






 本文详细介绍了KNN算法的概念、实现步骤,包括数据预处理、特征工程、模型训练与评估,展示了如何使用Python进行KNN算法在糖尿病数据集上的实践,包括K值选择、预测准确性、混淆矩阵和ROC曲线分析。
本文详细介绍了KNN算法的概念、实现步骤,包括数据预处理、特征工程、模型训练与评估,展示了如何使用Python进行KNN算法在糖尿病数据集上的实践,包括K值选择、预测准确性、混淆矩阵和ROC曲线分析。
KNN算法学习记录
目录
- KNN算法学习记录
- 一、KNN概念
- 二、KNN算法实现过程
- 1.导入相关python的库
- 2.加载数据集,利用pandas库的head()方法,查看数据集的前五条记录,初步了解数据集的结构和内容
- 3.利用pandas的describe().T方法以行的方式显示数据集的基本统计信息
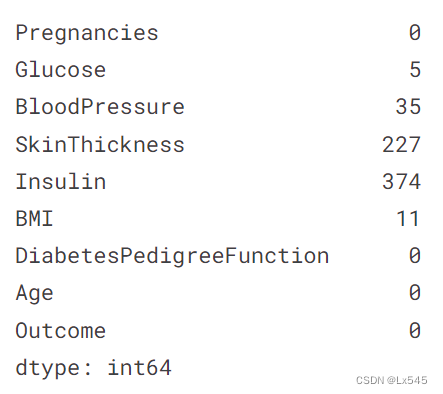
- 4.创建数据集的副本并将存在零值的列中的零值替换成缺失值,统计副本每列的缺失值数量
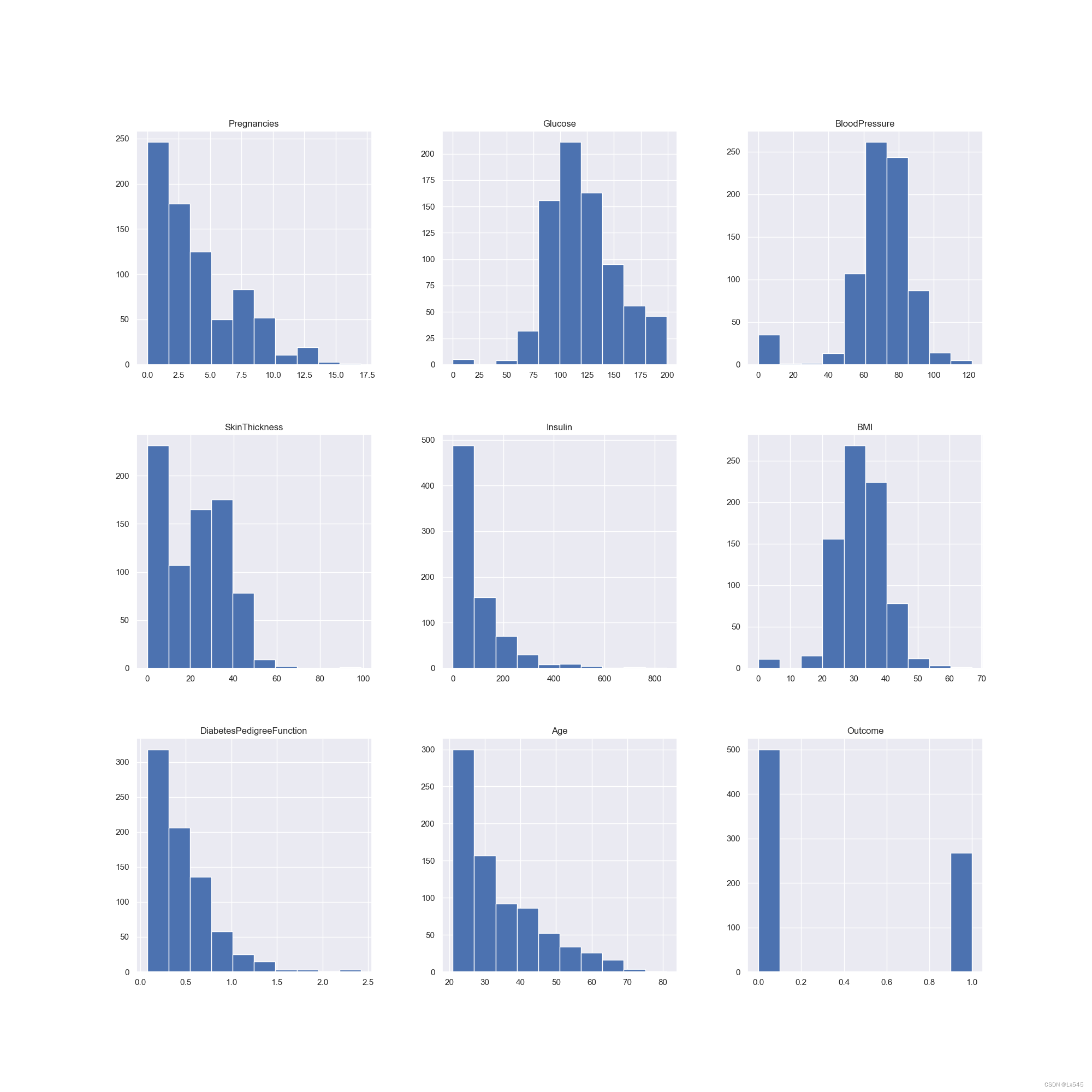
- 5.显示数据集的直方图,选择为副本的缺失值填充的值
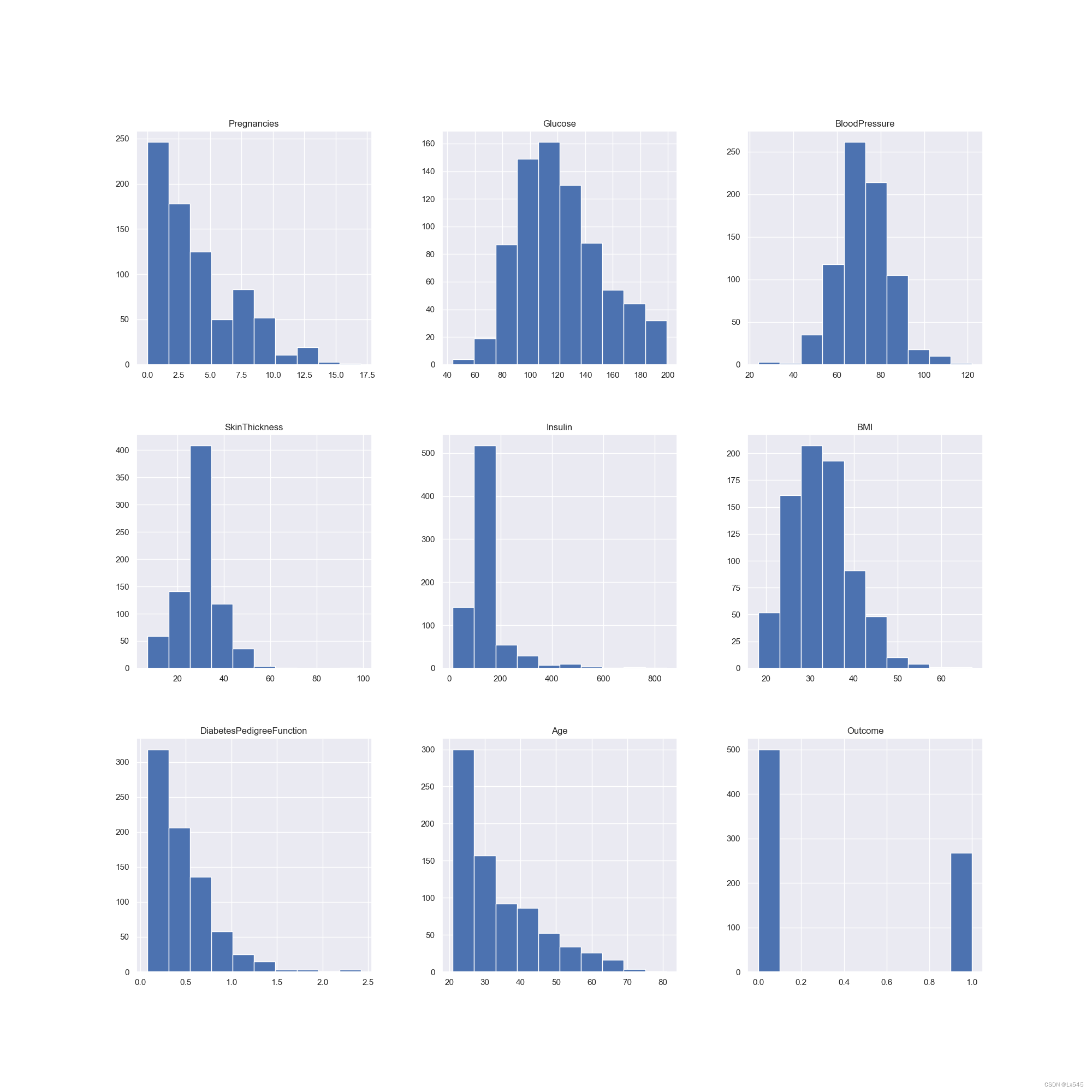
- 6.显示修改后的副本直方图
- 7.显示数据集的缺失值的分布图,观察是否有缺失值
- 8.用条形图显示结果列的情况,1代表得糖尿病,0代表没有得糖尿病
- 9.对副本进行标准化处理(除了outcome列)使得每个特征均值为0,标准差为1,加快模型的收敛速度方便进行knn算法,X为特征部分
- 10.创建目标变量部分
- 11.将数据集划分为训练集和测试集,以便在模型训练和评估过程中使用不同的数据集
- 12.书写knn算法
- 13利用knn算法进行训练和评估,存储不同参数下训练集和测试集的得分
- 14.分别找出在训练集和测试集上表现最好的K值以及对应的最高训练得分
- 15.使用matplotlib和seaborn库绘制了训练集和测试集在不同K值下的得分情况的折线图
- 16.显示选择的K=11的预测结果的准确率
- 17.使用已经训练好的 K 最近邻分类器对测试集进行预测,得到预测结果 并使用热力图显示预测结果和实际结果的混淆矩阵
- 18.绘制ROC曲线评估分类器性能,并计算AUC-ROC值用于性能评估
