






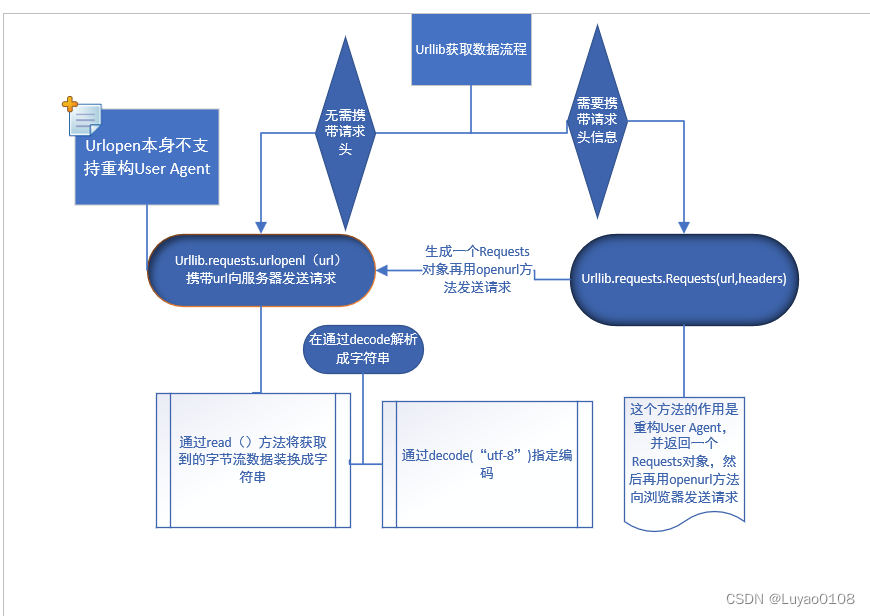
一,urllib.requests.urlopen是模拟浏览器向服务器发送请求,但本身不支持重构User Agent,当遇到需要请求头才能访问的数据时可以通过urllib.requests.Requests(url,headers)生成Requests对象,在交给urlopen重新发送请求

以豆瓣网址为例,没有添加headers时报错, 当我们使用Requests生成一个Requests对象时,发现可以正常访问

二,且urllib.requests.urlopen(url)不支持参数url中有中文,当需要访问的网址中有中文存在,发送请求时就会出现问题,解决方法是将中文处理成%+十六进制的样式
1,示例当我们访问的网址中出现中文时使用urllib发送请求时会报”UnicodeEncodeError: 'ascii' codec can't encode characters in position 15-16: ordinal not in range(128)”的一个错误
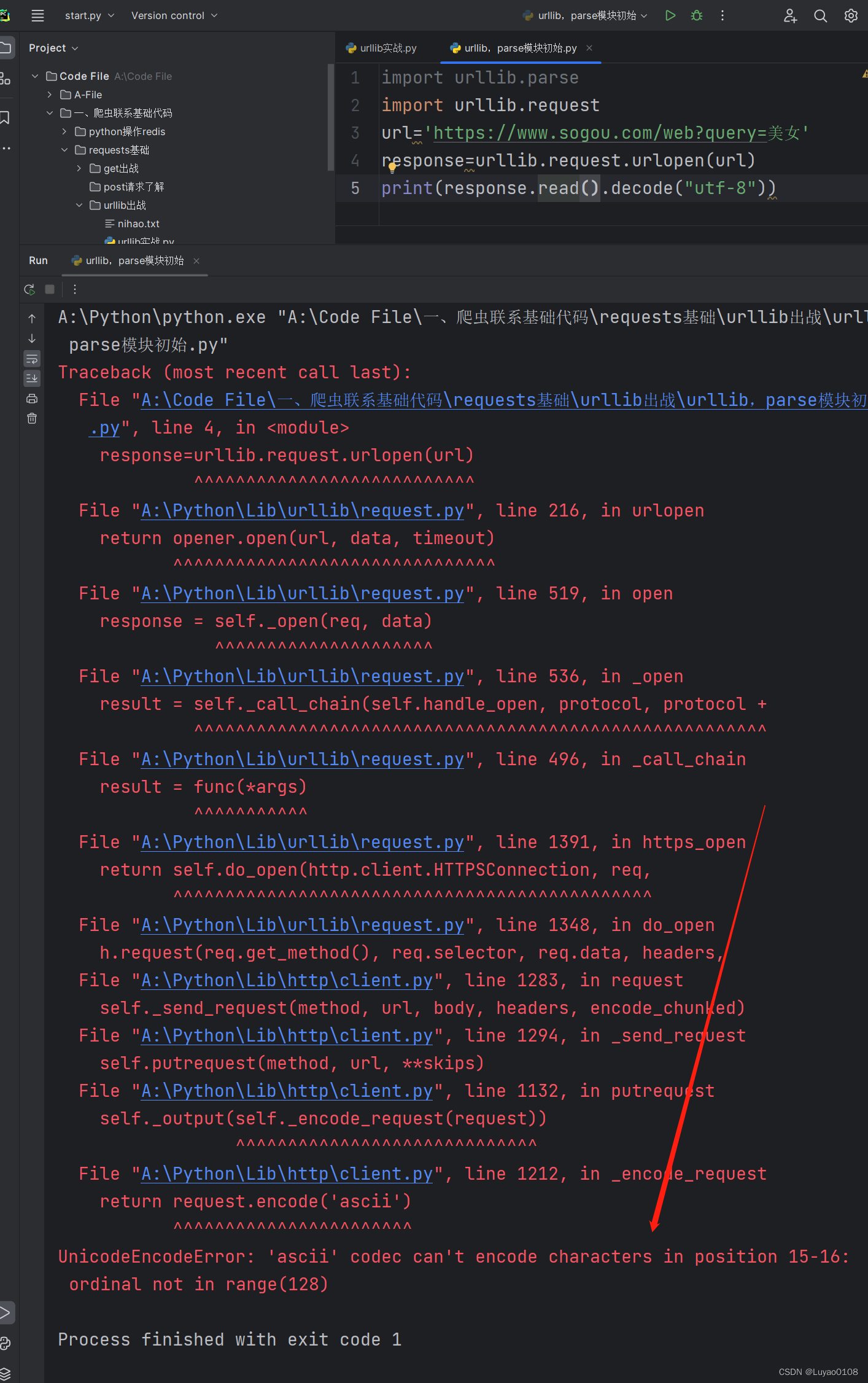
解决方法:
第一个方法是通过urlencode将存入的字典参数形式编码为URL查询字符串(导入方法为from urllib.parse import urlencode)
from urllib.parse import urlencode
url1='https://www.sogou.com/web?query=美女'
url2='https://www.sogou.com/web?query=%E7%BE%8E%E5%A5%B3'
# response=urllib.request.urlopen(url1)
# print(response.read().decode("utf-8"))
r={'query':"美女"}
result=urlencode(r)
# print(result)
# 返回结果为:query=%E7%BE%8E%E5%A5%B3然后进行拼接
new_url='https://www.sogou.com/web?'+result
print(new_url)
# 返回结果为:https://www.sogou.com/web?query=%E7%BE%8E%E5%A5%B3第二个方法是使用quoto(字符串)
from urllib.parse import quote
r='新课教育'
result=quote(r)
print(result)
# 返回结果为%E6%96%B0%E8%AF%BE%E6%95%99%E8%82%B2














 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









