







 本文介绍了深度学习中两种重要的Monte Carlo方法:Importance Sampling和Markov Chain Monte Carlo (MCMC)。Importance Sampling通过调整采样分布减少计算复杂度,而MCMC利用细致平稳条件达到稳态,包括Metropolis-Hastings和Gibbs Sampling算法。这两种方法在处理复杂函数积分和高维分布采样时非常有用。
本文介绍了深度学习中两种重要的Monte Carlo方法:Importance Sampling和Markov Chain Monte Carlo (MCMC)。Importance Sampling通过调整采样分布减少计算复杂度,而MCMC利用细致平稳条件达到稳态,包括Metropolis-Hastings和Gibbs Sampling算法。这两种方法在处理复杂函数积分和高维分布采样时非常有用。
一、Importance Sampling
对于一个比较复杂函数的积分,我们往往是在这条乱七八糟的取消下面画方格,对方格做累加来近似这个函数的积分;方格的高就是此时的函数值,方格的宽度依据采样的方式决定。
均匀采样:
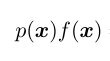
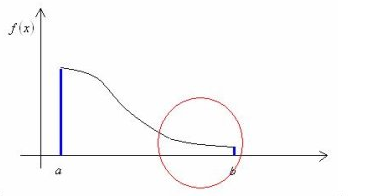
这里x是随机变量,它的分布式p(x),f(x)就是这个随机变量的函数。但是它带来的问题是如果f(x)的分布是在一段值特别大,而另一段值特别接近零。那么如果还采用均匀采样,在f(x)值大的区域就容易出现误差,而在f(x)值小的区域,过于频繁的采样便成了一种浪费。比如这张图里面的情况:
因此我们想要将上面的式子做适当的变形,也就有了Importance Sampling(重要性采样):
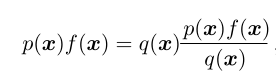
这里认为q(x)是x的分布,而右边的那个分式是随机变量x的函数。最优的q(x)的选择q*表达式如下:
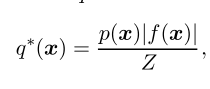
Z是归一化常数,使得q(x)的积分为1,保证它是一个有效的概率密度函数。
i)从这个表达式本身出发,我们可以看到它的效果是使得随机变量x的概率分布基本就是一个常数了(可能会有负的部分)。换句话说,它将随机变量的函数的复杂度转移到了随机变量的概率分布函数上,就是值简单,但是采样过程复杂了。对于Monte Carlo而言,采样是一个相对比较容易操作的过程,但是函数值相对不能把控。上面所说的这个复杂度的转移(Importance Sampling)使得average的计算可以在Monte Carlo的框架下比较简易地得到解决。
ii)从这个表达式的求取过程出发:
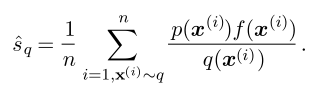
一个好的q(x)可以使得
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









