







Spark
框架概述
是一个快如闪电的同一的分析引擎(只做计算,不做存储),仅仅是一款分析引擎,不提供存储服务
快:相比较于一代离线分析框架MapReduce(基于磁盘的迭代,map读(都要),map中间的结果放入磁盘)而言Spark基于内存计算较快
统一:Spark提供了统一的API访问接口,实现类批处理和流处理的统一,并且提供了ETL功能SQL。(一站式的解决方案)
提供了对大规模数据集的全栈式解决方案:批处理,流处理,SQL,Machine Learning,图形关系(一种数据结构)等全栈式的解决方案。
Spark快的原因
-
使用先进的(有向无环图)设计
MapReduce:矢量计算 起点(Map) -> 终点(Reduce)
Spark:有向无环图 起点 -> 第一阶段 -> 第二阶段 ->…->第n阶段 -> 终点
-
和MapReduce不同,MapReduce中间结果(溢写文件)会存储到磁盘,然后再开启下一轮的计算,计算的性能很大程度受限于磁盘的读写,而Spark的计算将任务拆分成若干个Stage,每个阶段的计算结果是可以缓存在内存中,因此在做迭代计算的时候,计算结果是可以复用的,因此极大降低因为重复计算所需的时间和磁盘读写对性能的消耗
-
Spark SQL可利用query optimizer优化用户SQL
课外读
MapReduce作为第一代大数据处理框架,在设计初期只是为了满足基于海量数据级的海量数据计算的迫切需求。自2006年剥离自Nutch(Java搜索引擎)工程,主要解决的是早期人们对大数据的初级认知所面临的问题。

整个MapReduce的计算实现的是基于磁盘的IO计算,随着大数据技术的不断普及,人们开始重新定义大数据的处理方式,不仅仅满足于能在合理的时间范围内完成对大数据的计算,还对计算的实效性提出了更苛刻的要求,因为人们开始探索使用Map Reduce计算框架完成一些复杂的高阶算法,往往这些算法通常不能通过1次性的Map Reduce迭代计算完成。由于Map Reduce计算模型总是把结果存储到磁盘中,每次迭代都需要将数据磁盘加载到内存,这就为后续的迭代带来了更多延长。
2009年Spark在加州伯克利AMP实验室诞生,2010首次开源后该项目就受到很多开发人员的喜爱,2013年6月份开始在Apache孵化,2014年2月份正式成为Apache的顶级项目。Spark发展如此之快是因为Spark在计算层方面明显优于Hadoop的Map Reduce这磁盘迭代计算,因为Spark可以使用内存对数据做计算,而且计算的中间结果也可以缓存在内存中,这就为后续的迭代计算节省了时间,大幅度的提升了针对于海量数据的计算效率。

Spark也给出了在使用MapReduce和Spark做线性回归计算(算法实现需要n次迭代)上,Spark的速率几乎是MapReduce计算10~100倍这种计算速度。

战略部署
Spark之所以这么快被程序员所接收,不仅仅单纯是因为Spark是一个基于内存的批处理框架,也和Spark的战略部署息息相关。不仅如此Spark在设计理念中也提出了One stack ruled them all战略,并且提供了基于Spark批处理之上的计算服务分支例如:Spark的交互查询、近实时流处理、机器学习、Grahx 图形关系计算等。
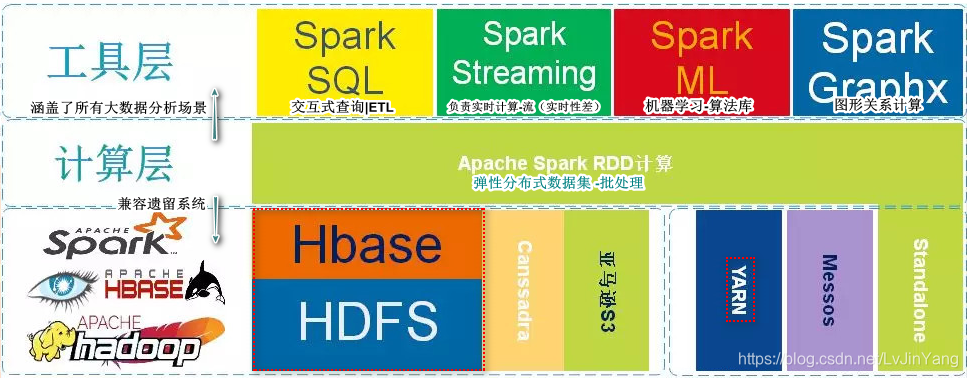
从图中不难看出Apache Spark处于计算层,Spark项目在战略上启到了承上启下的作用,并没有废弃原有以hadoop为主体的大数据解决方案。因为Spark向下可以计算来自于HDFS、HBase、Cassandra和亚马逊S3文件服务器的数据,也就意味着使用Spark作为计算层,用户原有的存储层架构无需改动。
计算架构
Spark的计算任务(Application等价MR中的Job)在集群中是以独立的进程集合的形式独立的计算,每一个任务都有自己进程(计算资源),这些计算资源由SparkContext对象负责统筹管理,该对象是由用户的主程序创建(入口main函数)- Driver Program。
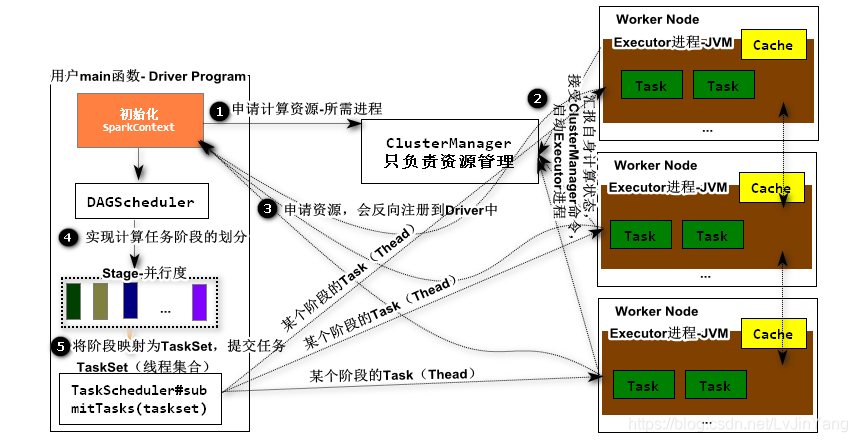
Application:等价于MapReduce中Job任务包含 Dirver和Executors进程
Driver:用户主程序,用于创建SparkContext,协调整个计算任务(等价 MRAppMaster)。
ClusterManager:主要负责集群的计算资源的管理,并不负责任务调度(等价ResourceManager)。
WorkerNode:泛指能够运行Apllication代码的集群中的机器。
Executor:每个Application任务都有自己的进程集合,这些进程负责运行Task(线程),并且存储计算中间结果。
Task:每个计算任务,会被划分为若干个Stage阶段,每个阶段都有并行度,并行度表示线程数目(Task数目)
Stage:每个任务会被划分为若干个阶段,每个都有自己的并行度,阶段与阶段之间有相互的依赖关系(RDD血统)
参考:http://spark.apache.org/docs/latest/cluster-overview.html
集群搭建
standalone(为主)
环境(CentOS6)
- 关闭防火墙
[root@CentOS ~]# service iptables stop # 关闭防火墙
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@CentOS ~]# chkconfig iptables off #关闭开机自启动
- 配置主机名和IP映射关系
[root@CentOS ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.12.142 CentOS
- 修改主机名
[root@CentOS ~]# cat /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=CentOS
重启CentOS系统
- 配置SSH免密码登陆
[root@CentOS ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
d7:22:ce:b2:2c:d6:ee:cd:50:4b:2f:ff:52:0b:7d:df root@CentOS
The key's randomart image is:
+--[ RSA 2048]----+
| |
| |
| |
| . |
| S o.. |
| = =..o . |
| .o = .o o ..|
| o..* o. . E|
| . += o .o. |
+-----------------+
[root@CentOS ~]# ssh-copy-id CentOS
The authenticity of host 'centos (192.168.12.142)' can't be established.
RSA key fingerprint is c8:64:53:f9:ed:e8:a4:2f:f7:13:cf:ad:59:68:c1:b8.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'centos,192.168.12.142' (RSA) to the list of known hosts.
root@centos's password:
Now try logging into the machine, with "ssh 'CentOS'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
- 安装JDK,配置JAVA_HOME
[root@CentOS ~]# rpm -ivh jdk-8u191-linux-x64.rpm
warning: jdk-8u191-linux-x64.rpm: Header V3 RSA/SHA256 Signature, key ID ec551f03: NOKEY
Preparing... ########################################### [100%]
1:jdk1.8 ########################################### [100%]
Unpacking JAR files...
tools.jar...
plugin.jar...
javaws.jar...
deploy.jar...
rt.jar...
jsse.jar...
charsets.jar...
localedata.jar...
