






目录
一、什么是支持向量机?
SMV在众多实例中寻找一个最优的决策边界,这个边界上的实例叫做支持向量,它们“支持”(支撑)分离开超平面,所以它叫支持向量机。
那么我们如何保证我们得到的决策边界是最优的呢?
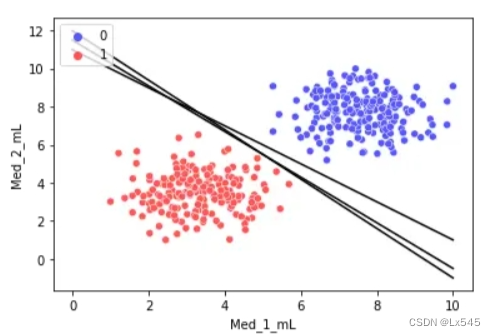
如上图,三条黑色直线都可以完美分割数据集。由此可知,我们仅用单一直线可以得到无数个解。那么,其中怎样的直线是最优的呢?
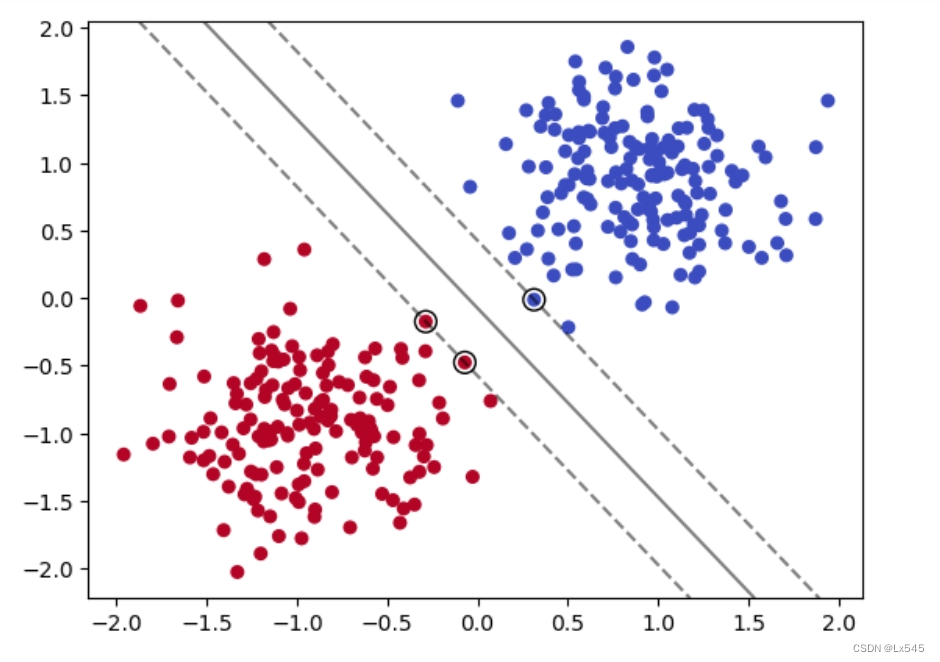
如上图,我们计算直线到分割实例的距离,使得我们的直线与数据集的距离尽可能的远,那么我们就可以得到唯一的解。最大化上图虚线之间的距离就是我们的目标。而上图中重点圈出的实例就叫做支持向量。
这就是支持向量机。
二、实际应用及代码
2.1导入库和数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = '...\mouse_viral_study.csv'
df = pd.read_csv(data)
df.head()
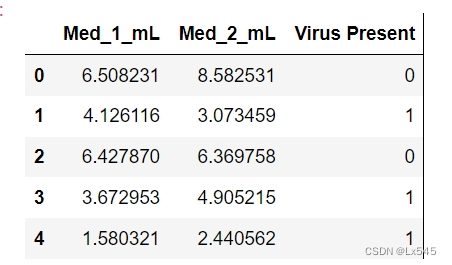
该数据集模拟了一项医学研究,对感染病毒的小白鼠使用不同剂量的两种药物,观察两周后小白鼠是否感染病毒。
特征: 1. 药物Med_1_mL 药物Med_2_mL
标签:是否感染病毒(1感染/0不感染)
2.2数据集的预处理
df.shape #检查数据集大小
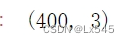
df.info() #获得数据集的基本概要