一、KNN概念
KNN(K-Nearest Neighbor)算法是机器学习算法中最基础、最简单的算法之一。它既能用于分类,也能用于回归。KNN通过测量不同特征值之间的距离来进行分类。
KNN算法的思想非常简单:对于任意n维输入向量,分别对应于特征空间中的一个点,输出为该特征向量所对应的类别标签或预测值。
KNN算法是一种非常特别的机器学习算法,因为它没有一般意义上的学习过程。它的工作原理是利用训练数据对特征向量空间进行划分,并将划分结果作为最终算法模型。存在一个样本数据集合,也称作训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。
输入没有标签的数据后,将这个没有标签的数据的每个特征与样本集中的数据对应的特征进行比较,然后提取样本中特征最相近的数据(最近邻)的分类标签。
一般而言,我们只选择样本数据集中前k个最相似的数据,这就是KNN算法中K的由来,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的类别,作为新数据的分类。
二、KNN算法实现过程
1.导入相关python的库
from mlxtend.plotting import plot_decision_regions
import numpy as np
import pandas as pd
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
2.加载数据集,利用pandas库的head()方法,查看数据集的前五条记录,初步了解数据集的结构和内容
diabetes_data = pd.read_csv('../diabetes.csv')
diabetes_data.head()

3.利用pandas的describe().T方法以行的方式显示数据集的基本统计信息
diabetes_data_describe = diabetes_data.describe().T
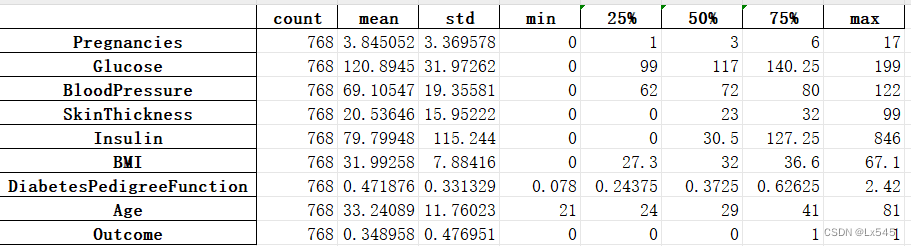
观察到’Glucose’,‘BloodPressure’,‘SkinThickness’,‘Insulin’,'BMI’最小值为0,零值在进行数据分析时没有意义,需要变成缺失值
4.创建数据集的副本并将存在零值的列中的零值替换成缺失值,统计副本每列的缺失值数量
