







最近抓取了搜狗微信的数据,虽然也破解了跳转之类的,但是最后因为抓取的链接有时效性放弃了,也总结下
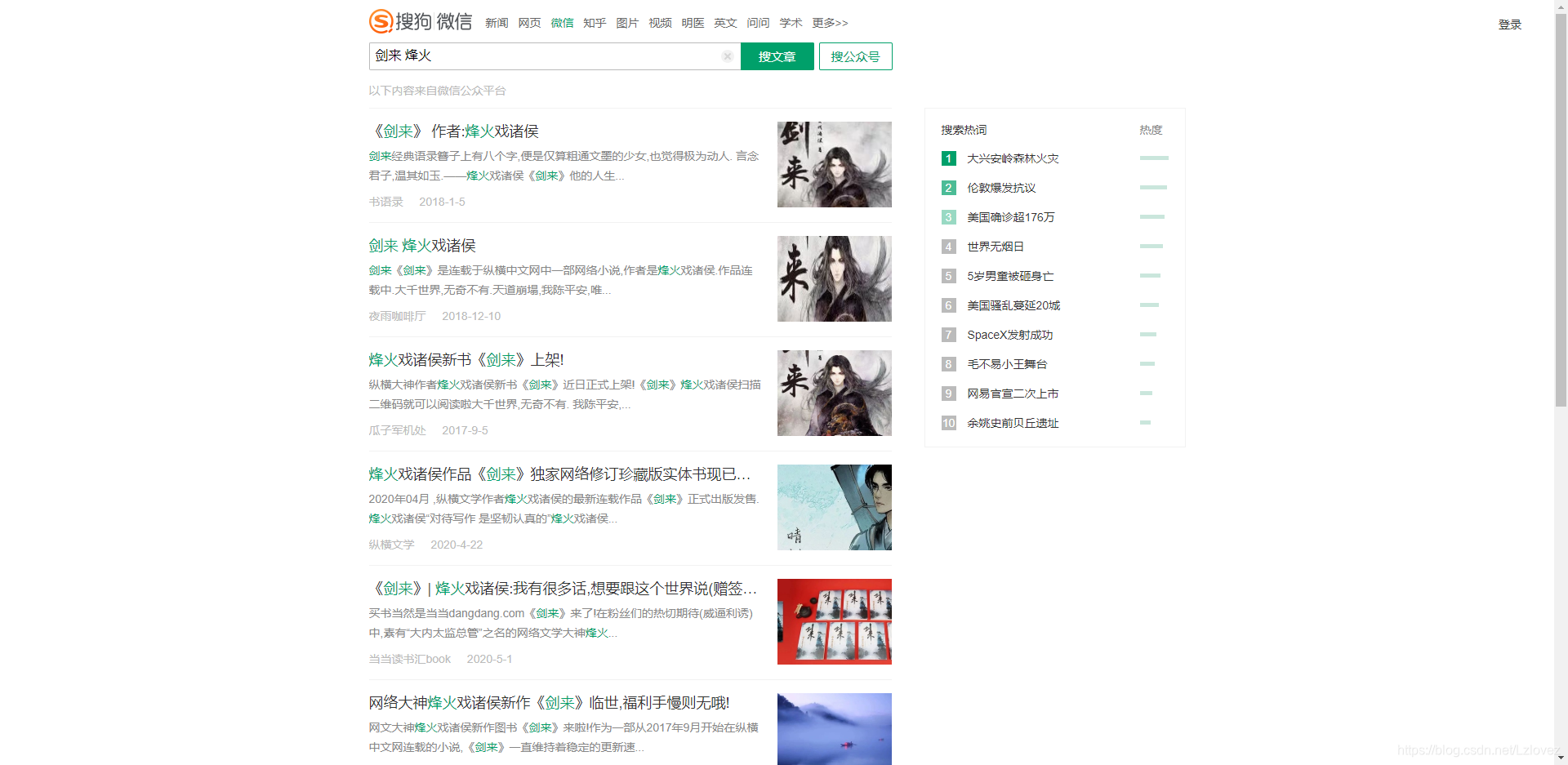
一样的,输入关键词,抓取列表,再回去跳转后的微信链接
前10页是可以随便看的,也不需要登录,10页之后的数据需要微信扫码登录,这一块没法破解
链接参数很多最后可以精简为
https://weixin.sogou.com/weixin?query=烽火&page=11&type=2
page就是页码,query就是关键字,type 是搜索文章还是搜索公众号