df.isnull().sum() #检测数据集是否有缺失值

发现没有存在缺失值
2.3 利用pairplot方法绘制特征两两之间的对应关系
sns.pairplot(df, hue='Virus Present')
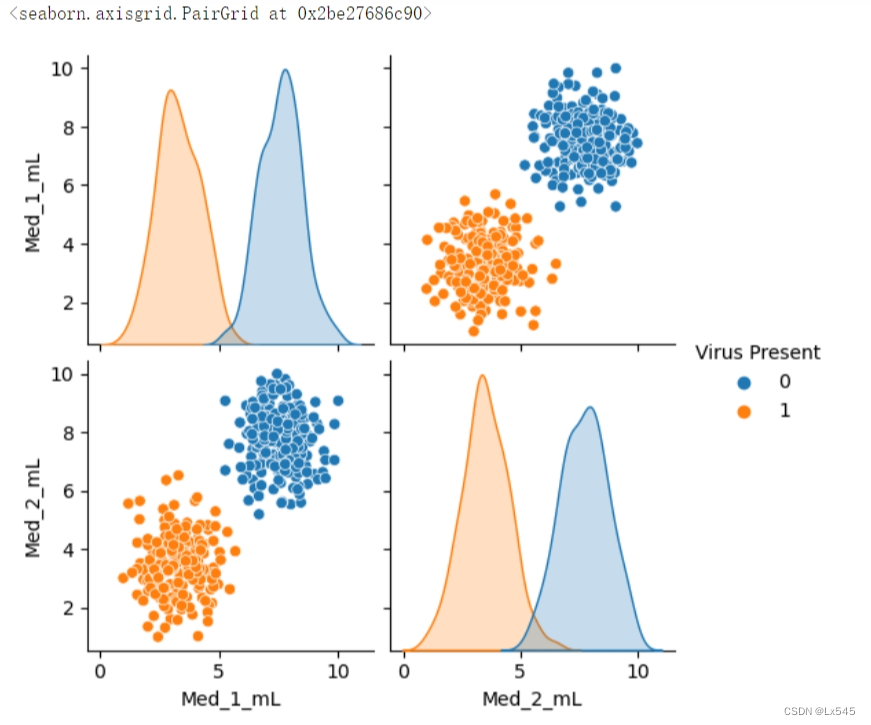
发现随着两种药剂量的增加可以使小白鼠避免被感染
2.4 定义特征变量和目标变量
X = df.drop(['Virus Present'], axis=1)
y = df['Virus Present']
2.5 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
2.6 对训练集和测试集进行标准化处理
cols = X_train.columns
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
X_train = pd.DataFrame(X_train, columns=[cols])
X_test = pd.DataFrame(X_test, columns=[cols])
2.7 使用SVM训练数据集并定义绘制SVM边界的方法
from sklearn.svm import SVC
model = SVC(kernel='linear', C=1000)
model.fit(X_train, y_train)
def plot_svm_boundary(model,X,y):
X = X.values
y = y.values
plt.scatter(X[:, 0], X[:, 1], c=y, s=30,cmap='coolwarm')
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
xx = np.linspace(xlim[0], xlim[1], 30)
yy = np.linspace(ylim[0], ylim[1], 30)
YY, XX = np.meshgrid(yy, xx)
xy = np.vstack([XX.ravel(), YY.ravel()]).T
Z = model.decision_function(xy).reshape(XX.shape)
ax.contour(XX, YY, Z, colors='k', levels=[-1, 0, 1], alpha=0.5,
linestyles=['--', '-', '--'])
ax.scatter(model.support_vectors_[:, 0], model.support_vectors_[:, 1], s=100,
linewidth=1, facecolors='none', edgecolors='k')
plt.show()
plot_svm_boundary(model,X_train,y_train)
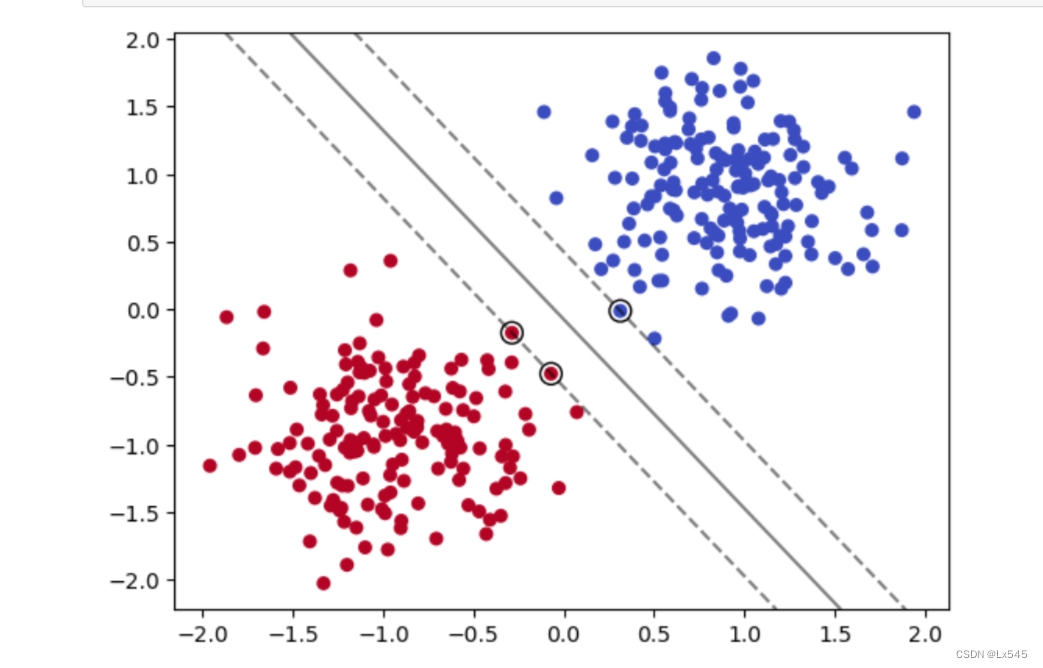
2.8 计算模型预测的准确率
from sklearn.metrics import accuracy_score
y_pred = model.predict(X_test)
print('模型预测的准确率:{0:0.4f}'.format(accuracy_score(y_test,y_pred)))

模型训练效果显著















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









