






GPT通过在各种未标注文本语料库上对语言模型进行生成性预训练,然后在每个特定任务上进行判别性微调,可以在使用大量数据集进行训练下,迁移到大多数NLP任务之上。
GPT是基于Transformer模型建立起来的,因为相比于LSTM其具有更好的并行存储计算能力,并能记忆更长的上下文相关信息,并采用纯解码器的结构构造。
一、数学公式理解
1.预训练无监督生成
在预训练阶段,GPT使用了大量的未标注文本数据进行训练,目标是语言建模任务。具体来说,GPT通过预测序列中的下一个词块来进行训练,其目标函数为:
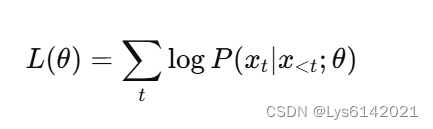
其中,是序列中的第
个词块,
是模型参数。
具体的公式展开,涉及到以下几个公式:
输入嵌入公式:
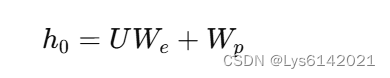
是上下文词块(content tokens)的向量表示,每个元素是对应token的索引,其中
是上下文窗口大小,表示在当前词之前的
个词。
是词嵌入矩阵(token embedding matrix)。每个token通过这个矩阵转换为一个向量表示,其可以是随机初始化的也可以是预训练好的词嵌入(如Word2Vec、GloVe或BERT)。二者相乘后相当于根据前文查找词的索引词嵌入矩阵,得到嵌入向量(缺一个位置信息)。
是位置嵌入矩阵(position embedding matrix),位置嵌入是为了引入序列中词块的位置信息,公式如下:
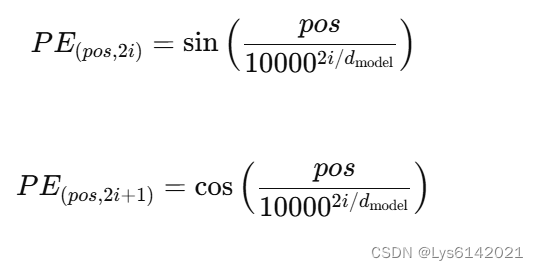
该位置编码为Transformer的经典位置编码,可参照四、位置编码。做和后的 是初始的嵌入表示,接下来将输入到 transformer 模块中。
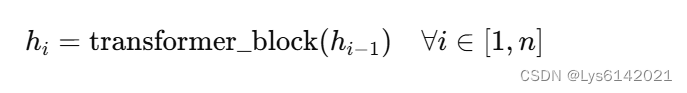
其中, 是 Transformer层的数量,在GPT-1(原始GPT)模型中是12;
transformer_block 包括以下部分,具体原理与内容可参照:Transformer|《Attention Is All You Need》论文阅读笔记![]() https://blog.csdn.net/Lys6142021/article/details/139705331?spm=1001.2014.3001.5501 多头自注意力机制(Multi-Head Self-Attention Mechanism)
https://blog.csdn.net/Lys6142021/article/details/139705331?spm=1001.2014.3001.5501 多头自注意力机制(Multi-Head Self-Attention Mechanism)
前馈神经网络(Feed Forward Neural Network, FFN)
残差连接(Residual Connection)
层归一化(Layer Normalization)
接下来是将 Transformer 的输出,也就是当前 token 与之前的 token 共同影响下生成的上下文感知回馈到词嵌入中来确定生成哪一个 token:
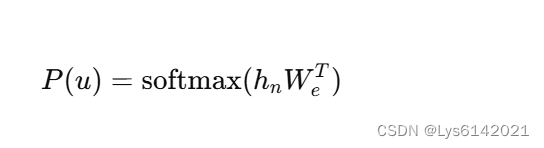
是通过
层 Transformer 块后的最终表示,
是词嵌入矩阵的转置,
softmax 函数用于将线性变换后的向量转换为概率分布,这个公式表示使用最终的表示 和词嵌入矩阵的转置
,将高维表示映射回词汇表的维度。这一步的目的是将模型对当前词块的理解转换为对每个词块在词汇表中的相关性,计算每个词的概率分布
。
2.有监督微调
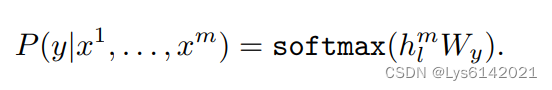
