偏差/欠拟合
交叉验证集误差远大于训练集误差时:方差/过拟合
- 10.5 正则化和偏差/方差
选择合适的入,0-10之间呈现2倍关系的值,分为12组试试

Jθ代价函数,Jcv交叉验证误差

- 10.6 学习曲线
高偏差/欠拟合增加训练集无帮助
高方差/欠拟合有帮助
- 10.7 决定下一步做什么
模型有较大误差:
- 获得更多的训练实例——解决高方差
- 尝试减少特征的数量——解决高方差
- 尝试获得更多的特征——解决高偏差
- 尝试增加多项式特征——解决高偏差
- 尝试减少正则化程度 λ——解决高偏差
- 尝试增加正则化程度 λ——解决高方差
较小神经网络计算量小,易出现欠拟合;大型神经网络已出现过拟合。
通常选择较大神经网络并采用正则化,比直接采用小型效果更好。
神经网络层数的选择:通过将数据分为:训练集、交叉验证集和训练集,进行训练
11、机器学习系统的设计
- 11.2 误差分析
从一个简单的能快速实现的算法开始:实现该算法并用交叉验证集数据测试这个算法
绘制学习曲线:决定是增加更多数据,或者添加更多特征,还是其他选择
进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的实例,看看这些
- 11.3 类偏斜的误差度量
查准率 =TP/(TP+FP)
查全率 =TP/(TP+FN)

- 11.4 查准率和查全率之间的权衡
阈值越大,判断为真的正确率越高,但是会遗漏更多正样本
用max(F1)选择阈值,会考虑查准率和查全率平均值,但会给其中较低的值更高权重
- 11.5 机器学习的数据
取得成功的人不是拥有最好算法的人,而是拥有最多数据的人
第七周
12、支持向量机SVM
- 12.1 优化目标


- 12.2 大边界的直观理解
支持向量机 = 大间距分类器,具有鲁棒性


正则化参数C,设置的非常大,遇到异常点会更改边界。
C不是太大,会忽略一些异常点,得到更好的边界
回顾 𝐶 = 1/𝜆,因此:
𝐶 较大时,相当于 𝜆 较小,可能会导致过拟合,高方差。
𝐶 较小时,相当于 𝜆 较大,可能会导致低拟合,高偏差
- 12.3 大边界分类背后的数学

参数向量𝜃事实上是和决策界是 90 度正交的。
支持向量机最终可以找到一个较小的𝜃范数。这正是支持向量机中最小化目标函数的目的。
- 12.4 核函数1
𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦(𝑥, 𝑙(1))就是核函数
δ^2越大,从顶点移走,特征变量值减小速度会比较慢
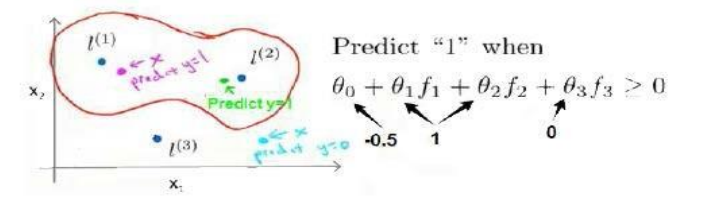

不使用核函数就是线性核函数。
下面是支持向量机的两个参数𝐶和𝜎的影响:
- 𝐶 = 1/𝜆
- 𝐶 较大时,相当于𝜆较小,可能会导致过拟合,高方差;
- 𝐶 较小时,相当于𝜆较大,可能会导致低拟合,高偏差;
- 𝜎较大时,可能会导致低方差,高偏差;
- 𝜎较小时,可能会导致低偏差,高方差。
- 12.6 使用支持向量机
核函数解决高偏差,可构建复杂的非线性决策边界。
从逻辑回归模型,我们得到了支持向量机模型,在两者之间,我们应该如何选择呢?
逻辑回归和不带核函数的SVM相似。
下面是一些普遍使用的准则:
𝑛为特征数,𝑚为训练样本数。
- 如果相较于𝑚而言,𝑛要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
- 如果𝑛较小,而且𝑚大小中等,例如𝑛在 1-1000 之间,而𝑚在 10-10000 之间,使用高斯核函数的支持向量机。
- 如果𝑛较小,而𝑚较大,例如𝑛在 1-1000 之间,而𝑚大于 50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机
神经网络有时训练起来比较慢。
第八周
13、聚类
- 13.1 无监督学习
市场分割、社交网络分析和组织计算机集群。
- 13.2 K-均值算法
随机K个中心,划分
找到划分后的中心(离某个点最近),更新K个中心
重复直到中心不变
- 13.3 优化目标