- 获取真实链接
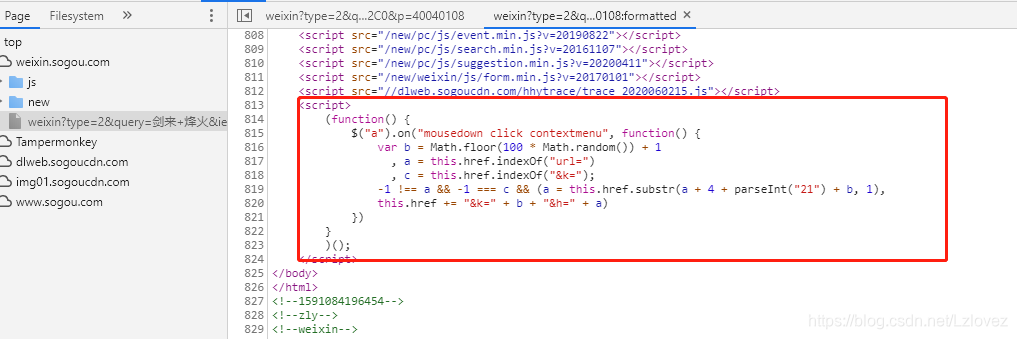
其实很简单的代码,先要在url后面构造出 k 和 h,转化为 java 代码就是
// 拼接搜狗跳转参数k和h
public static String getLinkUrl(String url) {
int b = ((int) Math.floor(100 * Math.random())) + 1;
int a = url.indexOf("url=");
int k = a + 4 + 21 + b;