diabetes_data_copy = diabetes_data.copy(deep=True)
diabetes_data_copy[['Glucose','BloodPressure', 'SkinThickness', 'Insulin', 'BMI']] = diabetes_data_copy[['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']].replace(0, np.NaN)
print(diabetes_data_copy.isnull().sum())
5.显示数据集的直方图,选择为副本的缺失值填充的值
p = diabetes_data.hist(figsize=(20, 20))
plt.show()
diabetes_data_copy['Glucose'].fillna(diabetes_data_copy['Glucose'].mean(), inplace=True)
diabetes_data_copy['BloodPressure'].fillna(diabetes_data_copy['BloodPressure'].mean(), inplace=True)
diabetes_data_copy['SkinThickness'].fillna(diabetes_data_copy['SkinThickness'].median(), inplace=True)
diabetes_data_copy['Insulin'].fillna(diabetes_data_copy['Insulin'].median(), inplace=True)
diabetes_data_copy['BMI'].fillna(diabetes_data_copy['BMI'].median(), inplace=True)
6.显示修改后的副本直方图
p = diabetes_data_copy.hist(figsize = (20,20))
plt.show()
7.显示数据集的缺失值的分布图,观察是否有缺失值
import missingno as msno
p = msno.bar(diabetes_data)
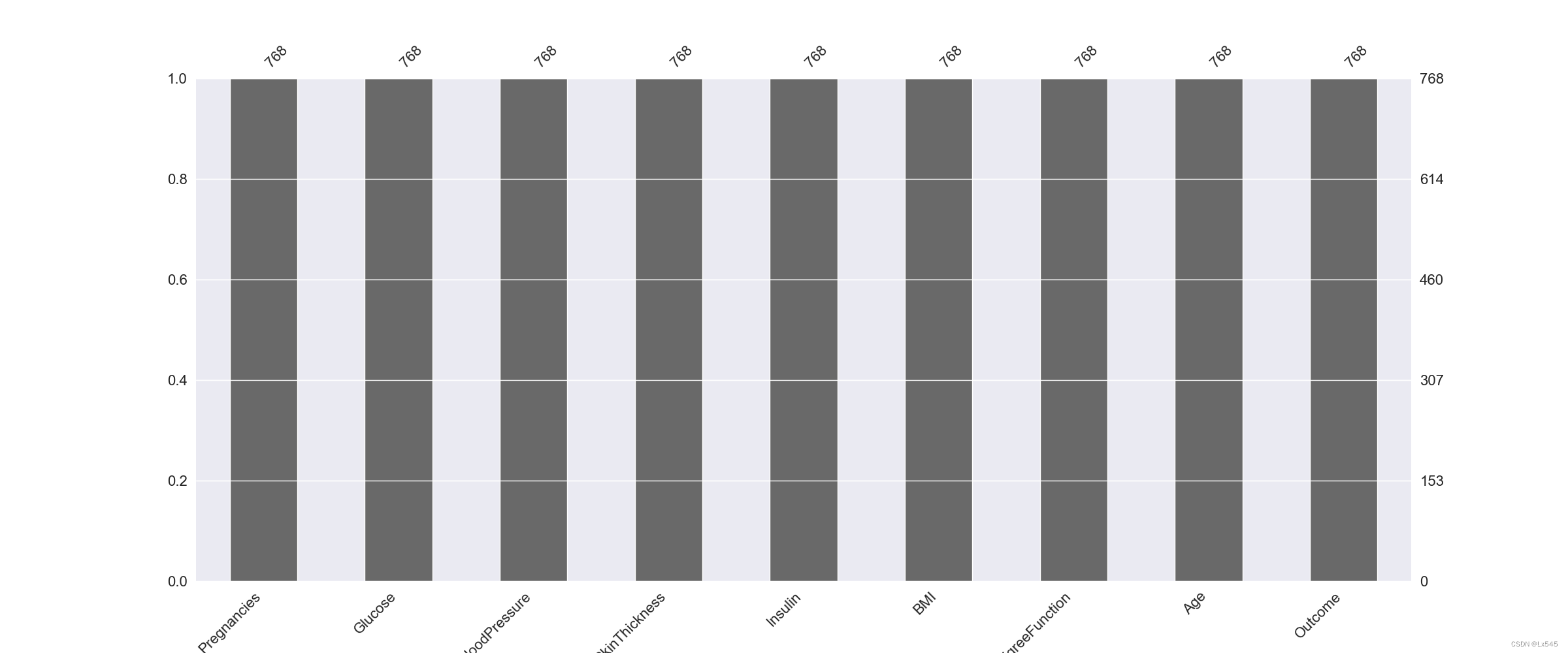
发现没有缺失值