该公式表示在给定序列的情况下,输出 的概率,其中
表示经过
层 Transformer 块后的第
个词块的隐藏状态;
是一个线性变换矩阵,用于将隐藏状态映射到输出词汇表的概率分布。这里可以和
对比。
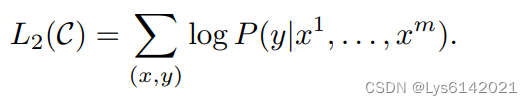
进一步目标函数变为上图,这个目标函数表示希望最大化模型预测正确输出的概率,或者等价地最小化负对数似然损失。
因此总的目标函数可表示为:
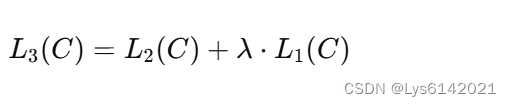
引入 调整预训练无监督生成的目标函数大小。
二、下游任务调整
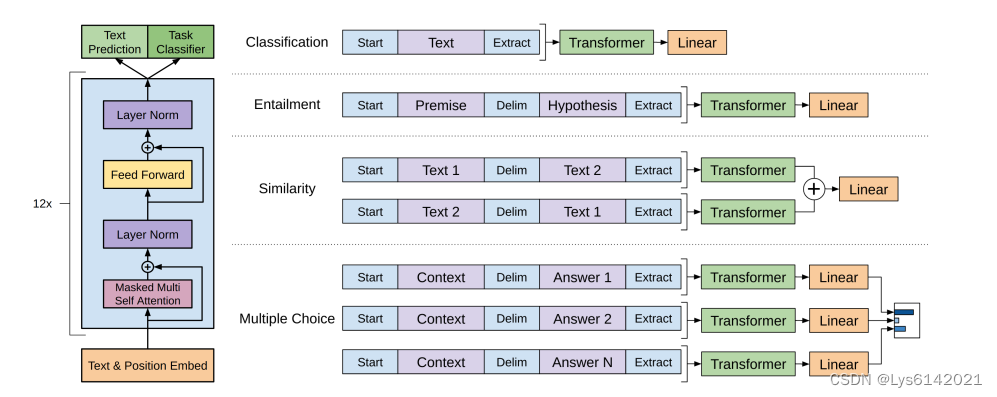
现在可以看懂上图中的左部分,也就是 GPT 的结构示意图。GPT 与 BERT 相比,需要进行更复杂一些的微调:
1.分类任务(Classification)
输入格式:
输入序列由一个起始标记(Start)、文本(Text)和一个提取标记(Extract)组成,起始标记和提取标记用于帮助模型理解输入的结构。
流程:
- 通过词嵌入和位置嵌入表示输入序列。
- 嵌入后的序列通过12层的Transformer解码器进行处理。
- 最终的隐藏状态
通过一个线性层转换为分类标签的概率分布。
2.蕴含任务(Entailment)
输入格式:
输入序列由一个起始标记(Start)、前提(Premise)、分隔标记(Delim)、假设(Hypothesis)和一个提取标记(Extract)组成。前提和假设之间用分隔标记分开,帮助模型理解两个文本片段之间的关系。
流程:
- 通过词嵌入和位置嵌入表示输入序列。
- 嵌入后的序列通过12层的Transformer解码器进行处理。
- 最终的隐藏状态
3.相似性判断(Similarity)
输入格式:
输入序列由一个起始标记(Start)、文本1(Text 1)、分隔标记(Delim)、文本2(Text 2)和一个提取标记(Extract)组成。文本1和文本2之间用分隔标记分开,帮助模型理解两个文本片段之间的相似性。
流程:
- 通过词嵌入和位置嵌入表示输入序列。
- 嵌入后的序列通过两个独立的 Transformer 解码器进行处理。
- 两个 Transformer 的输出通过一个线性层映射到相似性分数。
使用两个独立的 Transformer 解码器进行处理是为了充分考虑输入文本顺序造成的差异。
4.多项选择(Multiple Choice)
输入格式:
输入序列由一个起始标记(Start)、上下文(Context)、分隔标记(Delim)和多个答案(Answer 1, Answer 2, ..., Answer N)组成,每个答案都单独处理。
流程:
- 对于每个答案,构建一个输入序列:起始标记(Start)、上下文(Context)、分隔标记(Delim)、答案(Answer)和提取标记(Extract)。
- 每个输入序列通过词嵌入和位置嵌入层。
- 嵌入后的序列通过12层的Transformer解码器进行处理。
- 每个答案的隐藏状态
- 对所有答案的概率分布进行合并,选择最可能的答案。
5.NER任务
输入格式:
输入序列由一个起始标记(Start)、文本(Text)和一个提取标记(Extract)组成。每个词块将被标注为B、I或O标签。
流程:
- 输入嵌入和位置嵌入:通过词嵌入和位置嵌入表示输入序列。
- Transformer处理:嵌入后的序列通过12层的Transformer解码器进行处理。
- 线性层和标签概率分布:每个词块的最终隐藏状态通过一个线性层转换为实体标签(B、I、O)的概率分布。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









