







线性回归

线性回归模型的均方差损失函数是一个凸函数,这意味着如果你选择曲线上的任意 两点,它们的连线段不会与曲线发生交叉(译者注:该线段不会与曲线有第三个交点)。这 意味着这个损失函数没有局部最小值,仅仅只有一个全局最小值。同时它也是一个斜率不能 突变的连续函数。这两个因素导致了一个好的结果:梯度下降可以无限接近全局最小值。 (只要你训练时间足够长,同时学习率不是太大 )。
训练模型意味着找到一组模型参数,这组参数可以在训练集上使 得损失函数最小。这是对于模型参数空间的搜索,模型的参数越多,参数空间的维度越多, 找到合适的参数越困难。例如在300维的空间找到一枚针要比在三维空间里找到一枚针复杂的 多。幸运的是线性回归模型的损失函数是凸函数,这个最优参数一定在碗的底部。

逻辑回归
Logistic 回归 (也称为 Logit 回归)通常用于估计一个实例属于某个特定类别的概率。 如果估计的概率大于 50%,那么模型预测这个实例属于当前类 (称为正类,标记为“1”),反之预测它不属于当前类(即它属于负类 ,标记为“0”)。 这样 便成为了一个二元分类器。


loss

使用这个loss的合理性:


这里有一些有趣的地方:
对数损失函数的偏导数和MSE损失函数的偏导数形式大致相同。
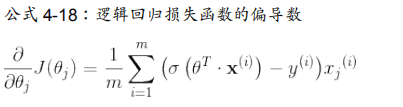
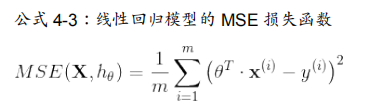

注:使用时,LR.predict_proba是做回归问题用的,LR.predict是做分类问题用的
softmax回归
Softmax 回归模型首先计算 第k类 的分数 ,然 后将分数应用在 Softmax 函数(也称为归一化指数)上,估计出每类的概率。 计算的公式看起来很熟悉,因为它就像线性回归预测的公式一样。



loss
现在我们知道这个模型如何估计概率并进行预测,接下来将介绍如何训练。我们的目标是建 立一个模型在目标类别上有着较高的概率(因此其他类别的概率较低),最小化loss公式 可 以达到这个目标,其表示了当前模型的损失函数,称为交叉熵,当模型对目标类得出了一个 较低的概率,其会惩罚这个模型。 交叉熵通常用于衡量待测类别与目标类别的匹配程度

(算是log loss的升级版,适用于多分类)















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









