







1、背景知识:
- 对称密钥加密:发送方与接收方的密钥相同
只使用一次的密钥安全性很高,多次使用密钥安全性降低流加密(stream)、块加密(block)等
- 非对称密钥加密:发送方与接收方密钥不同
分为公钥与私钥
公钥大家都知道,私钥只有自己知道
2、项目题目:
给定10串经过对称密钥加密的密文,推断出他们统一用到的key,并且求出(某一段)原文。从而体会在对称密钥加密中如果被得到了用同样密钥加密的若干段密文,是很大几率能被破解的。
3、分析与解决方法:
切入点1:
(P1 ⊕ K) ⊕ (P2 ⊕ K) == P1 ⊕ P2
明文P1,明文P2,密钥K
=>密文C1 ⊕ 密文C2 == 明文P1 ⊕明文P2
切入点2:

所以将两条密文相异或之后,如果得到的结果二进制表示是01开头,或者更严格的来讲,如果得到的结果十进制表示是在65~90或者97~122之中的话,那很可能在这个位置上,两条密文中的一条它的原文是一个空格,据此,可以初步断定得出该密文在该位置上的原文,同时,因为
Key = 密文 ^ 原文,所以用这个推断出的原文去和密文异或,可以得到对应位置上的key密钥。用同样的方法得到更多位置上的key,然后就可以得到key的大部分位置上的值,就可以用key去解密得到原文:原文=密文^key。
所以解题方法主要有三大步骤:
(1) 第一个是将所有密文两两异或(每位每位地异或),然后统计某文段上某个位置的原文可能是空格space的概率(通过判定为空格的出现频次),当概率超过一定值(这里我取6/9,也就是频次超过6)时,断定它这一位置上的原文是空格。
(2)进而利用原文^密文得到对应位置的key,以此类推,就可以求出一大部分位置上的key的值。
(3)最后用这个key去异或任何一个密文,即可得到对应的原文段落,注意得到的原文并不是完整的,但是补充的内容可以给我们很多信息,进而可能推出所有的原文。
代码实现:
/*
* lab1.cpp
*
* Created on: 2016-3-14
* Author: LvLang
*/
#include <iostream>
#include <fstream>//support file I/O
//#include <sstream>//support sstream
#include <algorithm> //support sort()
#include <string.h>
#include <stdlib.h> //support for exit
using namespace std;
//tips:函数折叠快捷键:ctrl+小键盘的'/'
const int space_num = 6;//判定为空格所需频次
int array[11][200];//存储转化后的int
int space[11][200];//每行每列空格出现频次
int k[95];//记录含空格的行和列,存储规则为“先行再列”
char plain[100];//明文
//找出最大array的size,也就是key的length
int find_key_length(string *s)
{
int max = s[1].length();
for(int i=2;i<=10;i++)
{
int temp = s[i].length();
if(temp > max)
max = s[i].length();
}
int result = max / 2;
return result;
}
//文件读取
void fileInput(string *s,int n){
/****** 数据预处理 *******/
ifstream inFile;
inFile.open("C:/Users/Administrator/Desktop/cipertext.txt");
if(!inFile.is_open())
{
cout<<"Cannot open file!"<<endl;
exit(EXIT_FAILURE);
}
for(int i=1;i<=n;i++){
//读取一整行then赋值给s[i]
getline(inFile,s[i]);
}
inFile.close();//关闭文件
cout<<"File input 成功"<<endl;
}
//16进制的string转换为十进制的int
void transform(string *s){
for(int index = 1;index <= 10;index++)
{
int len = s[index].length();
int j = 1;
for(int i=0;i < len;i=i+2)
{
string a1 = s[index].substr(i,2);//每两位抽取出来
const char *b1 = a1.c_str();//转换成char*
int temp = 0;
temp = (int)strtol(b1,NULL,16);//转换成十进制int
array[index][j] = temp;//逐一存进数组
j++;
}
}
}
//异或操作判断是否为空格
bool XOR(int a,int b)
{
int result = a ^ b;
if((result>=65 && result<=90)||
(result>=97 && result<=122))
return true;
else
return false;
}
//列进行异或找出最大概率为空格的string
void find_space(string *s,int column)
{
for(int i=1;i<=10;i++)
{
int num = 0;
for(int j=1;j<=10;j++)
{
if(i != j)
{
