







一、Recurrent Neural Networks
Recurrent Neural Networks是用来处理序列数据的网络,即数据不再是散乱地组成一个训练集合。数据之间的排列顺序本身也是具有信息量的。打乱数据之间的排列前后输出的结果是不同的。
一般recurrent neural networks有三种形式:
1) 每步都有输出O,recurrent connections存在于hidden units之间。
2) 每步都有输出O,recurrent connections存在于上一步的Output和下一步的hidden unit之间。
3) 只有最后一步有一个输出O,recurrent connections存在于hidden units之间。
对于形式1),它的图像表示为:
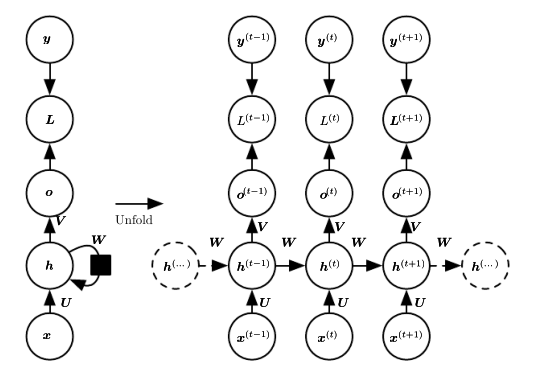
其中hidden units->hidden units,input->hidden units,hidden units->output units的权值矩阵都是共享的。它的前向通道可以借由它们图中的线性组合以及相应的一些非线性激励单元表示为:
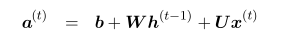
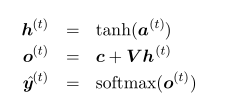
另外2)类型和3)类型的示例图分别如下:
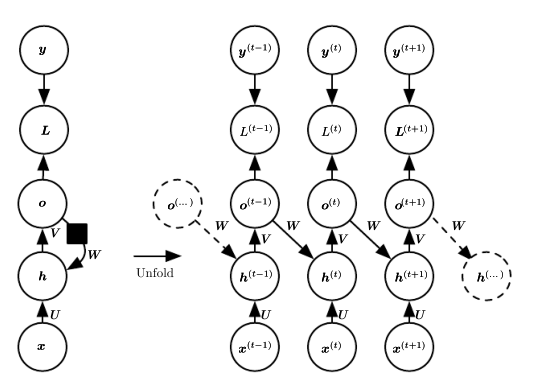
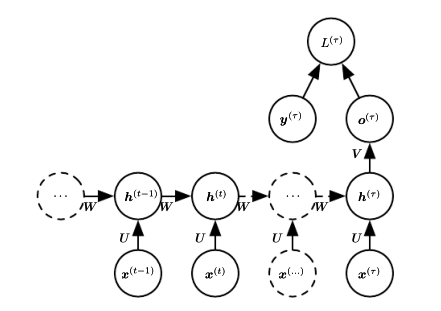
类型2)缺少hidden-to-hidden的直接recurrent connections,这导致了这个模型本身是不如类型1)有力的。为了保障类型2)的工作效果客观,需要让output units能够保留足够的过去信息来供之后的hidden units使用。前向传输过程中有价值信息的损失是类型2)的缺点。
类型2)的优点是,有利于Backprop的计算,因为这样就可以达到关于时间t的解耦。对于这个解耦怎么理解,个人是这么看的,可能存在不妥的地方:backprop是cost function对网络中的各个参数找其梯度下降的方向的迭代过程。对于类型1),连接整个网络的是hidden units,但是给出cost function的是output units。在这种情况下output units是整根链条额外拉出来的单元,并非是链条本身的组员,backprop从末往前推的过程中,每过一个单元就要因为这个cost function的位置特性而卡一下,因而不利于计算。但是对于类型2),output units本身就是这根序列链条的一部分,这可以使得backprop求梯度的过程更为便捷。具体的可能还是要手算一下才能更具体地理解。
Recurrent neural networks的backprop方法有计算梯度的(公式可直接推导得到),也有一种teacher forcing的方法。后种相对比较新。
Recurrent networks作为directed graphical models和modeling sequences conditioned on context with RNNs这两章暂时没有很看懂。
二、 Bidirectional RNNs
这类RNN是考虑 y(t) 依赖于整个输入序列。比如在语音识别里面,一个词的理解既依赖于它之前的句义,又依赖于它之后的句义。除此之外它还应用于手写识别和生物信息处理。
这里在普通recurrent neural network的基础上加了一条反向链,即从t->0时刻的。i时刻的输出值既依赖此时正向链的hidden units也依赖于反向链的hidden units。如图所示:
三、 Encoder-Decoder Sequence-to-Sequence结构
RNN的input又称为context。从前面Recurrent neural network的类型1)和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