[root@CentOS ~]# vi ~/.bashrc
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
[root@CentOS ~]# source .bashrc
[root@CentOS ~]# jps
1866 Jps
安装HDFS
[root@CentOS ~]# tar -zxf hadoop-2.9.2.tar.gz -C /usr/
[root@CentOS ~]# vi ~/.bashrc
HADOOP_HOME=/usr/hadoop-2.9.2
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
[root@CentOS ~]# source .bashrc
#测试是否配置成功(hdfs + Table键(应该是两下))
[root@CentOS ~]# hdfs
hdfs hdfs.cmd hdfs-config.cmd hdfs-config.sh
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/core-site.xml
<!--nn访问入口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://CentOS:9000</value>
</property>
<!--hdfs工作基础目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.9.2/hadoop-${user.name}</value>
</property>
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/slaves
CentOS
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
<!--block副本因子-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--配置Sencondary namenode所在物理主机-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>CentOS:50090</value>
</property>
<!--设置datanode最大文件操作数-->
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<!--设置datanode并行处理能力-->
<property>
<name>dfs.datanode.handler.count</name>
<value>6</value>
</property>
[root@CentOS ~]# hdfs namenode -format # 创建启动NameNode所需的fsimage文件
[root@CentOS ~]# start-dfs.sh
#测试是否启动成功
http://centos:50070
安装Spark
[root@CentOS ~]# tar -zxf spark-2.4.3-bin-without-hadoop.tgz -C /usr/
[root@CentOS ~]# mv /usr/spark-2.4.3-bin-without-hadoop/ /usr/spark-2.4.3
[root@CentOS ~]# cd /usr/spark-2.4.3/
[root@CentOS spark-2.4.3]# mv conf/slaves.template conf/slaves
[root@CentOS spark-2.4.3]# vi conf/slaves
CentOS
[root@CentOS spark-2.4.3]# mv conf/spark-env.sh.template conf/spark-env.sh
[root@CentOS spark-2.4.3]# vi conf/spark-env.sh
SPARK_MASTER_HOST=CentOS
SPARK_MASTER_PORT=7077
SPARK_WORKER_CORES=4
SPARK_WORKER_MEMORY=2g
SPARK_WORKER_INSTANCES=2
LD_LIBRARY_PATH=/usr/hadoop-2.9.2/lib/native
SPARK_DIST_CLASSPATH=$(hadoop classpath)
export SPARK_MASTER_HOST
export SPARK_MASTER_PORT
export SPARK_WORKER_CORES
export SPARK_WORKER_MEMORY
export SPARK_WORKER_INSTANCES
export LD_LIBRARY_PATH
export SPARK_DIST_CLASSPATH
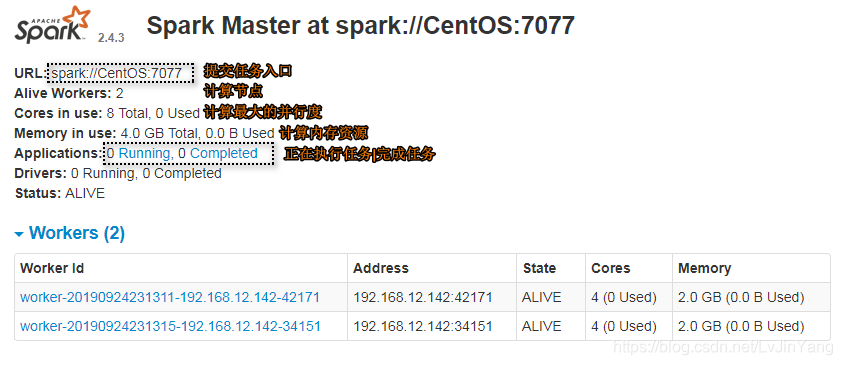
[root@CentOS spark-2.4.3]# ./sbin/start-all.sh #只有在Standalone模式下才需要启动
[root@CentOS spark-2.4.3]# jps
8064 Jps
2066 NameNode
2323 SecondaryNameNode
7912 Worker
7801 Master
7981 Worker
2157 DataNode
用户可以访问:http://centos:8080/
测试集群计算功能:
#准备计算文件
[root@CentOS ~]# vi t_words.txt
good good study
and day day up
come on baby
i am shy
[root@CentOS ~]# hdfs dfs -mkdir -p /demo/words
[root@CentOS ~]# hdfs dfs -copyFromLocal /root/t_words.txt /demo/words
[root@CentOS spark-2.4.3]# ./bin/spark-shell
--master spark://CentOS:7077 # 连接集群Master
--deploy-mode client # Diver运行方式,必须是client
--total-executor-cores 4 # 计算资源
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://CentOS:4040
Spark context available as 'sc' (master = spark://CentOS:7077, app id = app-20190924232452-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_191)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc.textFile("hdfs:///demo/words")
.flatMap(_.split(" "))
.map((_,1))
.groupBy(t=>t._1)
.map(t=>(t._1,t._2.size))
.sortBy(t=>t._2,false,4)
.saveAsTextFile("hdfs:///demo/results")
YARN(了解)
环境(CentOS6)
- 关闭防火墙
[root@CentOS ~]# service iptables stop # 关闭防火墙
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@CentOS ~]# chkconfig iptables off #关闭开机自启动
- 配置主机名和IP映射关系
[root@CentOS ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.12.142 CentOS
- 修改主机名
[root@CentOS ~]# cat /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=CentOS
重启CentOS系统
- 配置SSH免密码登陆
[root@CentOS ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
d7:22:ce:b2:2c:d6:ee:cd:50:4b:2f:ff:52:0b:7d:df root@CentOS
The key's randomart image is:
+--[ RSA 2048]----+
| |
| |
| |
| . |
| S o.. |
| = =..o . |
| .o = .o o ..|
| o..* o. . E|
| . += o .o. |
+-----------------+
[root@CentOS ~]# ssh-copy-id CentOS
The authenticity of host 'centos (192.168.12.142)' can't be established.
RSA key fingerprint is c8:64:53:f9:ed:e8:a4:2f:f7:13:cf:ad:59:68:c1:b8.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'centos,192.168.12.142' (RSA) to the list of known hosts.
root@centos's password:
Now try logging into the machine, with "ssh 'CentOS'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
- 安装JDK,配置JAVA_HOME
[root@CentOS ~]# rpm -ivh jdk-8u191-linux-x64.rpm
warning: jdk-8u191-linux-x64.rpm: Header V3 RSA/SHA256 Signature, key ID ec551f03: NOKEY
Preparing... ########################################### [100%]
1:jdk1.8 ########################################### [100%]
Unpacking JAR files...
tools.jar...
plugin.jar...
javaws.jar...
deploy.jar...
rt.jar...
jsse.jar...
charsets.jar...
localedata.jar...
[root@CentOS ~]# vi ~/.bashrc
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
[root@CentOS ~]# source .bashrc
[root@CentOS ~]# jps
1866 Jps
安装HDFS
[root@CentOS ~]# tar -zxf hadoop-2.9.2.tar.gz -C /usr/
[root@CentOS ~]# vi ~/.bashrc
HADOOP_HOME=/usr/hadoop-2.9.2
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
[root@CentOS ~]# source .bashrc
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/core-site.xml
<!--nn访问入口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://CentOS:9000</value>
</property>
<!--hdfs工作基础目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.9.2/hadoop-${user.name}</value>
</property>
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/slaves
CentOS
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
<!--block副本因子-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--配置Sencondary namenode所在物理主机-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>CentOS:50090</value>
</property>
<!--设置datanode最大文件操作数-->
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<!--设置datanode并行处理能力-->
<property>
<name>dfs.datanode.handler.count</name>
<value>6</value>
</property>
[root@CentOS ~]# hdfs namenode -format # 创建启动NameNode所需的fsimage文件
[root@CentOS ~]# start-dfs.sh
安装YARN
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/yarn-site.xml
<!--配置MapReduce计算框架的核心实现Shuffle-洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置资源管理器所在的目标主机-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>CentOS</value>
</property>
<!--关闭物理内存检查-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--关闭虚拟内存检查-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
[root@CentOS ~]# mv /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml.template /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml
[root@CentOS ~]# vi /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml
<!--MapRedcue框架资源管理器的实现-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
[root@CentOS ~]# start-yarn.sh
安装Spark
[root@CentOS ~]# tar -zxf spark-2.4.3-bin-without-hadoop.tgz -C /usr/
[root@CentOS ~]# mv /usr/spark-2.4.3-bin-without-hadoop/ /usr/spark-2.4.3
[root@CentOS ~]# cd /usr/spark-2.4.3/
[root@CentOS spark-2.4.3]# mv conf/spark-env.sh.template conf/spark-env.sh
[root@CentOS spark-2.4.3]# vi conf/spark-env.sh
HADOOP_CONF_DIR=/usr/hadoop-2.9.2/etc/hadoop
YARN_CONF_DIR=/usr/hadoop-2.9.2/etc/hadoop
SPARK_EXECUTOR_CORES=4
SPARK_EXECUTOR_MEMORY=1g
SPARK_DRIVER_MEMORY=1g
LD_LIBRARY_PATH=/usr/hadoop-2.9.2/lib/native
SPARK_DIST_CLASSPATH=$(hadoop classpath)
export HADOOP_CONF_DIR
export YARN_CONF_DIR