if(XOR(array[i][column],array[j][column]) == true)
{
//则该行该列空格频次加1
num++;
space[i][column] = num;
}
}
}
}
}
//每列都进行一次两两异或
void XOR_all(string *s,int key_len)
{
for(int column = 1; column <= key_len;column++)
find_space(s,column);
}
//测试一下space数组
/*void test_space(string *s)
{
for(int i=1;i<=10;i++)
{
int len = s[i].length() / 2;
for(int j=1;j <= len;j++)
{
cout<<"第"<<i<<"行"<<"第"
<<j<<"列空格频次为"<<space[i][j]<<endl;
}
}
}*/
//K = C ^ P
void getKey(int cipher,int col,int *key)
{
int result = cipher ^ 32;
key[col] = result;
}
//解密——还原key
void decryption(int *key,int row,int col)
{
int cipher = array[row][col];//密文是array对应位置的值
getKey(cipher,col,key);
}
//根据频次来断定某位是空格
void judge_space(string *s,int *key)
{
int x = 1;
for(int row = 1;row <= 10;row++)
{
int len = s[row].length() / 2;
for(int col = 1; col <= len;col++)
{
if(space[row][col] >= space_num)
{
k[x] = row;
k[x+1] = col;
x = x + 2;
}
}
}
}
//判断空格并开始解密
void judge(string *s,int *key)
{
judge_space(s,key);
for(int row=1;row <= 95;row=row+2)
{
int t = k[row],tt=k[row+1];
if(k[row] > 0)
{
//得到key
decryption(key,t,tt);
}
}
}
//output key
void print_key(int *key,int key_len)
{
for(int i=1;i <= key_len;i++)
{
if(key[i] != 0)
cout<<"key的第"<<i<<"位为"<<key[i]<<endl;
}
}
//得到相应位置的明文
void getPlaintext(int *key,string *s,int s_index)
{
int len = s[s_index].length() / 2;
for(int i=1;i <= len;i++)
{
if(key[i] != 0)
{
int temp = array[s_index][i]^key[i];
if(temp >31 && temp < 127)
{
plain[i] = (char)temp;
cout<<plain[i];
//cout<<"第"<<i<<"位明文是"<<plain[i]<<endl;
}
}
else
cout<<" ";
}
}
int main()
{
//从文件中读取字符串
string s[11];
fileInput(s,10);
int key_len = find_key_length(s);//key的长度
int *key = new int[key_len];
for(int i = 0;i <= key_len; i++)//初始化
{
key[i] = 0;
}
//初始化
for(int i=1;i<=10;i++)
{
for(int j=1;j<=key_len;j++)
space[i][j] = 0;
}
//16进制的string转换为十进制(ASCII)int
transform(s);
//两两异或
XOR_all(s,key_len);
//test_space(s);
//判断空格
judge(s,key);
// judge_space(s,key);
// print_key(key,key_len);
cout<<"各行的部分原文为:"<<endl;
for(int s_index = 1;s_index <= 10; s_index++)
{
cout<<"第"<<s_index<<"行: ";
getPlaintext(key,s,s_index);//得出原文
cout<<endl;
}
return 0;
}
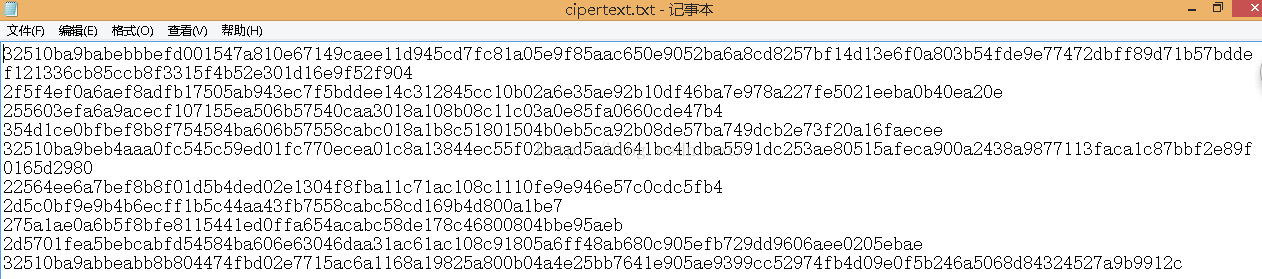
密文文件:
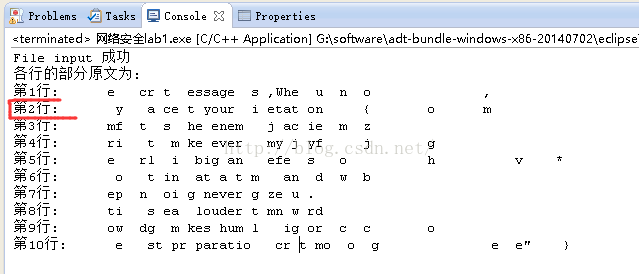
程序运行结果(eclipse C++ 通过):
代码和函数有点多,但涉及到了很多非常有用的C++知识。下面总结下供自己以后复习顺便当下提升下记忆:
1、从程序运行的开始一一挑出需要注意的知识点来总结下吧,main函数开始,首先是关于C++读取文件的,因为本项目需要从文本文件中读取几段密文进来处理。