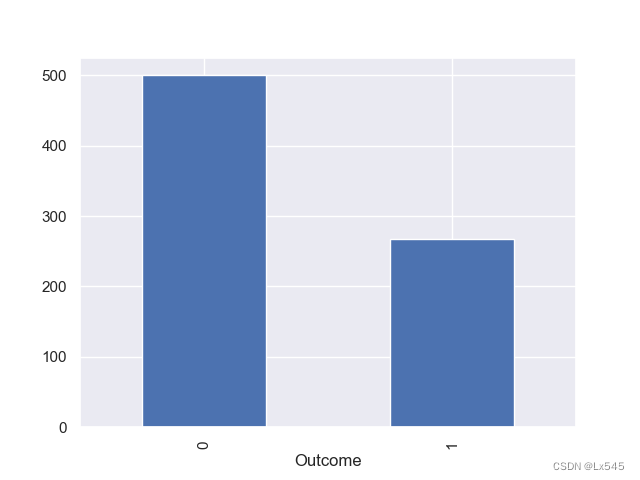
8.用条形图显示结果列的情况,1代表得糖尿病,0代表没有得糖尿病
color_wheel = {1: "#0392cf",2: "#0392cf"}
colors = diabetes_data["Outcome"].map(lambda x : color_wheel.get(x+1))
print(diabetes_data.Outcome.value_counts())
p=diabetes_data.Outcome.value_counts().plot(kind='bar')
plt.show()

9.对副本进行标准化处理(除了outcome列)使得每个特征均值为0,标准差为1,加快模型的收敛速度方便进行knn算法,X为特征部分
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X = pd.DataFrame(sc_X.fit_transform(diabetes_data_copy.drop(["Outcome"],axis = 1),),
columns=['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin',
'BMI', 'DiabetesPedigreeFunction', 'Age'])
X.head()

10.创建目标变量部分
y=diabetes_data_copy.Outcome
11.将数据集划分为训练集和测试集,以便在模型训练和评估过程中使用不同的数据集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=1/3,random_state=42, stratify=y)
train_scores = []
test_scores = []
测试集占1/3,训练集占2/3
stratify = y用于根据目标变量 y 进行分层抽样,以保持训练集和测试集中各类别样本的比例相同
12.书写knn算法
class MyKNN:
def __init__(self, k):
self.k = k
self.X_train = None
self.y_train = None
def fit(self, X, y):
self.X_train = X