export SPARK_EXECUTOR_CORES
export SPARK_DRIVER_MEMORY
export SPARK_EXECUTOR_MEMORY
export LD_LIBRARY_PATH
export SPARK_DIST_CLASSPATH
这里和standalone不同,用户无需启动start-all.sh服务,因为任务的执行会交给Yarn执行
[root@CentOS spark-2.4.3]# ./bin/spark-shell
--master yarn # 连接集群Master
--deploy-mode client # Diver运行方式,必须是client
--executor-cores 4 # 每个进程最多运行两个Core
--num-executors 2 # 分配2个Executor进程
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
19/09/25 00:14:40 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
19/09/25 00:14:43 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:980)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:630)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:807)
Spark context Web UI available at http://CentOS:4040
Spark context available as 'sc' (master = yarn, app id = application_1569341195065_0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_191)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc.textFile("hdfs:///demo/words")
.flatMap(_.split(" "))
.map((_,1))
.groupBy(t=>t._1)
.map(t=>(t._1,t._2.size))
.sortBy(t=>t._2,false,4)
.saveAsTextFile("hdfs:///demo/results")
更多请参考:https://blog.csdn.net/weixin_38231448/article/details/89382345
任务发布与部署
远程Jar发布
添加Spark开发依赖
<properties>
<spark.version>2.4.3</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
<!--用于告知Maven在打jar包的时候,剔除该包-->
<scope>provided</scope>
</dependency>
package demo1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {//Driver
//1、创建SparkContext
val sparkConf = new SparkConf()
.setAppName("wordCount")
.setMaster("spark://CentOS:7077")
val sc = new SparkContext(sparkConf)
//2、创建分布式集合RDD
val lines:RDD[String] = sc.textFile("hdfs:///demo/words")
//3、对数据集合做转换
val transforeRDD:RDD[(String,Int)] = lines.flatMap(_.split(" "))
.map((_, 1))
.groupBy(_._1)
.map(t => (t._1, t._2.size))
.sortBy(t => t._2, false, 4)
//4、对RDD做Action动作提交任务
transforeRDD.saveAsTextFile("hdfs:///demo/results")
//5.释放资源
sc.stop()
}
}
添加Maven插件
<!--在执行package时候,将scala源码编译进jar-->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.0.1</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<!--将依赖jar打入到jar中-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
执行Maven打包指令
mvn -package
在项目的target目录下会产生两个jar
original-xxx-1.0-SNAPSHOT.jar //没有第三方依赖
xxxx-1.0-SNAPSHOT.jar //除provide以外的所有jar都会打包进来,fatjar
使用spark-submit指令提交spark任务
[root@CentOS spark-2.4.3]# ./bin/spark-submit
--master spark://CentOS:7077
--deploy-mode cluster
--class com.baizhi.demo01.SparkWordCount
--driver-cores 2
--total-executor-cores 4
/root/rdd-1.0-SNAPSHOT.jar
本地测试
package demo2
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
//1、创建SparkContext
val sparkConf = new SparkConf()
.setAppName("wordCount")
.setMaster("local[6]")
val sc = new SparkContext(sparkConf)
//2、创建分布式集合RDD
val lines:RDD[String] = sc.textFile("file:///E:demo/words")
//3、对数据集合做转换
val transfromRDD:RDD[(String,Int)] = lines.flatMap(_.split(" "))
.map((_, 1))
.groupBy(_._1)
.map(t => (t._1, t._2.size))
.sortBy(t => t._2, true, 4)
//4、对RDD做Action动作提交任务
transfromRDD.saveAsTextFile("file:///E:demo/results")//文件夹不能直接在盘符下 E:results不行
//5、释放资源
sc.stop()
}
}
直接本地运行,不需要Spark环境,注意注释掉
<scope>provide</scope>
./bin/spark-shell
--master local[6] # 连接集群Master
--deploy-mode client # Diver运行方式,必须是client
--total-executor-cores 4 # 计算资源
[root@CentOS spark-2.4.3]# ./bin/spark-shell --master local[6] --deploy-mode client --total-executor-cores 4
History Server
用于记录任务执行的历史状态信息。通常任务在执
添加spark-env.sh
[root@CentOS spark-2.4.3]# vi conf/spark-env.sh
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs:///spark-logs"
export SPARK_HISTORY_OPTS
修改spark-defaults.conf
[root@CentOS spark-2.4.3]# mv conf/spark-defaults.conf.template conf/spark-defaults.conf
[root@CentOS spark-2.4.3]# vi conf/spark-defaults.conf
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs:///spark-logs
在HDFS上创建spark-logs目录,用于history服务器存储数据的地方。
[root@CentOS ~]# hdfs dfs -mkdir /spark-logs
启动history server
[root@CentOS spark-2.4.3]# ./sbin/start-history-server.sh
测试历史服务:http://centos:18080
RDD编程指南(重点中的重点)
OverView(概述)
俯视整个Spark程序,所有Spark的Application都包含一个Driver程序,该程序是用户的主函数以及在集群中执行各种各样的并行操作。Spark中提出了一个核心的概念,resilient distributed dataset(RDD),RDD是一个并行的分布式集合,该集合的数据可以跨节点存储,所有的RDD操作都是在集群的计算节点中并行的执行。RDD可以直接通过Hadoop的文件系统创建,或者所有Hadoop支持的文件系统创建,也可以通过在主函数中定义的Scala集合创建。Spark可以将RDD中的收据缓存在内存中,这样在后续的分布式计算中可以重复使用,提成程序的运行效率,其次RDD可以在计算节点故障的时候进行故障恢复。(RDD的创建、RDD的缓存、RDD的故障恢复)
基本结构
//1、创建SparkContext
val sparkConf = new SparkConf()
.setAppName("wordCount")//【任务的名字,不可省略】
.setMaster("local[6]")//【任务的计算类型,不可省略】 spark:// yarn local
val sc = new SparkContext(sparkConf)
//2、创建分布式集合RDD(将外围系统的数据加载为RDD数据集合)
val lines:RDD[String] = sc.textFile("file:///E:demo/words")
//3、对数据集合做转换(RDD集合的转换算子【N多个】,负责计算,他们都是lazy方式执行)
val transfromRDD:RDD[(String,Int)] = lines.flatMap(_.split(" "))
.map((_, 1))
.groupBy(_._1)
.map(t => (t._1, t._2.size))
.sortBy(t => t._2, true, 4)
//4、对RDD做Action动作提交任务(RDD集合的动作算子【一个】,触发任务的提交)
transfromRDD.saveAsTextFile("file:///E:demo/results")//文件夹不能直接在盘符下 E:results不行
//5、释放资源
sc.stop()
任意的Spark程序,可以有一到N个转换算子,有且只有一个动作算子
所有转化算子的返回值类型一定是RDD
动作算子的返回值类型一般是Unit或者是本地集合(比如Array,List)
RDD的创建
RDD是一个并行的带有容错的分布式数据集,创建一个RDD的方式总体上来说有两种。一、将scala的本地集合并行化为一个RDD,二、通过外围系统的数据集创建,一般要使用Hadoop的InputFormat
集合构建RDD(测试)
import org.apache.spark.rdd.RDD
val lines = List("this is a demo","hello word","good good")
var linesRDD:RDD[String] = sc.parallelize(lines,3)//3代表分区数,将数据均匀分散
linesRDD.getNumPartitions
//使用makeRDDL创建
val lines = List("this is a demo","hello word","good good")
var linesRDD:RDD[String] = sc.makeRDD(lines,3)
外围系统数据集(掌握 )
- textFile
val lines:RDD[String] = sc.textFile("hdfs:///demo/words",10)
.map(_.length).collect //字符的长度包括空格
.map(_.split(" ")).collect //
这里的file表示读取本地文件,如果需要读取HDFS,请指定为hdfs://
如果读取的文本数据来自HDFS,一般不需要指定分区数,如果用户不指定分区数,文件并行加载的并行度默认等于文件的块的数目
如果用户指定分区数,该分区数必须大于目标文件的Block数目
-
wholeTextFiles
val wholeFileRDD:RDD[(String,String)]=sc.wholeTextFiles("hdfs:///demo/words") val linesRDD=wholeFileRDD.flatMap(t=>t._2.split("\n")) .flatMap(line => line.spilt(" ")).collect -
newAPIHadoopRDD(MySQL)
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
package demo3
import java.sql.{PreparedStatement, ResultSet}
import org.apache.hadoop.mapreduce.lib.db.DBWritable
class FlowDBWRiteable extends DBWritable{
var id:String = _
var name:String = _
var tel:String = _
var email:String = _
//写出
override def write(preparedStatement: PreparedStatement): Unit = {
}
//读入
override def readFields(resultSet: ResultSet): Unit = {
id = resultSet.getString("id")
name = resultSet.getString("name")
tel = resultSet.getString("tel")
email = resultSet.getString("email")
}
}
package demo3
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.io.LongWritable
import org.apache.hadoop.mapreduce.lib.db.{DBConfiguration, DBInputFormat}
import org.apache.spark.{SparkConf, SparkContext}
object SparkNewHadoopAPI {
def main(args: Array[String]): Unit = {
//1、创建SparkContext
val sparkConf = new SparkConf()
.setAppName("wordCount")
.setMaster("local[6]")
val sc = new SparkContext(sparkConf)
//2、创建分布式集合RDD
//mysql连接参数
val hConf = new Configuration()
DBConfiguration.configureDB(hConf,"com.mysql.jdbc.Driver",
"jdbc:mysql://localhost:3306/vue",
"root",
"root")
hConf.set(DBConfiguration.INPUT_COUNT_QUERY,"select count(*) from t_user")
hConf.set(DBConfiguration.INPUT_QUERY,"select * from t_user")
