






本代码使用手写方法实现自注意力网络,是指每个模块手写而并非任何库都不可调用。有一点顺序问题是tokenizer直接用的Bert的,所以只供参考。
1.库函数
#引入库部分
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset, Subset
from torch.nn.utils.rnn import pad_sequence
from transformers import BertTokenizer, BertModel, BertConfig
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
import os
print("import OK")其中torch和transformer版本为:
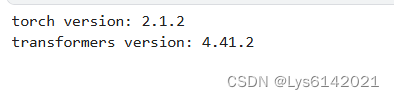
tqdm什么的就无所谓了,没见过它们因为版本问题报错hhh。
2.一系列可更改项
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
train_text_path = "/kaggle/input/tonlpp/data/train_s.txt"
train_tag_path = "/kaggle/input/tonlpp/data/train_TAG_s.txt"
dev_text_path = "/kaggle/input/tonlpp/data/dev.txt"
dev_tag_path = "/kaggle/input/tonlpp/data/dev_TAG.txt"
test_text_path = "/kaggle/input/tonlpp/data/test.txt"
vocab_size = tokenizer.vocab_size
embed_size = 768
num_heads = 8 #自注意力头数
ff_hidden_size = 2048
num_layers = 6 #Encoder Layer层数
max_len = 128
num_labels = len(label_set)
dropout = 0.1
num_epochs = 10
train_losses = []
dev_accuracies = []用的纯编码器模型。
3.导入数据
def read_data(text_path, tag_path):
with open(text_path, "r", encoding="utf-8") as f:
texts = f.readlines()
with open(tag_path, "r", encoding="utf-8") as f:
tags = f.readlines()
return texts, tags
train_texts, train_tags = read_data(train_text_path, train_tag_path)
dev_texts, dev_tags = read_data(dev_text_path, dev_tag_path)
#打印标签集
def get_label_set(tags):
label_set = set()
for tag_seq in tags:
label_set.update(tag_seq.strip().split())
return label_set
label_set = get_label_set(train_tags)
print(f"Label set: {label_set}")
#标签映射,用于对应组合2个文件以训练
label2id = {label: idx for idx, label in enumerate(label_set)}
id2label = {idx: label for label, idx in label2id.items()}打印标签集结果为:

4.transformer网络部分
1).构建输入向量
#将输入的token索引转换为嵌入向量
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size, embed_size):
super(TokenEmbedding, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
def forward(self, x):
return self.embedding(x)
#将位置信息嵌入到输入向量
class PositionalEmbedding(nn.Module):
def __init__(self, max_len, embed_size):
super(PositionalEmbedding, self).__init__()
self.pos_embedding = nn.Embedding(max_len, embed_size)
self.register_buffer("position_ids", torch.arange(max_len).expand((1, -1)))
def forward(self, x):
position_ids = self.position_ids[:, :x.size(1)]
return self.pos_embedding(position_ids)二者的加和在后面实现。
2).多自注意力头
其形状近似于: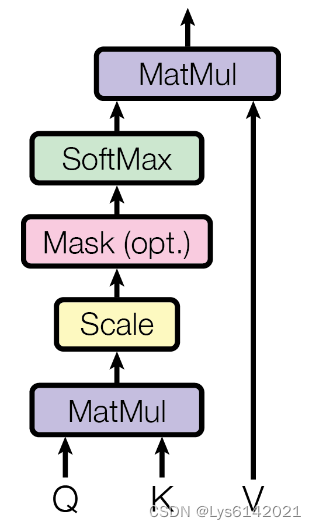
相关数学公式有:
#使用多头注意力机制,将输入的values、keys、queries通过线性变换生成新的表示,
#使用einsum计算注意力得分
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.embed_size = embed_size