self.y_train = y.tolist() # 将Pandas Series转换为列表
def predict(self, X):
y_pred = [self._predict(x) for x in X]
return np.array(y_pred)
def _predict(self, x):
distances = [euclidean_distance(x, x_train) for x_train in self.X_train]
k_indices = np.argsort(distances)[:self.k]
k_nearest_labels = [self.y_train[i] for i in k_indices if i < len(self.y_train)]
most_common = np.bincount(k_nearest_labels).argmax()
return most_common
def score(self, X, y):
y_pred = self.predict(X)
accuracy = np.sum(y_pred == y) / len(y)
return accuracy
13利用knn算法进行训练和评估,存储不同参数下训练集和测试集的得分
my_knn = MyKNN(1) # 创建 MyKNN 实例
X_train_np = X_train.values # 将 X_train 转换为 NumPy 数组
X_test_np = X_test.values
for i in range(1, 15):
my_knn.k = i # 设置不同的 k 值
my_knn.fit(X_train_np, y_train) # 使用转换后的 X_train 进行训练
train_score = my_knn.score(X_train_np, y_train) # 计算训练集得分
test_score = my_knn.score(X_test_np, y_test) # 计算测试集得分
train_scores.append(train_score) # 将训练集得分存入列表
test_scores.append(test_score) # 将测试集得分存入列表
14.分别找出在训练集和测试集上表现最好的K值以及对应的最高训练得分
max_train_score = max(train_scores)