hConf.set(DBConfiguration.INPUT_CLASS_PROPERTY,"demo3.FlowDBWRiteable")
val userRDD = sc.newAPIHadoopRDD(hConf,
classOf[DBInputFormat[FlowDBWRiteable]],
classOf[LongWritable],
classOf[FlowDBWRiteable])
userRDD
//3、对RDD数据集合做转换
val finalRDD = userRDD.map(t =>(t._1.get(),t._2.tel,t._2.id,t._2.email,t._2.name))
//4、对RDD做Action动作提交任务
finalRDD.collect().foreach(println)
//5、释放资源
sc.stop()
}
}
-
√hbase读取
准备工作
-
安装zookeeper
[root@CentOS ~]# tar -zxf zookeeper-3.4.6.tar.gz -C /usr/ [root@CentOS ~]# cp /usr/zookeeper-3.4.6/conf/zoo_sample.cfg /usr/zookeeper-3.4.6/conf/zoo.cfg [root@CentOS ~]# vi /usr/zookeeper-3.4.6/conf/zoo.cfg dataDir=/root/zkdata [root@CentOS zookeeper-3.4.6]# ./bin/zkServer.sh start zoo.cfg #看一下状态 [root@CentOS zookeeper-3.4.6]# ./bin/zkServer.sh status zoo.cfg JMX enabled by default Using config: /usr/zookeeper-3.4.6/bin/../conf/zoo.cfg Mode: standalone -
安装HBase
[root@CentOS zookeeper-3.4.6]# cd [root@CentOS ~]# tar -zxf hbase-1.2.4-bin.tar.gz -C /usr/ [root@CentOS ~]# cd /usr/hbase-1.2.4/ [root@CentOS hbase-1.2.4]# vi conf/hbase-env.sh [root@CentOS hbase-1.2.4]# export HBASE_MANAGES_ZK=false [root@CentOS hbase-1.2.4]# vi /usr/hbase-1.2.4/conf/hbase-site.xml<property> <name>hbase.rootdir</name> <value>hdfs:///hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>CentOS</value> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property>[root@CentOS hbase-1.2.4]# vi /usr/hbase-1.2.4/conf/regionservers CentOS [root@CentOS hbase-1.2.4]# ./bin/start-hbase.sh-
检查是否成功
http://centos:16010 http://centos:50070 #有HBase的hdfs文件插入测试数据
[root@CentOS hbase-1.2.4]# ./bin/hbase shell hbase(main):005:0> create_namespace 'baizhi' 0 row(s) in 0.4020 seconds hbase(main):006:0> create 'baizhi:t_user','cf1','cf2' 0 row(s) in 1.3320 seconds => Hbase::Table - baizhi:t_user hbase(main):007:0> put 'baizhi:t_user','001','cf1:name','zhangsan' 0 row(s) in 0.2400 seconds hbase(main):008:0> put 'baizhi:t_user','002','cf1:name','li' hbase(main):009:0> scan 'baizhi:t_user' ROW COLUMN+CELL 001 column=cf1:name, timestamp=1569394762806, value=zhangsan 002 column=cf1:name, timestamp=1569394802018, value=li 2 row(s) in 0.0380 seconds
-
-
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
<!--<scope>provided</scope>-->
<exclusions>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.9.2</version> </dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.4</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.4</version>
</dependency>
package demo4
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HConstants
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.{SparkConf, SparkContext}
object SparkNewHadoopAPI {
def main(args: Array[String]): Unit = {
//1、创建SparkContext
val spakConf = new SparkConf()
.setAppName("wordCount")
.setMaster("local[6]")
val sc = new SparkContext(spakConf)
//2、创建分布式集合RDD
val hConf = new Configuration()
hConf.set(HConstants.ZOOKEEPER_QUORUM,"CentOS")
hConf.set(TableInputFormat.INPUT_TABLE,"baizhi:t_user")
val userRDD = sc.newAPIHadoopRDD(hConf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result])
//3、4、分布式集合RDD的转换和Action动作提交
userRDD.map(
t => {
val key = Bytes.toString(t._1.get())
val name = Bytes.toString(t._2.getValue("cf1".getBytes(),"name".getBytes()))
(key,name)
}
).collect().foreach(println)
//5、释放资源
sc.stop()
}
}
-
Redis读入
准备工作,安装Redis
#如果没有gcc的话要装gcc yum install -y gcc 472 tar -zxf redis-3.2.9.tar.gz 473 ll 474 cd redis-3.2.9 475 make && make install 如果出现错误:zmalloc.h:50:31: 错误:jemalloc/jemalloc.h:没有那个文件或目录 make MALLOC=libc make install 476 cd /usr/local/bin/ [root@hadoop bin]# cp /root/redis-3.2.9/redis.conf /usr/local/bin/ [root@hadoop bin]# vi redis.conf # 开启redis远程访问 bind 0.0.0.0 启动redis服务 [root@hadoop ~]# cd /usr/local/bin/ [root@hadoop bin]# redis-server redis.conf 启动redis客户端 [root@hadoop bin]# redis-cli 关闭redis服务 [root@hadoop bin]# redis-cli shutdown 查看是否成功 127.0.0.1:6379> keys * flushdb#清空库 select 1#选择1号库 hgetall wordcount#查看hash编码的Wordcount中的数据package redis import redis.clients.jedis.Jedis object Jedis { def createConnection(): Jedis = { new Jedis("192.168.108.150", 6379) } val conn:Jedis=createConnection() Runtime.getRuntime.addShutdownHook(new Thread(){ override def run(): Unit = { println("=-===close=====") conn.close() } }) }package redis import org.apache.spark.{SparkConf, SparkContext} object SparkWord2Redis { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf() .setAppName("wordcount") .setMaster("local[6]") val sc = new SparkContext(sparkConf) sc.textFile("file:///E:/demo/h") .flatMap(_.split("\\s+")) .map((_,1)) .reduceByKey(_+_) .foreachPartition(wordpairs =>{ val jedis = Jedis.createConnection() wordpairs.foreach(wordpair=>{ //写入到Redis jedis.set(wordpair._1,wordpair._2.toString) }) }) sc.stop() } }
RDD剖析
RDD是一个弹性的 分布式 数据集 ,弹性强调的RDD的容错。默认情况下RDD有三种容错策略:
-
RDD重复计算-默认策略,一旦计算过程中系统出错了,系统可以根据RDD的转换去追溯上游RDD,逆推出RDD计算过程。之所以RDD能够逆推出上游RDD(父RDD),主要是因为Spark会记录RDD之间依赖关系(RDD血统) -
由于重复计算成本较高,因此Spark提供了
缓存机制,用于存储计算的中间结果,有利于在故障时期能够快速的故障恢复,提升计算效率,如果某些计算需要重复使用也可以使用RDD缓存机制去优化。 -
由于缓存存在时效问题,如果当RDD缓存失效了,一旦故障,系统依然需要重复计算。因此针对一些比较耗时且计算成本比较高的计算,Spark提供了一种更安全可靠机制称为
Checkpoint,缓存一般具有时间限制,长时间不使用会失效,但是CheckPoint不同,CheckPoint机制会将RDD的计算结果直接持久化到磁盘中,被CheckPoint的数据,会一直持久化到磁盘中,除非手动删除。
分布式(各司其职)强调的是Stage阶段的划分,Spark会尝试将一个任务拆分成若干个阶段,所有的计算都会按照Stage划分,有条不紊的执行。Spark在对任务划分时根据RDD间的相互依赖关系划分任务的阶段。Spark中RDD的依赖关系称为RDD的血统-lineage。RDD血统依赖又分为两种依赖形式宽依赖/窄依赖如果遇到窄依赖系统会尝试将RDD的转换规定为一个Stage,如果是宽依赖 Spark会产生新的Stage。
数据集:强调的是RDD操作简单和易用性,操作并行集合就等价于操作Scala的本地集合这么简单。
- 代码分析

上诉代码通过textFile创建RDD并且指定分区数,如果不指定系统默认会按照HDFS上的Block的数目计算分区,该参数不能小于Block的数目。然后使用可flatMap,map算子对分区数据做转换,不难看出Spark将textFile->flatMap->map规划为了一个State0,在执行到reduceByKey转换的时候将开始又划分出State1在执行到collect动作算子的时候,Spark任务提交,并且内部通过DAGScheduler计算出了state0和state1两个状态。
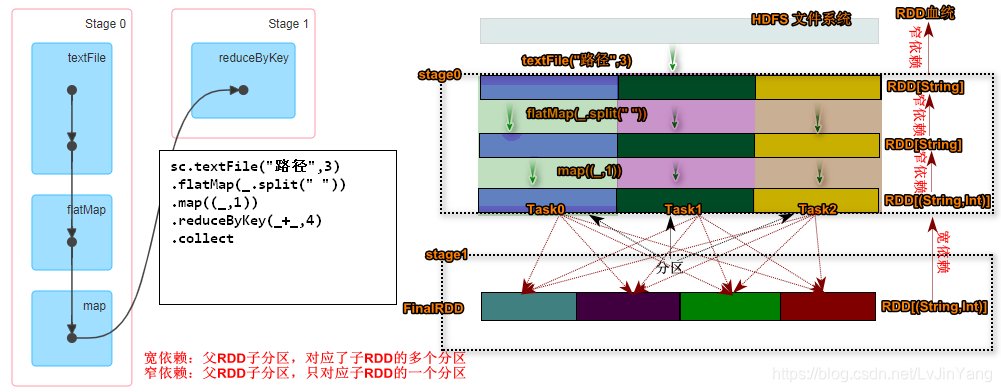
RDD容错
在理解DAGSchedule如何做状态划分的前提是需要大家了解一个专业术语lineage通常被人们称为RDD的血统。在了解什么是RDD的血统之前,先来看看程序猿进化过程。

上图中描述了一个程序猿起源变化的过程,我们可以近似的理解类似于RDD的转换过程,Spark的计算本质就是对RDD做各种转换,由于RDD是一个不可变带有分区只读的集合,因此每次的转换都需要上一次的RDD数据作为本次转换的输入,因此RDD的lineage描述的是RDD间的相互依赖关系。为了保证RDD中数据的健壮性,RDD数据集通过所谓的血统关系(Lineage)记住了它是如何从其它RDD中转换过来的。Spark将RDD之间的关系归类为宽依赖和窄依赖。Spark会根据Lineage存储的RDD的依赖关系对RDD计算做故障容错,目前Saprk的容错策略根据RDD依赖关系重新计算、RDD做Cache、RDD做Checkpoint手段完成RDD计算的故障容错。
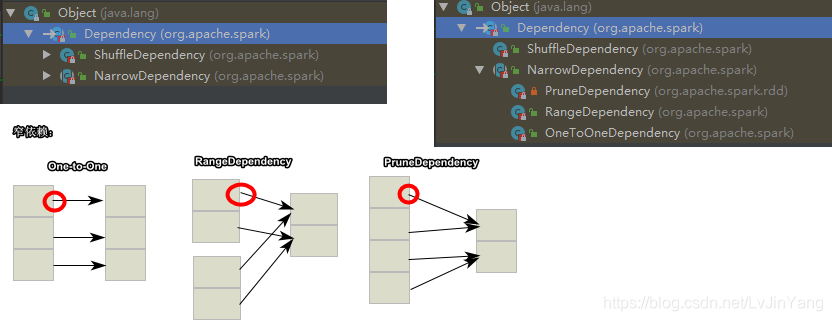
宽依赖|窄依赖
RDD在Lineage依赖方面分为两种Narrow Dependencies与Wide Dependencies用来解决数据容错的高效性。Narrow Dependencies是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于子RDD的一个分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。Wide Dependencies父RDD的一个分区对应一个子RDD的多个分区。Spark在任务的提交的时候会调用DAGScheduler方法根据最后一个RDD逆向推导出任务的阶段(根据宽、窄依赖)。
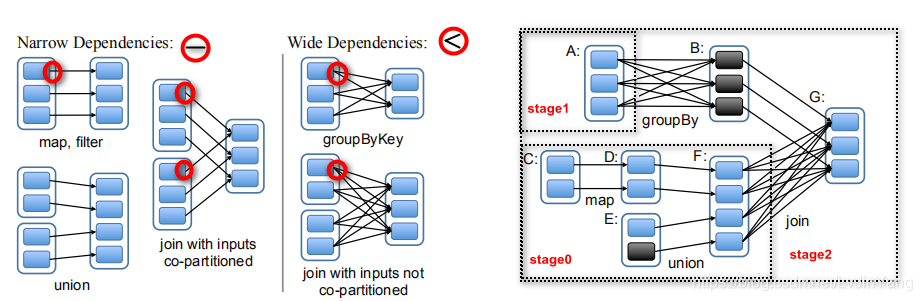
RDD缓存
缓存是一种RDD计算容错的一种手段,程序在RDD数据丢失的时候,可以通过缓存快速计算当前RDD的值,而不需要反推出所有的RDD重新计算,因此Spark在需要对某个RDD多次使用的时候,为了提高程序的执行效率用户可以考虑使用RDD的cache。
//1.创建SparkContext
val sparkConf = new SparkConf()
.setAppName("wordcount")
.setMaster("local[6]")
val sc = new SparkContext(sparkConf)
//2.创建分布式集合RDD -细化
val lines:RDD[String] = sc.textFile("file:///D:/demo/words")
val cacheRDD = lines.flatMap(_.split(" "))//缓存数据
.map((_, 1))
.persist(StorageLevel.MEMORY_ONLY)
//执行聚合
cacheRDD.reduceByKey(_ + _, 4).collect()
var start=System.currentTimeMillis()
for(i <- 0 to 100){//测试时间
cacheRDD.reduceByKey(_ + _, 4).collect()
}
var end=System.currentTimeMillis()
//5.释放资源
sc.stop()
println("总耗时:"+(end-start))
清楚缓存
cacheRDD.unpersist()
思考,面对大规模数据集,直接将RDD数据缓存在内存中是否会导致内存溢出?