assert embed_size % num_heads == 0, "Embedding size 必须能被 num_heads 整除"
self.head_dim = embed_size // num_heads
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(num_heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
values = values.reshape(N, value_len, self.num_heads, self.head_dim)
keys = keys.reshape(N, key_len, self.num_heads, self.head_dim)
queries = query.reshape(N, query_len, self.num_heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
mask = mask.unsqueeze(1).unsqueeze(2)
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.num_heads * self.head_dim)
return self.fc_out(out)以这一部分为例,使用了爱因斯坦求和约定的缩写,使用简洁的符号来表示张量操作。

其意思是对于每个头,每个查询向量和所有的键向量
进行点积操作,得到一个形状为
的注意力权重矩阵,其中每个元素表示某个查询和某个键之间的相似度。
其它量里,n表示批量大小,q表示查询长度,k表示键的长度,h表示头的数量,d表示每个头的维度。
3).FeedForward层:
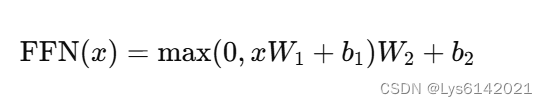
#添加2个全连接层+ReLU的前馈神经网络增强捕捉输入序列关系的能力
class FeedForwardNetwork(nn.Module):
def __init__(self, embed_size, ff_hidden_size):
super(FeedForwardNetwork, self).__init__()
self.fc1 = nn.Linear(embed_size, ff_hidden_size)
self.fc2 = nn.Linear(ff_hidden_size, embed_size)
def forward(self, x):
return self.fc2(torch.relu(self.fc1(x)))4).单个Encoder Layer
#编码器层,进行自注意力计算、残差连接、归一化、Dropout
class EncoderLayer(nn.Module):
def __init__(self, embed_size, num_heads, ff_hidden_size, dropout):
super(EncoderLayer, self).__init__()
self.multi_head_attention = MultiHeadAttention(embed_size, num_heads)
self.feed_forward = FeedForwardNetwork(embed_size, ff_hidden_size)
self.layernorm1 = nn.LayerNorm(embed_size)
self.layernorm2 = nn.LayerNorm(embed_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
attention = self.multi_head_attention(x, x, x, mask)
x = self.layernorm1(attention + x)
x = self.dropout(x)
forward = self.feed_forward(x)
out = self.layernorm2(forward + x)
out = self.dropout(out)
return out5).整个结构
#总结构定义位置,堆叠6层EncoderLayer
class TransformerEncoder(nn.Module):
def __init__(self, vocab_size, embed_size, num_heads, ff_hidden_size, num_layers, max_len, num_labels, dropout):
super(TransformerEncoder, self).__init__()
self.token_embedding = TokenEmbedding(vocab_size, embed_size)
self.position_embedding = PositionalEmbedding(max_len, embed_size)
self.layers = nn.ModuleList(
[EncoderLayer(embed_size, num_heads, ff_hidden_size, dropout) for _ in range(num_layers)]
)
self.fc_out = nn.Linear(embed_size, num_labels)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
token_embeddings = self.token_embedding(x)
position_embeddings = self.position_embedding(x)
x = self.dropout(token_embeddings + position_embeddings)