train_scores_ind = [i for i, v in enumerate(train_scores) if v == max_train_score]
print('Max train score {} % and k = {}'.format(max_train_score*100,list(map(lambda x: x+1, train_scores_ind))))

max_test_score = max(test_scores)
test_scores_ind = [i for i, v in enumerate(test_scores) if v == max_test_score]
print('Max test score {} % and k = {}'.format(max_test_score*100,list(map(lambda x: x+1, test_scores_ind))))

15.使用matplotlib和seaborn库绘制了训练集和测试集在不同K值下的得分情况的折线图
plt.figure(figsize=(12,5))
p = sns.lineplot(x=range(1,k),y=train_scores,marker='*',label='Train Score')
p = sns.lineplot(x=range(1,k),y=test_scores,marker='o',label='Test Score')
plt.xlabel('k')
plt.ylabel('accuracy')
plt.show()
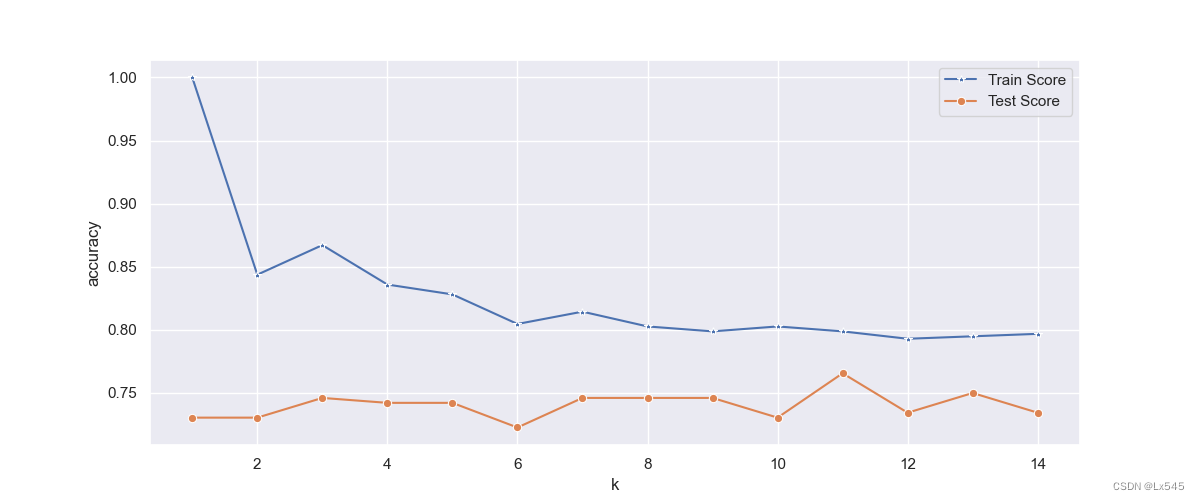
最终选择K=11构建K最近邻分类器
16.显示选择的K=11的预测结果的准确率
knn = MyKNN(11)
knn.fit(X_train_np,y_train)
knn_score = knn.score(X_test_np,y_test)
print(knn_score)

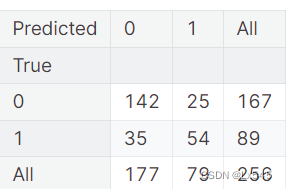
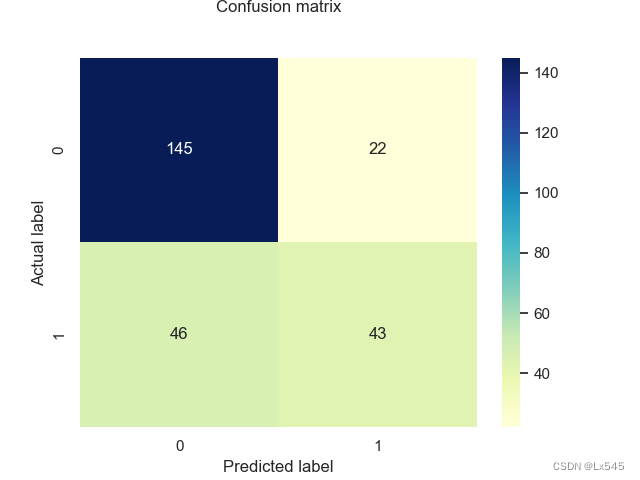
17.使用已经训练好的 K 最近邻分类器对测试集进行预测,得到预测结果 并使用热力图显示预测结果和实际结果的混淆矩阵
y_pred = knn.predict(X_test_np)