默认Spark的cache方法是用内存缓存的RDD中数据,这样可以极大提升程序运行效率,但是面对大规模数据集合可能导致计算的节点产生OOM(Out of Memory),如果数据经过转换后数据量级依然很大,这个时候不建议是用cache方法,Spark提供下一的存储机制。
rdd#cache <==> rdd.persist(StorageLevel.MEMORY_ONLY)
默认情况下,用户是用cache就等价于使用 rdd.persist(StorageLevel.MEMORY_ONLY),事实上Spark还提供其它的存储策略,用于节省内存空间以及缓存数据的备份。
StorageLevel.MEMORY_ONLY # 直接将RDD只存储到内存,效率高,占用空间大
StorageLevel.MEMORY_ONLY_2 # 直接将RDD只存储到内存,效率高,占用空间大,并且存储两份
StorageLevel.MEMORY_ONLY_SER # 将RDD先进行序列化,效率相对较低,占用空间稍微小
StorageLevel.MEMORY_ONLY_SER_2 # 将RDD先进行序列化,效率相对较低,占用空间稍微小,并且存储两份
StorageLevel.MEMORY_AND_DISK
StorageLevel.MEMORY_AND_DISK_2
StorageLevel.MEMORY_AND_DISK_SER
StorageLevel.MEMORY_AND_DISK_SER_2 # 不确定情况下,一般使用该种缓存策略
StorageLevel.DISK_ONLY # 基于磁盘存储
StorageLevel.DISK_ONLY_2
StorageLevel.DISK_ONLY_SER
StorageLevel.DISK_ONLY_SER_2
RDD五大特征
- RDD是带有分区(切片split)的不可变数据集合
- 所有RDD转换计算都是在分区内部执行的
- RDD之间存在着相互依赖关系,这种关系称为RDD血统lineage
sc.textFile().
宽依赖:一个 父RDD有多个子RDD【map,filter,union】,做故障恢复代价较高
窄依赖:一个父RDD只有一个子RDD【groupByKey】,做故障恢复代价较低
(面试)Check Point(检查点)
除了使用缓存机制可以有效的保证RDD的故障恢复,但是如果缓存失效还是会在导致系统重新计算RDD的结果,所以对于一些RDD的lineage较长的场景,计算比较耗时,用户可以尝试使用checkpoint机制存储RDD的计算结果,该种机制和缓存最大的不同在于,使用checkpoint之后被checkpoint的RDD数据直接持久化在文件系统中,一般推荐将结果写在hdfs中,这种checpoint并不会自动清空。缓存的数据是在计算的时候将结果立即换存,但是checkpoint不同,并不是在任务计算过程中立即做checkpoint,仅仅是对需要check的RDD做标记,等到计算结束之后再开始对标记的RDD做重复计算,这个时候才会将数据持久化到磁盘。
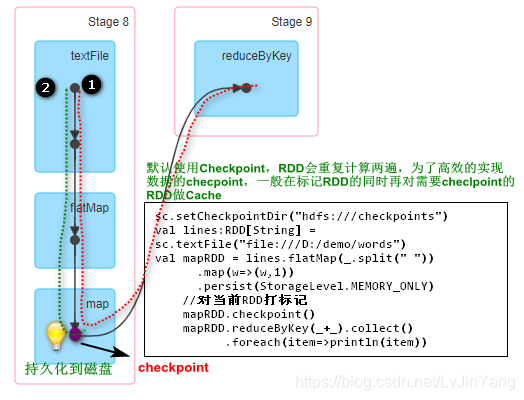
缓存临时存储在内存中,但是检查点持久化存储默认使用CheckPoint,RDD会重复计算两遍,为了高效的实现数据的CheckPoint,一般在标记RDD的同时就对需要CheckPoint的RDD做Cache,直接用缓存就行了。正确的CheckPoint的方式是先做缓存再做CheckPoint,CheckPoint只是给本次应用使用的,只是在本次应用过程中做故障恢复
scala> sc.setCheckpointDir("hdfs:///checkpoints")
scala> val mapRDD=sc.textFile("hdfs:///demo/words/").flatMap(_.split(" ")).map((_,1)).cache()
scala> mapRDD.checkpoint()
scala> mapRDD.reduceByKey(_+_,4).collect
scala> mapRDD.unpersisit() # 删除/demo/words/
scala> mapRDD.reduceByKey(_+_,4).collect #正常,之后删除checkpoints数据
批处理的CheckPoint
先创建目录
打标记
操作
移除数据同时清空缓存
从CheckPoint恢复
再删除CHeckPoint,报错
正常不会缓存,会反推重头计算,
考点:注意区分checpoint和缓存的区别。
(面试出彩)Stage划分源码剖析(略)
【先了解架构,再根据架构】
**【MapReduce】**InputFormat OutputFormat Shuffle(map buffer,store。。。)
totalExcutor cores指定所需资源
创建SparkContext【负责整个类的调度】(为了初始化SparkContext对象)
初始化的代码块try363行
构建类时一定加载的代码块
克隆,校验
部署模式
反向注册什么是么时候
taskScheduler任务调度器
SparkContext.createTaskScheduler做几个模式匹配(local),区别在于scheulerBackend不一样
加载本地CPU的核数
如果local[*]作为本地CPU的核数
模式到spark,解析到SparkUrl,匹配出IP和端口
拿到StandalonescheulerBackend
最终返回三个重量级的类
创建的几个重量级的类
一、schedulerBackend负责连接后端计算资源 494行
二、taskScheduler负责阶段任务调度
三、DAGScheduler负责阶段任务划分
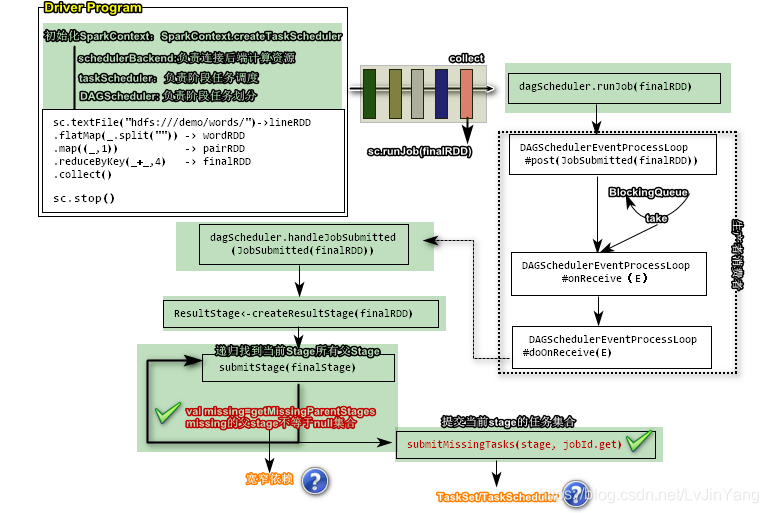
sc.textFile("hdfs:///demo/words") ->lineRDD
.flatMap(_.split(" ")) ->wordRDD
.map((_, 1)) ->pairRDD
.reduceBykey(_+_,4) ->finalRDD
.collect()/*触发动作,只负责将远程的结构拿给Driver,只能出现一次,
会调runJob传的是finalRDD;
runJob中调用dagScheduler.runJob(finalRDD);
点submitJob
eventProcessLoop(DAGScheduler的成员,基于生产者消费者模式【生产者和消费者不在一个线程】)
DAGSchedulerEventProcessLoop.post(submitted(finalRDD))
BlockingQueue放数据
eventQUeue数组集合(放的都是event事件)队列缓冲解耦
成员变量eventThread线程
不停eventQUeue.take()消费
onReceive中调doOnReceive(event)
doOnReceive中调了dagScheduler.handleJobSubmitted(JobSubmitted(finalRDD))
一、首先根据finalRDD创建一个阶段 **ResultStage**
ResultStage < - creatResultStage(finalRDD)
**SubmitStage**(finalStage)涉及到递归 //提交stage要循环找到丢失的父Stage,递归找到当前Stage的所有父Stage
1、
val missing = getMissingParentStages(stage)
if(!missing.isEmpty)//递归找到Stage的所有父stage【**涉及到宽窄依赖**】
if(missing.isEmpty) {
submitMissingTasks(stage,jobId.get)//提交当前stage的任务集合【**TaskSet/TaskScheduler**】
}
*/
sc.stop()
getMissingParentStages
newHashSet//存储当前stage的父stage
计算分区数()线程数是
查找分区最佳位置
封装taskSet tasks。toArray
将当前stage标记为完成stage
submitWaitingChildStages
考点:注意区分checpoint和缓存的区别。
/**
* Create a task scheduler based on a given master URL.
基于给定的master url创建任务调度程序。
* Return a 2-tuple of the scheduler backend and the task scheduler.
基于给定的主URL创建任务计划程序。返回schedulerBackend和taskScheduler的2元组。
*/
private def createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._
// When running locally, don't try to re-execute tasks on failure.