String d = url.substring(k, k + 1);
System.out.println(d);
url += "&k=" + b + "&h=" + d;
return "https://weixin.sogou.com" + url;
}有参数的链接直接请求是会出验证码的,需要cookie,需要的cookie只要是两个 一个是 SUV,一个是 SNUID,这两个cookie获取都很简单,通过分析可以得到
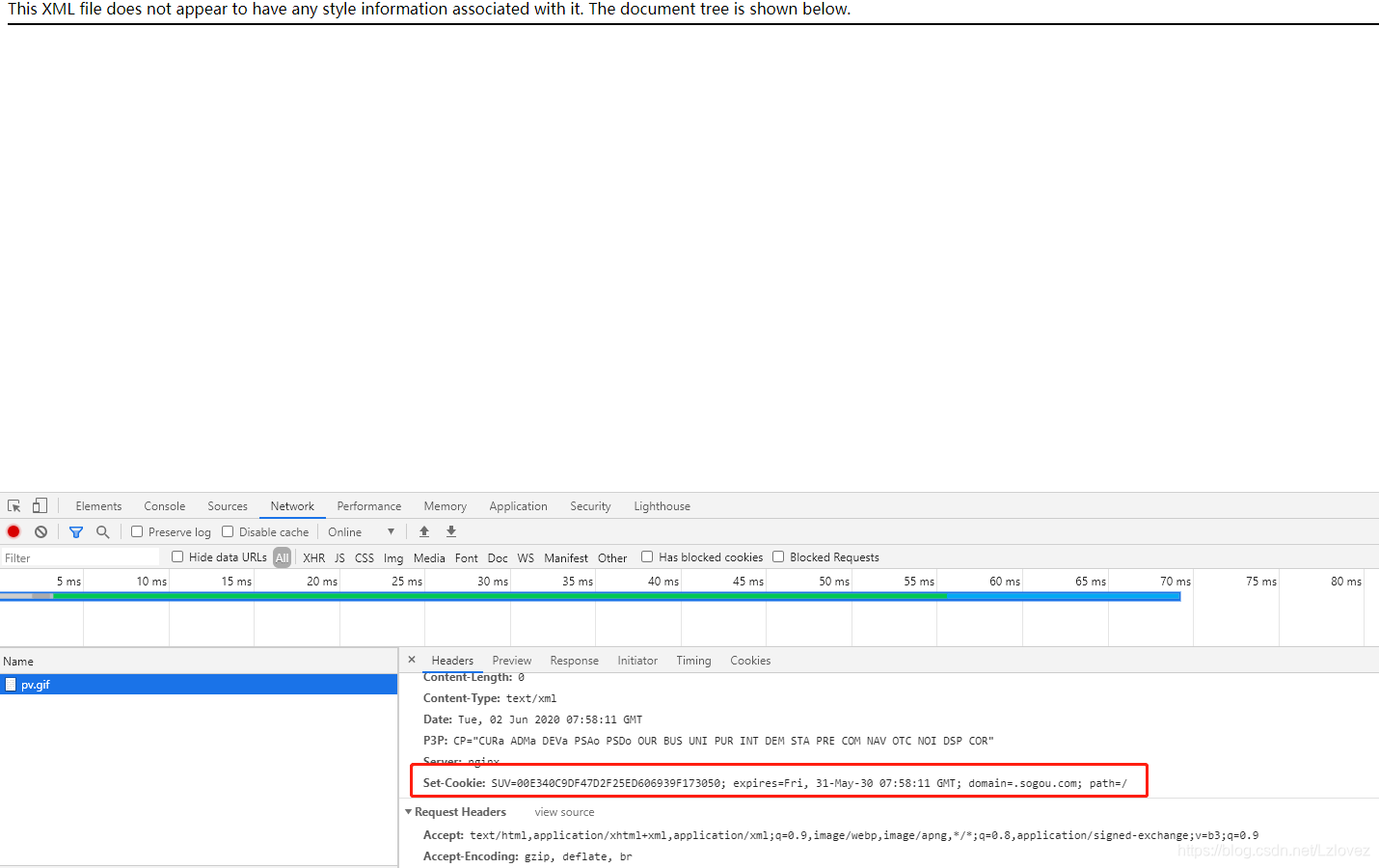
1.SUV 是可以通过访问 https://pb.sogou.com/pv.gif 来获取到