from sklearn import metrics
cnf_matrix = metrics.confusion_matrix(y_test, y_pred)
p = sns.heatmap(pd.DataFrame(cnf_matrix), annot=True, cmap="YlGnBu" ,fmt='g')
plt.title('Confusion matrix', y=1.1)
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
plt.show()
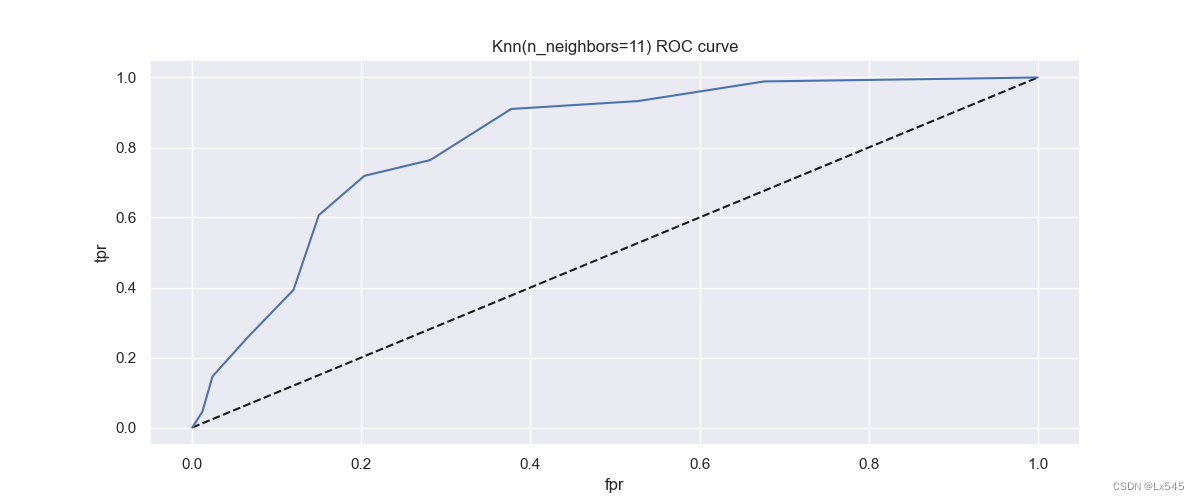
18.绘制ROC曲线评估分类器性能,并计算AUC-ROC值用于性能评估
from sklearn.metrics import classification_report
classification_report = classification_report(y_test,y_pred)
with open('classification_report.txt', 'w') as file:
file.write(classification_report)
from sklearn.metrics import roc_curve
y_pred_proba = knn.predict_proba(X_test)[:,1]
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
plt.plot([0, 1], [0, 1], 'k--')
plt.plot(fpr,tpr, label='Knn')
plt.xlabel('fpr')
plt.ylabel('tpr')
plt.title('Knn(n_neighbors=11) ROC curve')
plt.show()
plt.clf()
from sklearn.metrics import roc_auc_score
print(roc_auc_score(y_test,y_pred_proba))
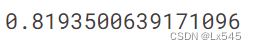


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









