







Chapter 7
Algorithm 7.1

首先提一下为什么需要Early Stopping。
当我们的训练集比较大的时候,往往容易发生overfit。在这个时候训练误差虽然会随时间稳定下降,但是交叉验证的误差却极其有可能重新上升,如下图所示。
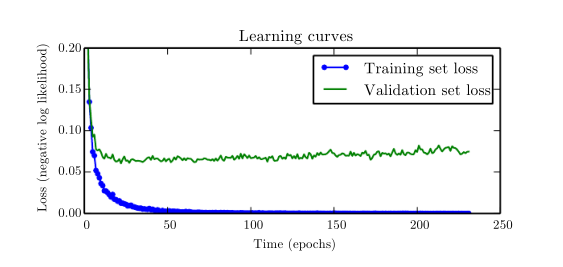
因此我们需要一个early stop,并非让validation error降到一个局部最优解,而是一个全局最优解(在一长段时间内这个error都没有明显的下降)。
这个算法是为了找出什么时候打断训练,即判断一长段时间内validation error没有下降就打断训练过程。这一长段时间是p个时间段,在每个时间段内更新n次
θ
的值,计算这个时候的validation error。如果error下降的话则记录此时的
θ
,重新开启时间的计数,即从这个点开始又观测p个时间段内error是否有下降;如果error没有下降则继续p个时间段上的计时,并且不更新
θ
。如果在这连续p个时间段内error都没有下降,则认为validation error已经到达了最小值,训练发生early stopping。
Algorithm 7.2

7.1中我们看到了的是一个early stopping计算权值的最优值和训练次数最优值的算法过程。而在7.2中,它为7.1的使用构筑了一个框架。
第一次训练:将训练集分成subtrain和valid两部分,subtrain训练,valid进行交叉验证。得到训练次数的最优值。
第二次训练:将第一次训练中训练次数的最优值作为训练次数,整个训练集一起输入,最后得到参数的最优值。(这里的最优是认为的最优,但是不是实际的最优这里无法保证)
Algorithm 7.3

这是相对于7.2的另一种early stopping大框架的算法。它不再追求第几步的时候停止训练,而是监视validation set对应的cost function的值。不断地训练指导它跌到一根线以下。这根线则是由上一次训练停止时,subtrain集合的cost function决定。这个算法可以极大减少计算,但是不能保证一定会收敛。因为J(valid)是否能降到subtrain定下的那个阈值之下都是一个还没有证明的命题。
此外简述以下这章的主要内容。
Chapter7主要讲述的是如何确定一个合适的Regularization。因为一个好的Regularization可以帮助我们的算法改善它的性能,比如更好地generalize我们大量的数据之类的。
7.1 主要谈论的是针对参数的Regularize,这里主要有的是L2,L1 Regularization。L2其实在Andrew Ng的教学视频中是大量提到了的。
7.2 讲得就是Norm Penalties as Constrained Optimization,这一块的关键词主要是限制条件和KKT条件。
7.4 谈的是如何做Dataset Augmentation,简单说就是如何造数据。比如对于Object proposal,你可以旋转图片来减轻样本数量不足的问题。再比如自助加一些noise来强化自己的模型。
7.5 Noise robustness。
7.8 本章重点,early stopping。这里谈到了一点思想,即early stopping本身也可以认为是regularization中的一种。
7.10 稀疏矩阵的表达和处理问题。
7.12 Dropout。(好像也很重要,不过暂时略过,以后补充)

写在最后:
因为这个专题主要针对的是算法,而第七章主要还是如何优化我们神经网络设计的手段,因此算法部分不是很多,内容大量略过。(好吧…其实是懒…后续会在这本书的精析笔记中补充…flag…)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