for layer in self.layers:
x = layer(x, mask)
return self.fc_out(x)结构参考自这里:
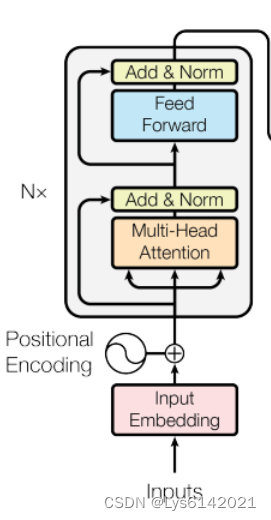
5.构建数据集
#DataLoader时作为collate_fn参数传入,防数组溢出
def collate_fn(batch):
input_ids, attention_mask, labels = zip(*batch)
max_len = max([len(seq) for seq in input_ids])
input_ids = pad_sequence(input_ids, batch_first=True, padding_value=tokenizer.pad_token_id)
attention_mask = pad_sequence(attention_mask, batch_first=True, padding_value=0)
labels = pad_sequence(labels, batch_first=True, padding_value=label2id['O'])
input_ids = input_ids[:, :max_len]
attention_mask = attention_mask[:, :max_len]
labels = labels[:, :max_len]
#调试填充后大小
#print(f"input_ids shape: {input_ids.shape}")
#print(f"attention_mask shape: {attention_mask.shape}")
#print(f"labels shape: {labels.shape}")
return input_ids, attention_mask, labels
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
#创建数据集和数据加载器
train_dataset = NERDataset(train_texts, train_tags, tokenizer, label2id)
dev_dataset = NERDataset(dev_texts, dev_tags, tokenizer, label2id)
'''
train_subset = Subset(train_dataset, [2565,2566,2567,2568,2569,2570,2571])
train_loader = DataLoader(train_subset, batch_size=32, shuffle=True, collate_fn=collate_fn)
dev_subset = Subset(dev_dataset, range(3))
dev_loader = DataLoader(dev_subset, batch_size=32, shuffle=False, collate_fn=collate_fn)
'''
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, collate_fn=collate_fn)
dev_loader = DataLoader(dev_dataset, batch_size=32, shuffle=False, collate_fn=collate_fn)
print("OK")调试代码的时候,可以把subset部分代码取消注释,只加载一部分数据集用以加速。
6.定义模型并输出整体结构
#定义模型
model = TransformerEncoder(vocab_size, embed_size, num_heads, ff_hidden_size, num_layers, max_len, num_labels, dropout).to(device)
#model.load_state_dict(torch.load("/kaggle/working/transformer_ner_model.pth"))
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=5e-5)
model_info = {
"model_structure": str(model),
"vocab_size": vocab_size,
"embed_size": embed_size,
"num_heads": num_heads,
"ff_hidden_size": ff_hidden_size,
"num_layers": num_layers,
"max_len": max_len,
"num_labels": num_labels,
"dropout": dropout,
"initial_embedding_source": "BERT base Chinese",
"optimizer": "AdamW",
"learning_rate": 5e-5,
"batch_size": 32,
"num_epochs": 10
}
with open("model_info.txt", "w") as f:
for key, value in model_info.items():
f.write(f"{key}: {value}\n")
print("模型权重已加载,模型信息已保存到 model_info.txt")模型整体结构与相关超参数为:

注意!超参数不在这里改,这就是个输出。
7.模型训练部分
def calculate_accuracy(predictions, labels):
_, preds = torch.max(predictions, dim=1)
correct = (preds == labels)