// 在本地运行时,不要尝试在失败时重新执行任务
val MAX_LOCAL_TASK_FAILURES = 1
.....
case masterUrl =>
val cm = getClusterManager(masterUrl) match {
case Some(clusterMgr) => clusterMgr
case None => throw new SparkException("Could not parse Master URL: '" + master + "'")
}
try {
val scheduler = cm.createTaskScheduler(sc, masterUrl)
val backend = cm.createSchedulerBackend(sc, masterUrl, scheduler)
cm.initialize(scheduler, backend)
(backend, scheduler)
} catch {
case se: SparkException => throw se
case NonFatal(e) =>
throw new SparkException("External scheduler cannot be instantiated", e)
}
}
}
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
if (missing.isEmpty) {
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage //需要将当前的Stage存储到waitingStages
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
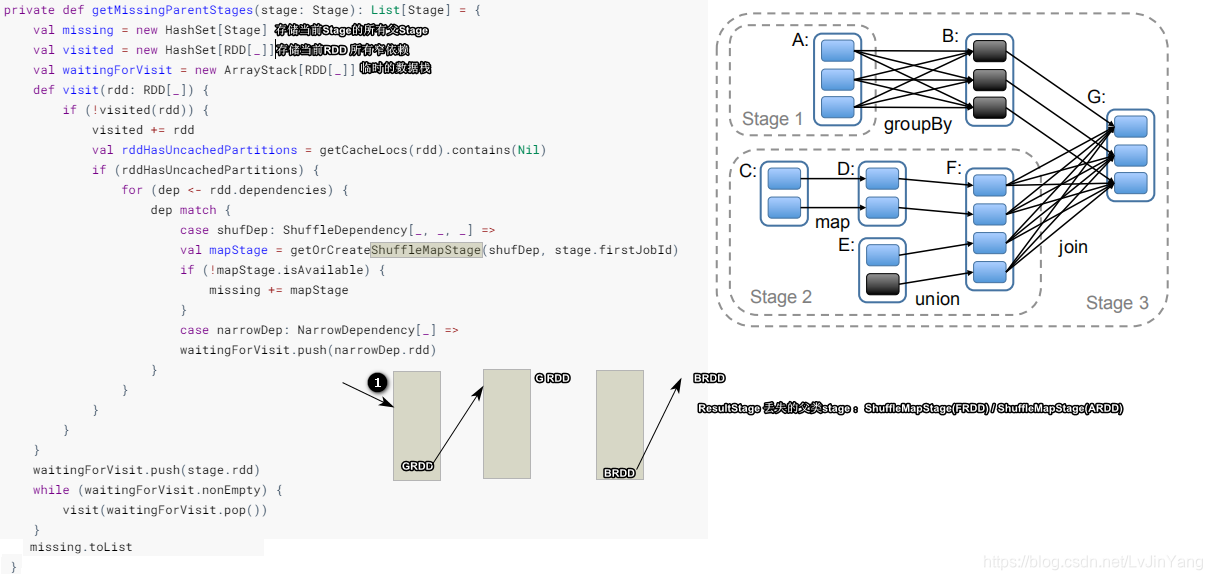
ShuffleDependency|NarrowDependency ResultStage|ShuflleMapStage
private def submitMissingTasks(stage: Stage, jobId: Int) {
//计算分区
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
...
//把当前Stage添加到运行runningStages
runningStages += stage
...
//更具分区计算任务最优位置
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
...
//封装任务集合
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
...
//提交任务集
if (tasks.size > 0) {
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
} else {
//标记任务已完成
markStageAsFinished(stage, None)
stage match {
case stage: ShuffleMapStage =>
logDebug(s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})")
markMapStageJobsAsFinished(stage)
case stage : ResultStage =>
logDebug(s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})")
}
//计算当前Stage的所有子stage
submitWaitingChildStages(stage)
}
}
ShuffleMapTask|ResultTask`
RDD算子实战
RDD支持两种类型的操作:transformations(从现有数据集创建新数据集)和actions(在数据集上运行计算后将值返回给驱动程序)。例如,“map”是一个转换,它通过一个函数传递每个数据集元素,并返回一个表示结果的新rdd。另一方面,“reduce”是使用某个函数聚合rdd的所有元素并将最终结果返回给驱动程序的操作(尽管还有一个并行的“reducebykey”返回分布式数据集)。
Spark中的所有转换都是“lazy”的,因为它们不会立即计算结果。相反,他们只记得应用到一些基本数据集(例如文件)的转换。只有当操作要求将结果返回到驱动程序时,才会计算转换。这种设计使spark更有效地运行。例如,我们可以意识到通过“map”创建的数据集将在“reduce”中使用,并且只将“reduce”的结果返回给驱动程序,而不是更大的映射数据集。
默认情况下,每次对每个已转换的RDD运行操作时,都可以重新计算它。但是,您也可以使用’persist’(或’cache’)方法在内存中persist一个rdd,在这种情况下,spark将保留集群上的元素,以便在下次查询时更快地访问它。还支持在磁盘上持久化RDD,或跨多个节点复制RDD。
转换算子Transformation(重点)
√map(func)
返回一个新的分布式数据集,该数据集是通过函数func传递源的每个元素而形成的。
scala> val rdd=sc.parallelize(List(1,2,3),3)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd.map(item=>item*2).collect()
res0: Array[Int] = Array(2, 4, 6)
√filter(func)
返回一个新的数据集,该数据集是通过选择源的那些元素而形成的,func在这些元素上返回true。
scala> val rdd=sc.parallelize(List(1,2,3),3)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd.filter(item=>item%2==0).collect()
res1: Array[Int] = Array(2)
√flatMap(func)
类似于映射,但是每个输入项可以映射到0个或多个输出项(因此func应该返回一个seq而不是单个项)。
scala> sc.makeRDD(List("this is a demo","hello world"))
.flatMap(line=>line.split(" "))
.collect()
res2: Array[String] = Array(this, is, a, demo, hello, world)
√mapPartitions(func)
Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator<T> => Iterator<U>when running on an RDD of type T.
与map类似,但在rdd的每个分区(块)上单独运行,因此当在t类型的rdd上运行时,func必须是“iterator=>iterator`类型。
scala> val rdd=sc.makeRDD(List("a","b","c","d","e"),3)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[5] at makeRDD at <console>:24
scala> rdd.mapPartitions(vs=> vs.map(_.toUpperCase)).collect()
res3: Array[String] = Array(A, B, C, D, E)
√mapPartitionsWithIndex(func)
Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, so func must be of type (Int, Iterator<T>) => Iterator<U> when running on an RDD of type T.
类似于MapPartitions,但也为func提供了一个表示分区索引的整数值,因此当在T类型的RDD上运行时,func必须是(int,iterator<t>)=>iterator<u>类型。
scala> val rdd=sc.makeRDD(List("a","b","c","d","e"),3)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[5] at makeRDD at <console>:24
scala> rdd.mapPartitionsWithIndex((p,vs)=> vs.map((_,p))).collect
res4: Array[(String, Int)] = Array((a,0), (b,1), (c,1), (d,2), (e,2))
sample(withReplacement, fraction, seed)-抽样
Sample a fraction fraction of the data, with or without replacement, using a given random number generator seed.
使用给定的随机数生成器种子,对数据的分数分数进行采样,无论是否替换。
scala> val rdd=sc.makeRDD(List("a","b","c","d","e"),3)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[8] at makeRDD at <console>:24
scala> rdd.sample(true,0.8,1L).collect()
res5: Array[String] = Array(a, a, d, d, e, e)
scala> rdd.sample(false,0.8,1L).collect()
res6: Array[String] = Array(a, c, d, e)
withReplacement:是否放回会抽样fraction抽样比例、seed随机种子
union(otherDataset)
Return a new dataset that contains the union of the elements in the source dataset and the argument.
返回包含源数据集中元素和参数的并集的新数据集。
scala> val rdd1=sc.makeRDD(List("a","b"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[12] at makeRDD at <console>:24
scala> val rdd2=sc.makeRDD(List("c","d"))
rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[13] at makeRDD at <console>:24
scala> rdd1.union(rdd2).collect
res9: Array[String] = Array(a, b, c, d)
intersection(otherDataset)
Return a new RDD that contains the intersection of elements in the source dataset and the argument.
返回一个新的RDD,该RDD包含源数据集中元素和参数的交集。
scala> val rdd1=sc.makeRDD(List("a","b"))
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[15] at makeRDD at <console>:24
scala> val rdd2=sc.makeRDD(List("a","c"))
rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[16] at makeRDD at <console>:24
scala> rdd1.intersection(rdd2).collect()
res10: Array[String] = Array(a)
√distinct([numPartitions]))
Return a new dataset that contains the distinct elements of the source dataset.
返回包含源数据集的不同元素的新数据集。
scala> val rdd=sc.makeRDD(List("a","b","a"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[29] at makeRDD at <console>:24
scala> rdd.distinct.collect()
res13: Array[String] = Array(a, b)
√coalesce(numPartitions) -缩放分区
Decrease the number of partitions in the RDD to numPartitions. Useful for running operations more efficiently after filtering down a large dataset.
将rdd中的分区数减少到numpartitions。有助于在筛选大型数据集之后更有效地运行操作。
scala> val rdd=sc.makeRDD(List("a","b","a"),3)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[36] at makeRDD at <console>:24
scala> rdd.coalesce(2).getNumPartitions
res14: Int = 2
scala> rdd.coalesce(5).getNumPartitions
res15: Int = 3
√repartition(numPartitions)
Reshuffle the data in the RDD randomly to create either more or fewer partitions and balance it across them. This always shuffles all data over the network.
随机地重新整理rdd中的数据,以创建更多或更少的分区,并在它们之间进行平衡。这总是通过网络洗牌所有数据。
scala> val rdd=sc.makeRDD(List("a","b","a"),3)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[39] at makeRDD at <console>:24
scala> rdd.repartition(5).getNumPartitions
res16: Int = 5
scala> rdd.repartition(1).getNumPartitions
res17: Int = 1
√groupByKey([numPartitions])
When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs.
当对(k,v)pairs的数据集调用时,返回(k,iterable<v>)pairs的数据集。Note: If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using reduceByKey or aggregateByKey will yield much better performance.
如果为了对每个键执行聚合(如总和或平均值)而进行分组,则使用“reducebykey”或“aggregatebykey”将获得更好的性能。
Note: By default, the level of parallelism in the output depends on the number of partitions of the parent RDD. You can pass an optional numPartitions argument to set a different number of tasks.
默认情况下,输出中的并行级别取决于父rdd的分区数。可以传递可选的“numpartitions”参数来设置不同数量的任务。
scala> val wordpair=sc.textFile("hdfs:///demo/words").flatMap(_.split(" ")).map((_,1))
wordpair: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[57] at map at <console>:24
scala> wordpair.groupBy(t=>t._1)
res22: org.apache.spark.rdd.RDD[(String, Iterable[(String, Int)])] = ShuffledRDD[59] at groupBy at <console>:26
scala> wordpair.groupByKey
res23: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[60] at groupByKey at <console>:26
scala> wordpair.groupByKey.map(t=>(t._1,t._2.sum)).collect()
res25: Array[(String, Int)] = Array((this,1), (is,1), (day,2), (come,1), (baby,1), (up,1), (a,1), (on,1), (demo,1), (good,2), (study,1))
√reduceByKey(func, [numPartitions])
When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument.