C++ 的file I/O操作首先需要include<fstream>进来,然后先实例化文件流对象,input的话是 ifstream inFile; output的话是 ofstream outFile; 然后调用该对象的open函数打开相应的文件,如outFile.open("io.text"); inFile.open("io.text"); 对于outFile,如果没有找到文件名对应的文件,则会新建文件,而对于inFile,没找到就出错。注意这里的文件名都是相对路径(这点和web/jsp里面的相对路径和绝对路径一样),指的是在eclipse workplace里面exe下的文件夹,也可以用绝对路径从其他文件夹引入文件。也可能由于一些原因打开文件失败,可以用对象的.open()函数check一下,如果返回的bool值为false,则调用<stdlib.h>库里面的exit(EXIT_FAILURE);函数终止程序运行。如果成功打开就可以继续操作,对于outFile,可以这样:
outFile<<"Hello"<<endl;//把Hello字符串写入到文件中并换行
int a = 123;
outFile<<a<<endl;//把123写入文件中并换行对于inFile,则:
int value[10],i=0;
while(!inFile.eof())//eof()函数表示到了文件尾
{
inFile>>value[i];//把数存进value数组里
cout<<value[i]<<endl;
i++;
}最后完成了文件操作之后,文件输入或者输出都要关闭文件,如inFile.close();
2:第二点说一下C++<string>库里面的string,注意它和<cstring>库里面的string很不一样,<string>库里面的string有更多很好用的函数,他们的区别在我的另外转载的一篇博客中也提到了。比如 .length()函数和 .size()函数(或者int len = sizeof(s);)或者int len = strlen(s)可以返回string的长度,但是size()和sizeof(s)其实是返回string所占的字节数,只有当string的每一位占1个字节byte时(int/char,貌似就汉子一个字符占两个字节),它才能起到直接返回string长度的作用。<string>库的string最后没有'\0',而C语言里面定义char数组最后肯定要有个'\0'结尾并且占一个位置(长度+1),这个也是经常容易忽略的细节,在网上搜一下就会有一堆解释,这里就不赘述了。
3:说一下new关键字,
<pre name="code" class="cpp">int *array = new int[key_len];int array[10];int n;
cin>>n;
int *array = new int[n]
delete[] array;//需要加方括号[]
int* temp;
delete temp;4:然后说一下C/C++里面的异或操作吧,其实直接拿两个十进制的数异或得到的结果跟把它转换成二进制之后再异或得到的结果是一样的,应该就是C/C++语言里面十进制的异或也是对位(后台转二进制)异或的,不信你试试。也可以百度下计算器,不用自己手算。
5:16进制string转化为十进制int,方法如上面项目代码:
string a1 = s[index].substr(i,2);//每两位抽取出来
const char *b1 = a1.c_str();//转换成char*
int temp = 0;
temp = (int)strtol(b1,NULL,16);//转换成十进制intlong int strtol (const char* str, char** endptr, int base);方法二是用sscanf函数(<stdlib.h>或<stdio.h>库):
char* p = "0x1a";
int nValude = 0;
sscanf(p, "%x", &nValude);网搜还有其他的方法。
6:说一下二维数组这个东西吧。不过先说一下数组和eclipse的一些关系,本人在这个项目的时候就试过定义的数组长度并不够大,然后在用一个循环的时候超出了数组长度去调用数组,最后eclipse build的时候并没有报错,然而run了之后马上程序崩溃,不知名错误!要调试的话花不少时间啊,所以数组长度这里要非常小心,有时出现了一些程序崩溃的未知bug时,可以去check数组有没有越界使用。然后二维数组,挺好用的,这里就提一下在函数参数引用二维数组时,尽量直接这样表达吧,因为直接用个*指针的话是会报错的貌似:
void print(int array[11][200])
{}7:其他的各点上的知识貌似没发现需要在这提的了,最后这点说一下代码风格和代码开发的一些tips,提醒下自己。其一,就是“分治法”!跟算法里面的分治法一样,大问题切分成小问题。反映到代码中就是构建一个个小问题,逐个击破,无限逼近大boss的斩杀最后通关!所以像这样还有些规模的项目,需要提醒自己多把一些功能分成各个函数去实现,甚至考虑分成多个文件,因为所有代码所有函数挤在同个文件查看的时候挺苦逼的,或者,封装成类用面向对象的方法去do!
写在最后,其实本人写的这个项目代码效率和风格以及精简度其实是有很多方面可以提高的,这方面自己需要多去多练多去总结多敲代码!本项目开发中自己还有个未解决的问题,就是eclipse的debug,一点进去debug项目就弹出一个报错窗口,然后调试也进行不下去,本人另外写了些超简单的文件/项目,debug却可以进行,所以这个问题自己要尽早网搜fight掉它!解决了记得回来写一篇博客!跟遇到同样问题的人分享!That's all.完结!最近看了好几篇英格拉萨paper之后,开始各方面逼迫自己涉及英语以进一步提高英语水平,所以写文章也带英语,哈哈!毕竟高考之前英语一直都是自己的超强项,不能弃!















 207
207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









