




 本文详细介绍SequoiaDB数据库集群的搭建过程,包括虚拟机准备、软件安装、编目节点、协调节点及数据节点的手工创建等步骤。
本文详细介绍SequoiaDB数据库集群的搭建过程,包括虚拟机准备、软件安装、编目节点、协调节点及数据节点的手工创建等步骤。
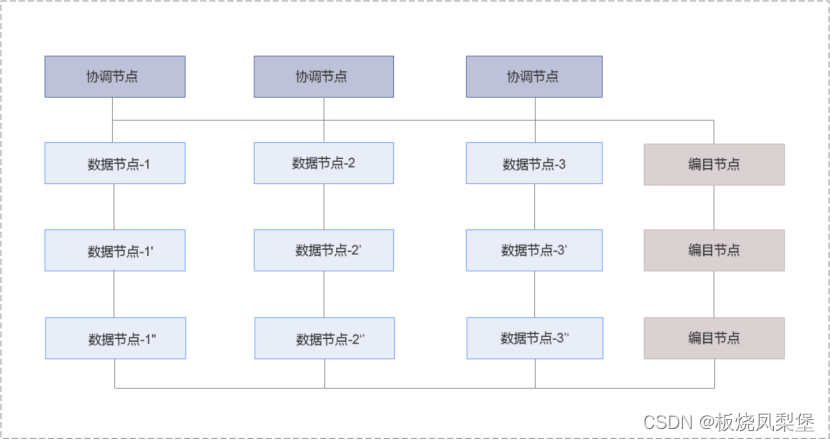
集群物理架构
一组编目节点,一组协调节点,三组数据节点。
Prep:
*准备虚拟机三台
-关闭防火墙
-配置静态ip 并使之能 够互相通信
-配置主机名/IP地址映射(sdb1,sdb2,sdb3)
-关闭SElinux
-调整 ulimit
Step1数据库安装
SequoiaDB 官方网站下载相应版本的安装包:sequoiadb-3.6.1-enterprise-linux_x86_64.tar.gz,在三台虚拟机上安装sdb。
使用root登录:
su root
解压安装包:
tar -zxvf sequoiadb-3.6.1-enterprise-linux_x86_64.tar.gz
赋予可执行权限:
chmod u+x sequoiadb-3.6.1-linux_x86_64-installer.run
运行sequoiadb-3.6.1-linux_x86_64-installer.run:
①可视化安装:
./sequoiadb-3.6.1-linux_x86_64-installer.run --SMS true
根据可视化步骤进行即可。
使用可视化一键部署
②命令行安装:
./sequoiadb-3.6.1-linux_x86_64-installer.run --mode text
Step2 命令行手工安装
Breviary:创建临时协调节点,连接到临时协调节点,创建一个编目节点组,创建数据节点,创建协调节点,删除临时协调节点,完成部署。
创建临时协调节点
var oma = new Oma(“localhost”, 11790)
oma.createCoord(18800, “/opt/sequoiadb/database/coord/18800”)
启动临时协调节点
oma.startNode(18800)
创建编目节点组和节点——连接临时协调节点
var db = new Sdb(“localhost”,18800)
创建编目节点组
db.createCataRG(“sdb1”, 11800, “/opt/sequoiadb/database/cata/11800”)
创建编目节点
var cataRG = db.getCataRG()
var node1=cataRG.createNode(“sdb2”,11800,
“/opt/sequoiadb/database/cata/11800”)
var node2 = cataRG.createNode(“sdb3”, 11800,
“/opt/sequoiadb/database/cata/11800”)
启动编目节点
node1.start()
node2.start()
创建数据节点组和节点
创建数据节点组
var dataRG = db.createRG(“datagroup”)
创建数据节点
dataRG.createNode(“sdb1”,11820,“/opt/sequoiadb/database/data/11820”)
dataRG.createNode(“sdb2”,11820,“/opt/sequoiadb/database/data/11820”)
dataRG.createNode(“sdb3”,11820,“/opt/sequoiadb/database/data/11820”)
启动数据节点组dataRG.start()
创建复制组
var dataRG = db.createRG(“datagroup1”)
创建数据节点
dataRG.createNode(“sdb1”,11830,“/opt/sequoiadb/database/data/11830”)
dataRG.createNode(“sdb2”,11830,“/opt/sequoiadb/database/data/11830”)
dataRG.createNode(“sdb3”,11830,“/opt/sequoiadb/database/data/11830”)
启动数据节点组dataRG.start()
创建复制组
var dataRG = db.createRG(“datagroup2”)
创建数据节点
dataRG.createNode(“sdb1”,11850,“/opt/sequoiadb/database/data/11850”)
dataRG.createNode(“sdb2”,11850,“/opt/sequoiadb/database/data/11850”)
dataRG.createNode(“sdb3”,11850,“/opt/sequoiadb/database/data/11850”)
启动数据节点组dataRG.start()
创建协调节点组和节点
创建协调节点组
var coordRG = db.createCoordRG()
创建协调节点
coordRG.createNode(“sdb1”,11810,“/opt/sequoiadb/database/coord/11810”)
coordRG.createNode(“sdb2”,11810, “/opt/sequoiadb/database/coord/11810”)
coordRG.createNode(“sdb3”,11810, “/opt/sequoiadb/database/coord/11810”)
启动协调节点组:coordRG.start()
删除临时协调节点
连接本地集群管理服务进程 sdbcm
var oma = new Oma(“localhost”, 11790)
删除临时协调节点
oma.removeCoord(18800)
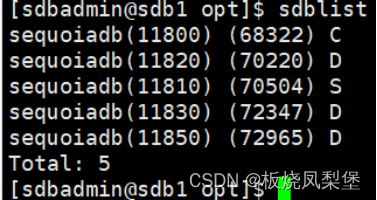
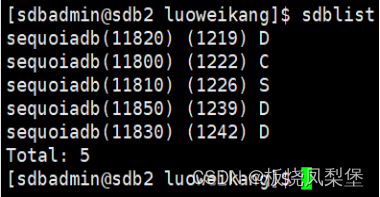
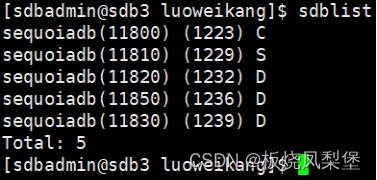

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