2.SNUID 在搜索的时候就会有了
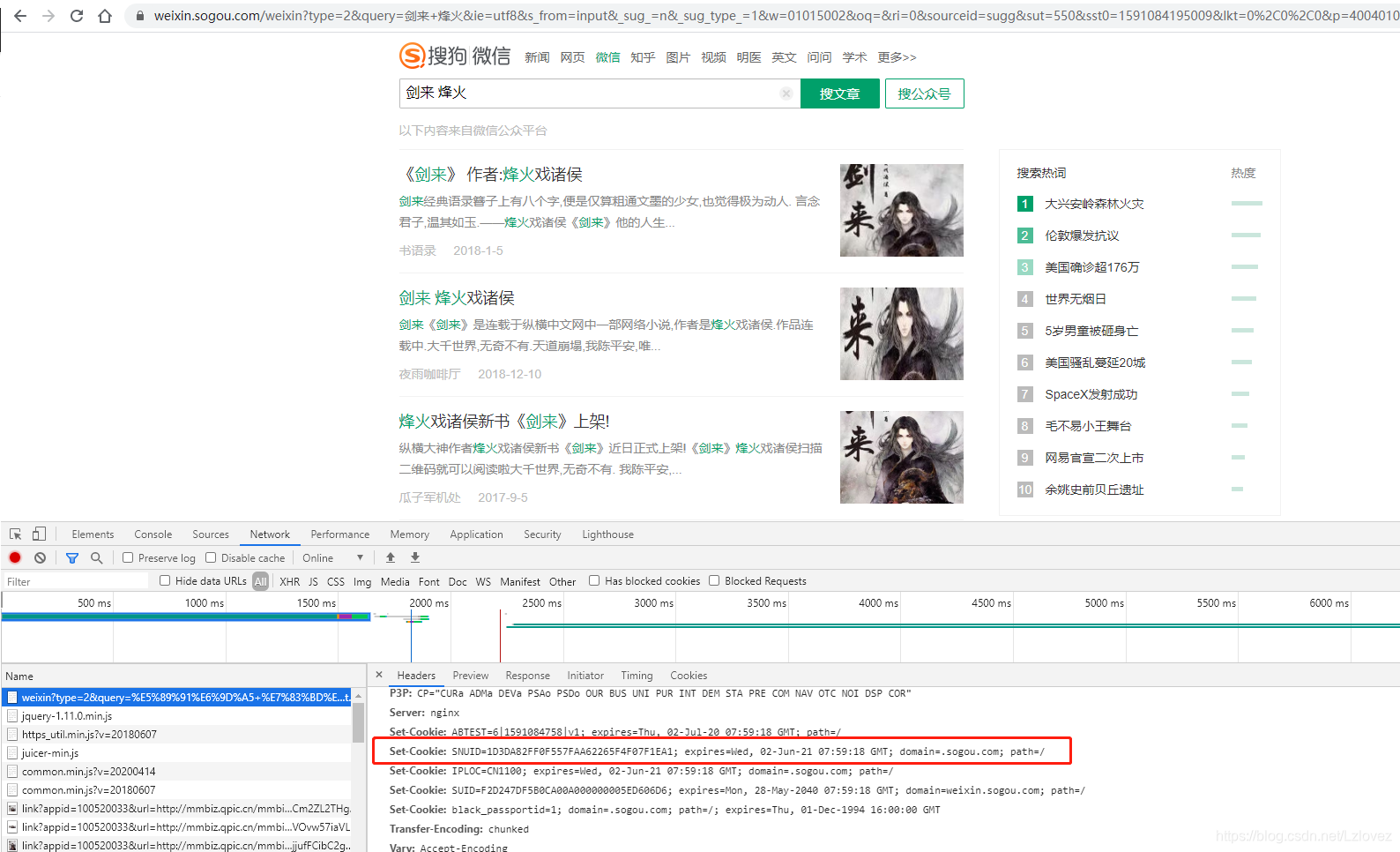
所以我们加上这两个cookie就能获取到具体的微信的链接了
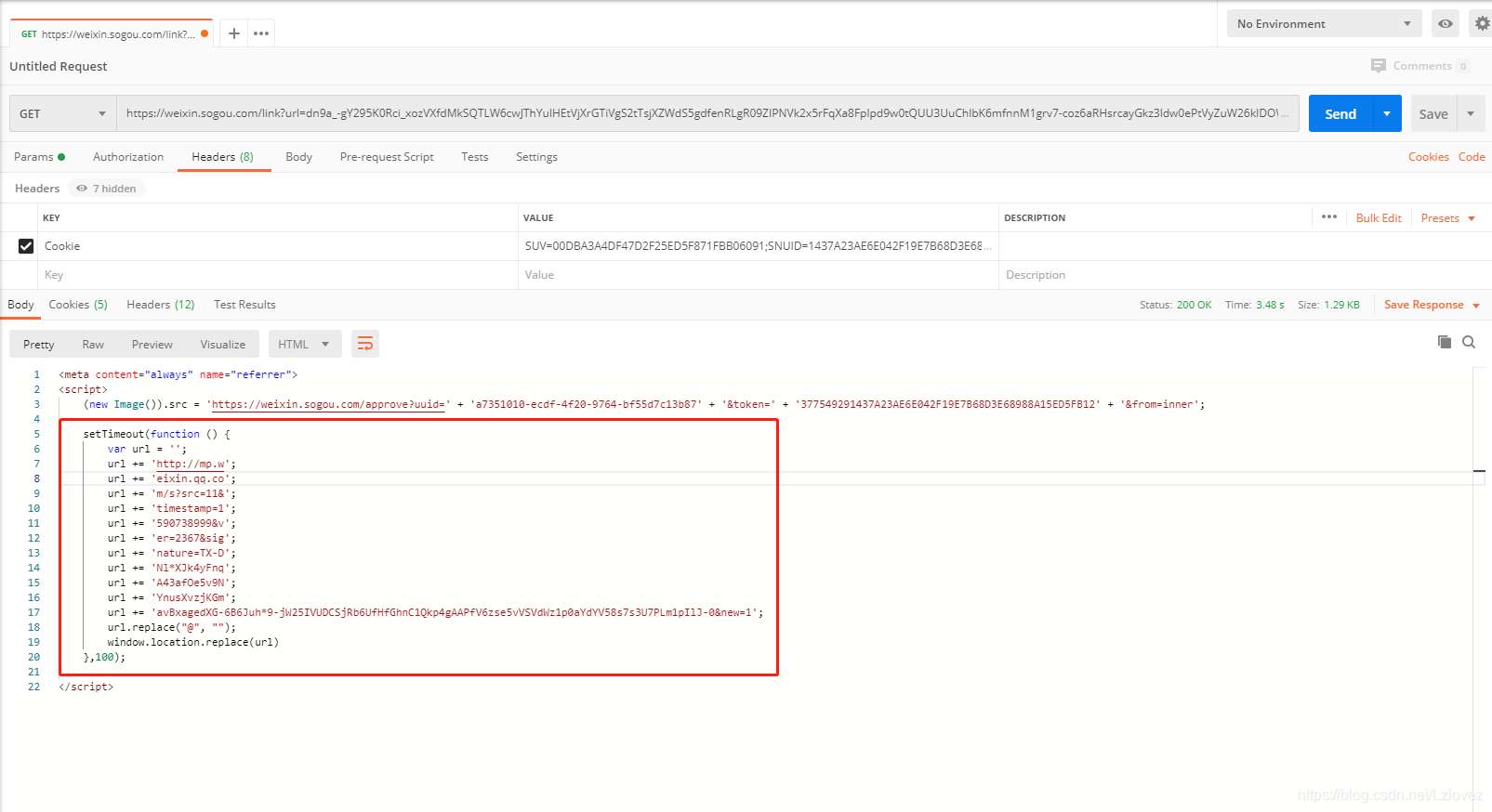
剩下的就是把这个链接取出来就行啦
- 后记
虽然还有很多细节没有完善,但是最坑的是最后的微信链接是有时效性的
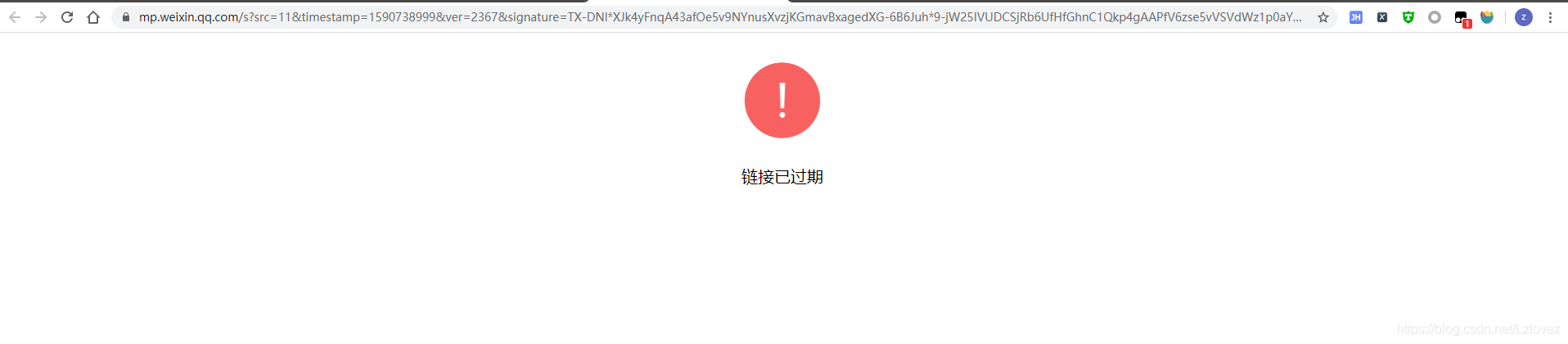
太坑了,市面上有将有时效的链接转换为没有时效的链接的商业服务,不知道是他们是怎么实现的。目前在看微信客户端里面的搜一搜,因为通过客户端的搜一搜搜出来的链接是短短的,应该是失效很长的
2020-06-04 更新
找到了转换永久链接的办法,把有时效性的链接复制到微信客户端里面,不管是过没过期的链接都是能够打开的,再把链接复制出来就是永久的链接了,使用了 python pyautogui 来操作的,很简单,也很low,速度不快,就不放代码了。

















 1878
1878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}