- 13.4 随机初始化
如果聚类中心少,随机初始化影响较大
- 13.5 选择聚类数
没有最好的选择方法,需要手动。
肘部法则

14、降维
- 14.1 动机一:数据压缩
- 14.2 动机二:数据可视化
- 14.3 主成分分析问题
方向向量是一个经过原点的向量,而投射误差是从特征向量向该方向向量作垂线的长度
归一化,过原点。
区分主成分分析和线性回归

- 14.4 主成分分析算法
PCA 减少𝑛维到𝑘维:
均值归一化。我们需要计算出所有特征的均值,然后令x_j = x_j - u_j 。如果特征是在不同的数量级上,我们还需要将其除以标准差 𝜎2。
计算协方差矩阵(covariance matrix)![]()
计算协方差矩阵𝛴的特征向量(eigenvectors)可以利用奇异值分解。
- 14.5 选择主成分数量
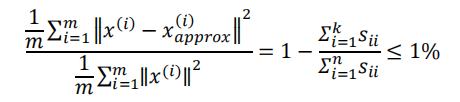
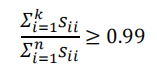
- 14.6 重建的压缩表示
不是方阵,无逆矩阵,用转置近似
- 14.7 主成分分析法的应用建议
错误:用于减少过拟合,不如尝试正则化。
最好还是从原始特征开始,必要时候采用PCA,运行PCA仅在训练集数据上运行,不能交叉验证。
第九周
15、异常检测
- 15.1 问题的动机

- 15.2 高斯分布/正态分布
变量 𝑥 符合高斯分布 𝑥 ∼ 𝑁(𝜇, 𝜎2)则其概率密度函数为:
- 15.3 算法
- 选择特征量(检测出反常用户)
- 代入参数的u和δ
- 给算法新例子测试
- 15.4 开发和评价一个异常检测系统
例如:有 10000 正常的数据,有 20 异常的数据。 我们这样分配数据:
6000 正常数据作为训练集
2000 正常和 10 异常的数据作为交叉检验集
2000 正常和 10 异常擎的数据作为测试集
- 15.5 异常检测与监督学习对比

- 15.6 选择特征
- 15.8 多元高斯分布
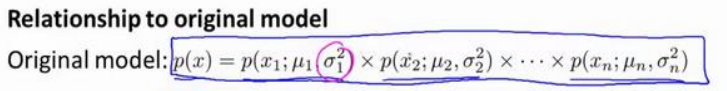
16、推荐系统
- 16.1 问题形式化

- 16.2 基于内容的推荐系统
- 16.3 协同过滤
x和θ,先有鸡还是先有蛋,n维

协同,每个用户都在帮助算法更好的进行特征学习
- 16.4 协同过滤算法
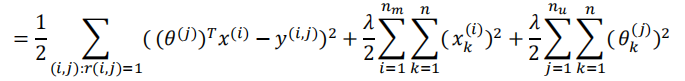
两者的正则化都考虑。
- 16.6 均值归一化
用均值预测
第十周
17、大规模机器学习
- 17.1 大型数据集的学习

- 17.2 随机梯度下降
首先对训练集随机“洗牌”

- 17.3 小批量梯度下降

b在2-100
- 17.4 随机梯度下降收敛
我们也可以令学习率随着迭代次数的增加而减小
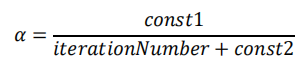
- 17.5 在线学习
小批量梯度下降算法是介于批量梯度下降算法和随机梯度下降算法之间的算法
商品价格、搜索、CTR点击率
18、应用实例:图片文字识别ORC(Optical Character Recognition)
- 18.2 滑动窗口(步长移动)
- 18.3 获取大量数据和人工数据
有关获得更多数据的几种方法:
- 人工数据合成
- 手动收集、标记数据
- 众包
先用准确数
偏差高,持续增分类器特征数/神经网络隐藏单元数
- 18.4 上限分析
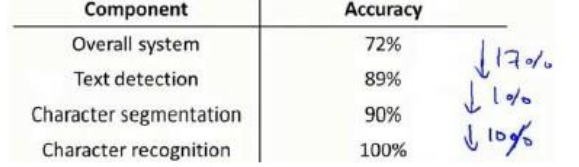
19、总结
监督学习算法:线性回归、逻辑回归、神经网络、支持向量机
无监督学习: K-均值聚类、用于降维的主成分分析,当只有一系列无标签数据 𝑥(𝑖) 时的异常检测算法
接下来怎么做:学习算法的评价,介绍了评价矩阵:查准率、召回率以及 F1 分数,还有评价学习算法比较实用的训练集、交叉验证集和测试集。
学习算法的调试、如何确保学习算法的正常运行:一些诊断法,比如学习曲线,误差分析、上限分析
偏差和方差问题:解决方差问题的正则化















 1944
1944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