当在(k,v)对的数据集上调用时,返回一个(k,v)对的数据集,其中使用给定的reduce函数func聚合每个键的值,该函数的类型必须是(v,v)=>v。与“groupbykey”中一样,reduce任务的数量可以通过可选的第二个参数进行配置。
scala> val wordpair=sc.textFile("hdfs:///demo/words").flatMap(_.split(" ")).map((_,1))
wordpair: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[68] at map at <console>:24
scala> wordpair.reduceByKey((v1,v2)=>v1+v2,3).collect
res26: Array[(String, Int)] = Array((day,2), (come,1), (baby,1), (up,1), (is,1), (a,1), (demo,1), (this,1), (on,1), (good,2), (study,1))
scala> wordpair.reduceByKey(_+_).collect
res19: Array[(String, Int)] = Array((am,1), (shy,1), (day,2), (come,1), (baby,1), (up,1), (on,1), (i,1), (good,2), (study,1), (and,1))
√aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions])
When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral “zero” value. Allows an aggregated value type that is different than the input value type, while avoiding unnecessary allocations. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument.
当对(k,v)对的数据集调用时,返回(k,u)对的数据集,其中使用给定的组合函数和中性“零”值聚合每个键的值。允许不同于输入值类型的聚合值类型,同时避免不必要的分配。与“groupbykey”类似,reduce任务的数量可以通过可选的第二个参数进行配置。
scala> val wordpair=sc.textFile("hdfs:///demo/words").flatMap(_.split(" ")).map((_,1))
wordpair: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[68] at map at <console>:24
scala> wordpair.aggregateByKey(0)((z,v)=> z+v,(b1,b2)=> b1+b2).collect
res27: Array[(String, Int)] = Array((this,1), (is,1), (day,2), (come,1), (baby,1), (up,1), (a,1), (on,1), (demo,1), (good,2), (study,1))
scala> wordpair.aggregateByKey(0)(_+_,_+_).collect
res28: Array[(String, Int)] = Array((this,1), (is,1), (day,2), (come,1), (baby,1), (up,1), (a,1), (on,1), (demo,1), (good,2), (study,1))
√sortByKey([ascending], [numPartitions])
scala> val wordcount=sc.textFile("hdfs:///demo/words").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
wordcount: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[76] at reduceByKey at <console>:24
scala> wordcount.sortByKey(true,4).collect
res29: Array[(String, Int)] = Array((a,1), (baby,1), (come,1), (day,2), (demo,1), (good,2), (is,1), (on,1), (study,1), (this,1), (up,1))
scala> wordcount.sortByKey(false,4).collect
res30: Array[(String, Int)] = Array((up,1), (this,1), (study,1), (on,1), (is,1), (good,2), (demo,1), (day,2), (come,1), (baby,1), (a,1))
scala> wordcount.sortBy(t=>t._2,false,4).collect
res31: Array[(String, Int)] = Array((good,2), (day,2), (up,1), (a,1), (on,1), (demo,1), (study,1), (this,1), (is,1), (come,1), (baby,1))
√join(otherDataset, [numPartitions])
When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin.
当对(k,v)和(k,w)类型的数据集调用时,返回一个(k,(v,w))对的数据集,其中包含每个键的所有元素对。通过“leftouterjoin”、“rightoterjoin”和“fullouterjoin”支持外部联接。
scala> val userRDD=sc.makeRDD(List((1,"zs"),(2,"ls"),(3,"ww")))
userRDD: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[88] at makeRDD at <console>:24
scala> val costRDD=sc.makeRDD(List((1,100),(2,200),(1,150)))
costRDD: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[89] at makeRDD at <console>:24
scala> userRDD.join(costRDD).collect
res32: Array[(Int, (String, Int))] = Array((1,(zs,100)), (1,(zs,150)), (2,(ls,200)))
scala> userRDD.leftOuterJoin(costRDD).collect
res33: Array[(Int, (String, Option[Int]))] = Array((1,(zs,Some(100))), (1,(zs,Some(150))), (2,(ls,Some(200))), (3,(ww,None)))
cogroup(otherDataset, [numPartitions])
When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (Iterable, Iterable)) tuples. This operation is also called groupWith.
当对(k,v)和(k,w)类型的数据集调用时,返回(k,(iterable,iterable)元组的数据集。此操作也称为“groupwith”。
scala> val userRDD=sc.makeRDD(List((1,"zs"),(2,"ls"),(3,"ww")))
scala> val costRDD=sc.makeRDD(List((1,100),(2,200),(1,150)))
scala> userRDD.cogroup(costRDD).collect
res35: Array[(Int, (Iterable[String], Iterable[Int]))] = Array((1,(CompactBuffer(zs),CompactBuffer(100, 150))), (2,(CompactBuffer(ls),CompactBuffer(200))), (3,(CompactBuffer(ww),CompactBuffer())))
scala> userRDD.cogroup(costRDD).map(t=>(t._1,t._2._1.toList(0),t._2._2.sum))
res40: Array[(Int, String, Int)] = Array((1,zs,250), (2,ls,200), (3,ww,0))
动作算子(Action)
Spark中最多只有一个动作算子
触发任务的执行,返回值一般是Unit、Array、AnyVal,任何一个spark程序最多只用一个动作算子。
reduce(func)
单纯的求和
RDD[T] fun:(T,T)=>T
scala> sc.makeRDD(List(1,2,3)).reduce((v1,v2)=> v1+v2 )
res0: Int = 6
scala> sc.makeRDD(List("a","b","c")).reduce((v1,v2)=> v1+","+v2 )
res1: String = a,c,b
collect(测试)
可以直接打印
仅仅是将远程的计算节点的数据,下载到Driver端。
scala> sc.makeRDD(List("a","b","c")).collect()
res2: Array[String] = Array(a, b, c)
一般要求RDD数据集比较小,RDD[T]-> Array[T],这里的T必须能够参与序列化
foreach(func)
可以直接打印,但是没有输出,该算子是在计算节点完成计算,不会在driver端执行
动作算子,返回值是unit,该算子是在计算节点完成计算,不会参与网络序列化
scala是将数据遍历
spark中是并行算子,不需要做shuffle,不会在driver端执行
可以将计算的数据写入任何位置
动作算子,返回值为Unit,概算子是在计算节点完成计算。
scala> sc.makeRDD(List(1,2,3)).foreach(println) # 没有打印输出
scala> sc.makeRDD(List(1,2,3)).collect().foreach(println)
1
2
3
count()
计算RDD中元素的个数
scala> sc.makeRDD(List("a" ,"b")).count()
res8: Long = 2
first()
获取第一个等价于take(1)
scala> sc.makeRDD(List(1,2,3)).first
res9: Int = 1
scala> sc.makeRDD(List(1,2,3)).take(1)
res10: Array[Int] = Array(1)
//拿两个
scala> sc.makeRDD(List(1,2,3)).take(2)
res11: Array[Int] = Array(1, 2)
takeSample(withReplacement, num, [seed])
随机从RDD中抽取num个数据,
scala> sc.makeRDD(List(1,2,3,4,5,6)).takeSample(false,10,1L)
res16: Array[Int] = Array(5, 3, 1, 2, 6, 4)
scala> sc.makeRDD(List(1,2,3,4,5,6)).sample(true,0.8,1L).collect()
res12: Array[Int] = Array(1, 1, 4, 4, 6, 6)
takeOrdered(n, [ordering])
//先按照工资排序,工资相同时按照年龄排序
scala> sc.makeRDD(List(("zhangsan",10000,18),("zhangsan",10000,19),("lisi",15000,20))).takeOrdered(3)(new Ordering[(String,Int,Int)]{
| override def compare(x: (String, Int, Int), y: (String, Int, Int)): Int = {
| if(x._2 != y._2){
| (x._2-y._2)* -1
| }else{
| (x._3-y._3) * -1
| }
| }
| })
res18: Array[(String, Int, Int)] = Array((lisi,15000,20), (zhangsan,10000,19), (zhangsan,10000,18))
scala> sc.makeRDD(List(1,3,2,8,9,6)).takeOrdered(2)
res19: Array[Int] = Array(1, 2)
countByKey()
注意样本数据的key数目不易过大。因为返回值是Map
scala> sc.textFile("hdfs:///demo/words")
.flatMap(_.split("\\s+"))
.map((_,1))
.countByKey()
saveAsTextFile(path) 接近实战
为了是数据的清洗
存储到远端服务器
算子在下载属性的时候
解决了连接在网络传输的问题
scala> sc.textFile("hdfs:///demo/words")
.flatMap(_.split("\\s+"))
.map(word=>word+","+1).saveAsTextFile("hdfs:///results01")
INFO com.baizhi.service.IUserSerice#login UserRisk 001 123456 1000,15000,2000 219.143.103.186 2019-09-27 10:10:00 Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Mobile Safari/537.36
地域 用户分布
时间 每个月用户登录 统计
统计用户APP使用习惯
foreach(func)写出
准备工作
[root@CentOS ~]# cd /usr/hbase-1.2.4/
[root@CentOS hbase-1.2.4]# ./bin/hbase shell
hbase(main):002:0> create 'baizhi:t_wordcount','cf1','cf2'
#查看数据
hbase(main):008:0> scan 'baizhi:t_wordcount'
连接需要序列化
val sparkConf = new SparkConf()
.setAppName("wordcount")
.setMaster("local[6]")
val sc = new SparkContext(sparkConf)
//定义Hbase连接参数
val hConf = HBaseConfiguration.create()
hConf.set(HConstants.ZOOKEEPER_QUORUM,"CentOS")
val conn = ConnectionFactory.createConnection(hConf)
val table = conn.getTable(TableName.valueOf("baizhi:t_wordcount"))
sc.textFile("hdfs://CentOS:9000/demo/words")
.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKey(_+_)
.foreach(wordpair=>{
//写入到HBaase
val put = new Put(wordpair._1.getBytes())
put.add("cf1".getBytes(),"key".getBytes(),wordpair._1.getBytes())
put.add("cf1".getBytes(),"count".getBytes(),(wordpair._2+"").getBytes())
table.put(put)
})
conn.close()
table.close()
sc.stop()
Driver端定义的变量都必须是只读的,分布式算子在使用Driver的变量的时候需要做网络下载。
频繁的开关连接
val sparkConf = new SparkConf()
.setAppName("wordcount")
.setMaster("local[6]")
val sc = new SparkContext(sparkConf)
val value = new util.HashMap()
sc.textFile("hdfs://CentOS:9000/demo/words")