accuracy = correct.sum().float() / len(labels)
return accuracy
for epoch in range(num_epochs):
model.train()
total_loss = 0
for input_ids, attention_mask, labels in tqdm(train_loader, desc=f"Training Epoch {epoch+1}/{num_epochs}"):
input_ids, attention_mask, labels = input_ids.to(device), attention_mask.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask)
#调整形状
batch_size, seq_len, num_labels = outputs.size()
outputs = outputs.reshape(batch_size * seq_len, num_labels)
labels = labels.reshape(batch_size * seq_len)
# 调试输出形状
#print(f"Epoch {epoch+1}/{num_epochs} - Batch size: {batch_size}, Seq length: {seq_len}")
#print(f"outputs shape: {outputs.shape}")
#print(f"labels shape: {labels.shape}")
if outputs.size(0) != labels.size(0):
print(f"Shape mismatch: outputs {outputs.size(0)}, labels {labels.size(0)}")
continue
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_train_loss = total_loss / len(train_loader)
train_losses.append(avg_train_loss)
model.eval()
total_accuracy = 0
with torch.no_grad():
for input_ids, attention_mask, labels in tqdm(dev_loader, desc=f"Testing Epoch {epoch+1}/{num_epochs}"):
input_ids, attention_mask, labels = input_ids.to(device), attention_mask.to(device), labels.to(device)
outputs = model(input_ids, attention_mask)
#调整形状
batch_size, seq_len, num_labels = outputs.size()
outputs = outputs.reshape(batch_size * seq_len, num_labels)
labels = labels.reshape(batch_size * seq_len)
accuracy = calculate_accuracy(outputs, labels)
total_accuracy += accuracy.item()
avg_dev_accuracy = total_accuracy / len(dev_loader)
dev_accuracies.append(avg_dev_accuracy)
print(f"Epoch {epoch+1}/{num_epochs} - Train Loss: {avg_train_loss:.4f} - Dev Accuracy: {avg_dev_accuracy:.4f}") 输出结果为:
8.可视化结果
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(range(num_epochs), train_losses, label="Train Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss")
plt.subplot(1, 2, 2)
plt.plot(range(num_epochs), dev_accuracies, label="Dev Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.title("Dev Accuracy")
plt.tight_layout()
plt.savefig("training_curves.png")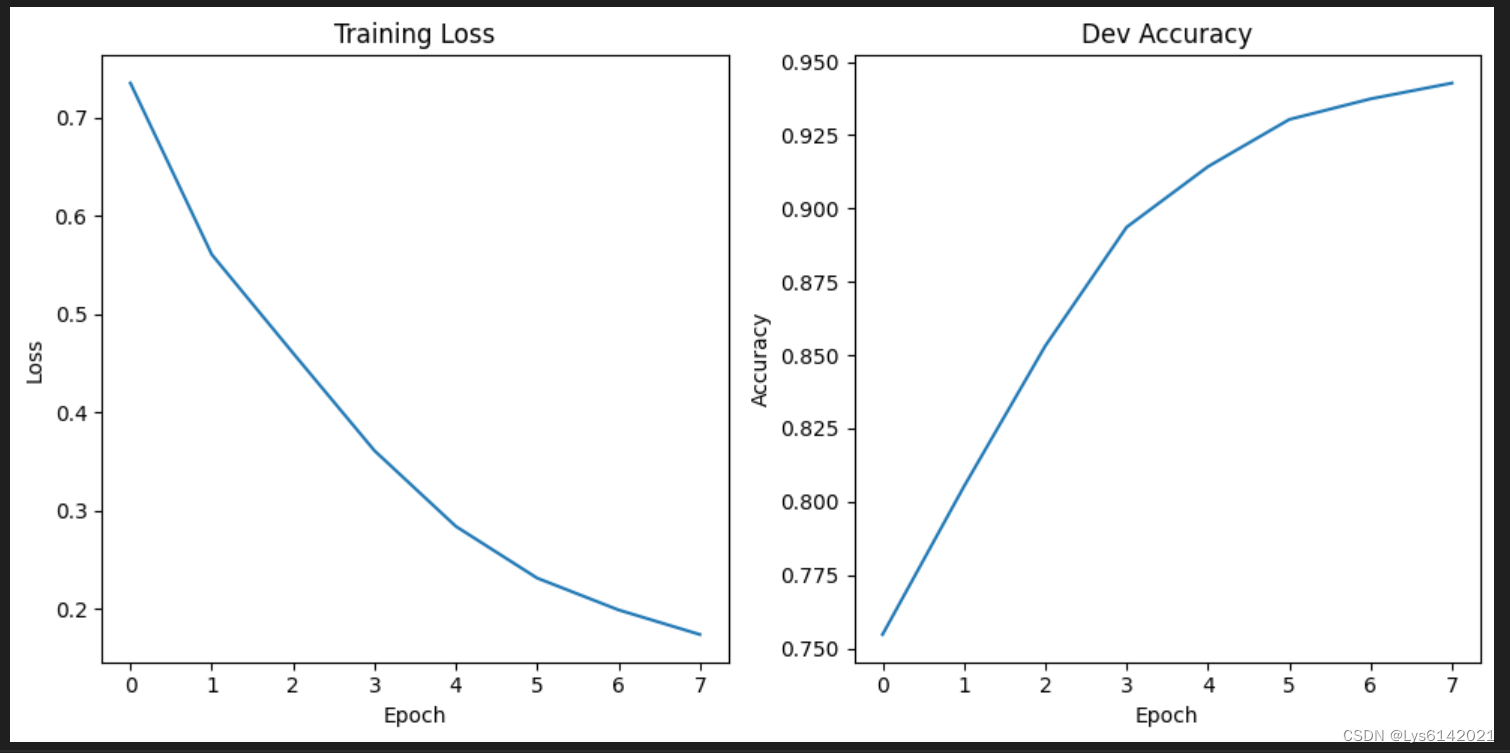
9.保存模型
torch.save(model.state_dict(), "transformer_ner_model.pth")
print("OK")10.总结
对于Transformer模型的理解可参照另一篇文章:
Transformer|《Attention Is All You Need》论文阅读笔记
虽然是个纯编码器模型,但效果很好。
因为这是NLP课的一次作业另外此时分还没出,如果有幸被助教看到这篇文章请注意此时第二次作业已经截止了这篇文章是截止之后发的是我写的不是我抄的别扣我分了我已经分不多了再扣我分我真的活不下去了啊啊啊啊啊啊啊啊啊!
另外,还有一部分根据只有文本信息的test.txt输出改为全标签的内容没有公开,如果需要可以留言。
(输出是酱紫的↓)
















 588
588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