.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKey(_+_)
.foreach(wordpair=>{
//定义Hbase连接参数
val hConf = HBaseConfiguration.create()
hConf.set(HConstants.ZOOKEEPER_QUORUM,"CentOS")
val conn = ConnectionFactory.createConnection(hConf)
val table = conn.getTable(TableName.valueOf("baizhi:t_wordcount"))
//写入到HBaase
val put = new Put(wordpair._1.getBytes())
put.add("cf1".getBytes(),"key".getBytes(),wordpair._1.getBytes())
put.add("cf1".getBytes(),"count".getBytes(),(wordpair._2+"").getBytes())
table.put(put)
conn.close()
table.close()
})
sc.stop()
一个分区一个连接 -foreachpartition
val sparkConf = new SparkConf()
.setAppName("wordcount")
.setMaster("local[6]")
val sc = new SparkContext(sparkConf)
sc.textFile("hdfs://CentOS:9000/demo/words")
.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKey(_+_)
.foreachPartition(wordpairs=>{
//定义Hbase连接参数
val hConf = HBaseConfiguration.create()
hConf.set(HConstants.ZOOKEEPER_QUORUM,"CentOS")
val conn = ConnectionFactory.createConnection(hConf)
val table = conn.getTable(TableName.valueOf("baizhi:t_wordcount"))
wordpairs.foreach(wordpair=>{
//写入到HBaase
val put = new Put(wordpair._1.getBytes())
put.add("cf1".getBytes(),"key".getBytes(),wordpair._1.getBytes())
put.add("cf1".getBytes(),"count".getBytes(),(wordpair._2+"").getBytes())
table.put(put)
})
conn.close()
table.close()
})
sc.stop()
利用类加载机制,将连接参数做成静态
如果一个节点负责多个分区,同样可以实现共享连接。
object HBaseSink {
def createConnection(): Connection = {
val hConf = HBaseConfiguration.create()
hConf.set(HConstants.ZOOKEEPER_QUORUM,"CentOS")
ConnectionFactory.createConnection(hConf)
}
val conn:Connection=createConnection()
Runtime.getRuntime.addShutdownHook(new Thread(){
override def run(): Unit = {
println("=-===close=====")
conn.close()
}
})
}
val sparkConf = new SparkConf()
.setAppName("wordcount")
.setMaster("local[6]")
val sc = new SparkContext(sparkConf)
sc.textFile("hdfs://CentOS:9000/demo/words")
.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKey(_+_)
.foreachPartition(wordpairs=>{
//定义Hbase连接参数
val table = HBaseSink.conn.getTable(TableName.valueOf("baizhi:t_wordcount"))
wordpairs.foreach(wordpair=>{
//写入到HBaase
val put = new Put(wordpair._1.getBytes())
put.add("cf1".getBytes(),"key".getBytes(),wordpair._1.getBytes())
put.add("cf1".getBytes(),"count".getBytes(),(wordpair._2+"").getBytes())
table.put(put)
})
table.close()
})
sc.stop()
共享变量
如果Spark转换算子中用到Driver中定义的变量,spark会将这些定义在Driver中的变量拷贝到所有的计算节点,并且这些变量的修改的值并不会传递回来给Driver定义的变量。
scala> var count:Int=0
count: Int = 0
scala> sc.textFile("hdfs:///demo/words").foreach(line=> count += 1)
scala> println(count)
0
如上面演示,我们在Driver中定义了一个Int类型的变量,在foreach算子中我们常使用count,spark底层在执行的时候,仅仅是将count通过网络方式传递给计算节点,计算节点仅仅是copy的数据,一旦计算结束之后,任务完成, 事实上每个计算节点都维系了一个自己的count变量的副本,并不会修改Driver中的变量。因此可以得出结论,任何定义在Driver中的变量一般情况下都是只读的。并行算子每次在使用的时候会尝试下载本地。
场景1
几十MB用户数据
001 zhangsan
002 lisi
一个TB的订单数据
001 50
002 100
001 120
...
需要用户对用户订单数据做ETL清洗,最终输出结果
001 zhangsan 50
002 lisi 100
001 zhangsan 120
...
scala> val userRDD=sc.makeRDD(List(("001","zhangsan"),("002","lisi")))
scala> val orderRDD=sc.makeRDD(List(("001",500),("002",1000),("001",100)))
scala> userRDD.join(orderRDD).collect
res2: Array[(String, (String, Int))] = Array((001,(zhangsan,500)), (001,(zhangsan,100)), (002,(lisi,1000)))
此时系统一般会产生shuffle,会导致
订单数据在shuffle过程占用大量带宽。解决之道
scala> val map=Map(("001","zhangsan"),("002","lisi"))
scala> val orderRDD=sc.makeRDD(List(("001",500),("002",1000),("001",100)))
// 根据key拿value
scala> orderRDD.map(t=>(t._1,map.get(t._1).getOrElse(""),t._2)).collect
res3: Array[(String, String, Int)] = Array((001,zhangsan,500), (002,lisi,1000), (001,zhangsan,100))
如果orderRDD的分区比较多,也就是后续所有的并行任务在计算的时候都需要从Driver端下载map,由于有可能一些任务执行在同一计算节点上。没必要每一次计算都需从Dirver端下载,因此Spark提供一种广播变量机制,通过广播变量将需要下载的数据提前广播给所有的计算节点,这样后续所有计算在使用该变量的时候,直接从本地获取,节省了和Driver通讯的网络成本。
scala> val map=Map(("001","zhangsan"),("002","lisi"))
map: scala.collection.immutable.Map[String,String] = Map(001 -> zhangsan, 002 -> lisi)
scala> val bmap=sc.broadcast(map) //广播变量
bmap: org.apache.spark.broadcast.Broadcast[scala.collection.immutable.Map[String,String]] = Broadcast(6)
scala> orderRDD.map(t=>(t._1,bmap.value.get(t._1).getOrElse(""),t._2)).collect
res5: Array[(String, String, Int)] = Array((001,zhangsan,500), (002,lisi,1000), (001,zhangsan,100))
bmap.value:获取的广播到本地的变量map,程序就会再从Driver下载变量了。
场景2
TB级别
001 zhangsan
002 lisi
TB级别
001 100
002 1000
解决思路:对这两个需要join的数据预分区,必须保证分区数保持高度一致,【两个数必须来自相同的分区号】例如: 分区10000
100MB & 100MB join
sc.textFile("hdfs:///users-log/").map(...).repartitions(1000).savaAsTextFiles("hdfs:///users")
sc.textFile("hdfs:///orders-log/").map(...).repartitions(1000).savaAsTextFiles("hdfs:///orders")
sc.textFile("hdfs://CentOS:9000/users/part-00000").map(t=>t.split("\\s+")).map(ts=>(ts(0),ts(1)))
.join(sc.textFile("hdfs://CentOS:9000/orders/part-00000").map(t=>t.split("\\s+")).map(ts=>(ts(0),ts(1))))
...
sc.textFile("hdfs://CentOS:9000/users/part-00001").map(t=>t.split("\\s+")).map(ts=>(ts(0),ts(1)))
.join(sc.textFile("hdfs://CentOS:9000/orders/part-00002").map(t=>t.split("\\s+")).map(ts=>(ts(0),ts(1))))
...
累加器
scala> var count:Int=0
count: Int = 0
scala> sc.textFile("hdfs:///demo/words").foreach(line=> count += 1)
scala> println(count)
0
修改的值 并不传递回Driver,可以使用spark提供累加器
scala> val count = sc.longAccumulator("count")
count: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 525, name: Some(count), value: 0)
scala> sc.textFile("hdfs:///demo/words").foreach(line=> count.add(1))
scala> count.value
res14: Long = 4
程占用大量带宽。解决之道
scala> val map=Map(("001","zhangsan"),("002","lisi"))
scala> val orderRDD=sc.makeRDD(List(("001",500),("002",1000),("001",100)))
// 根据key拿value
scala> orderRDD.map(t=>(t._1,map.get(t._1).getOrElse(""),t._2)).collect
res3: Array[(String, String, Int)] = Array((001,zhangsan,500), (002,lisi,1000), (001,zhangsan,100))
如果orderRDD的分区比较多,也就是后续所有的并行任务在计算的时候都需要从Driver端下载map,由于有可能一些任务执行在同一计算节点上。没必要每一次计算都需从Dirver端下载,因此Spark提供一种广播变量机制,通过广播变量将需要下载的数据提前广播给所有的计算节点,这样后续所有计算在使用该变量的时候,直接从本地获取,节省了和Driver通讯的网络成本。
scala> val map=Map(("001","zhangsan"),("002","lisi"))
map: scala.collection.immutable.Map[String,String] = Map(001 -> zhangsan, 002 -> lisi)
scala> val bmap=sc.broadcast(map) //广播变量
bmap: org.apache.spark.broadcast.Broadcast[scala.collection.immutable.Map[String,String]] = Broadcast(6)
scala> orderRDD.map(t=>(t._1,bmap.value.get(t._1).getOrElse(""),t._2)).collect
res5: Array[(String, String, Int)] = Array((001,zhangsan,500), (002,lisi,1000), (001,zhangsan,100))
bmap.value:获取的广播到本地的变量map,程序就会再从Driver下载变量了。
场景2
TB级别
001 zhangsan
002 lisi
TB级别
001 100
002 1000
解决思路:对这两个需要join的数据预分区,必须保证分区数保持高度一致,【两个数必须来自相同的分区号】例如: 分区10000
100MB & 100MB join
sc.textFile("hdfs:///users-log/").map(...).repartitions(1000).savaAsTextFiles("hdfs:///users")
sc.textFile("hdfs:///orders-log/").map(...).repartitions(1000).savaAsTextFiles("hdfs:///orders")
sc.textFile("hdfs://CentOS:9000/users/part-00000").map(t=>t.split("\\s+")).map(ts=>(ts(0),ts(1)))
.join(sc.textFile("hdfs://CentOS:9000/orders/part-00000").map(t=>t.split("\\s+")).map(ts=>(ts(0),ts(1))))
...
sc.textFile("hdfs://CentOS:9000/users/part-00001").map(t=>t.split("\\s+")).map(ts=>(ts(0),ts(1)))
.join(sc.textFile("hdfs://CentOS:9000/orders/part-00002").map(t=>t.split("\\s+")).map(ts=>(ts(0),ts(1))))
...
累加器
scala> var count:Int=0
count: Int = 0
scala> sc.textFile("hdfs:///demo/words").foreach(line=> count += 1)
scala> println(count)
0
修改的值 并不传递回Driver,可以使用spark提供累加器
scala> val count = sc.longAccumulator("count")
count: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 525, name: Some(count), value: 0)
scala> sc.textFile("hdfs:///demo/words").foreach(line=> count.add(1))
scala> count.value
res14: Long = 4















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









