







简单介绍
决策树是一个非常常见并且优秀的机器学习中监督学习的算法,它易于理解、可解释性强,是一种简单且广泛使用的分类器。通过数据来训练该预测模型,从而高效对未打标签的数据进行分类。因此简单来说那,决策树就是可以看做一个if-then规则的集合。我们从决策树的根结点到每一个都叶结点构建一条规则,根据数据不同的输入选择下一个结点,直到达到了最终的叶结点。
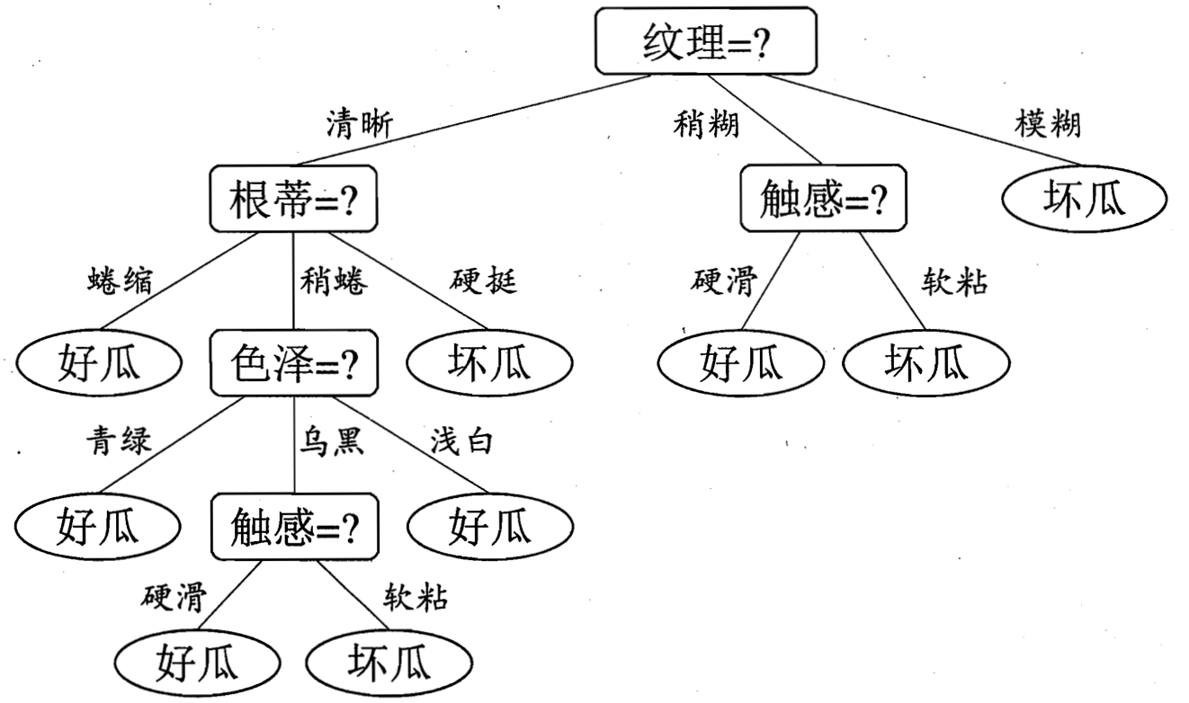
ID3算法核心
知晓了决策树实现的功能之后,假如我们构建决策树,那么应该如何选择属性特征值呢。如上图所示,怎么判断出纹理这个特征就是树的根节点,为何不是触感,而色泽又凭什么要排在根蒂结点之后。这个问题也就是决策树学习的关键。其实就是选择最优划分属性,希望划分后,分支结点的“正确性”越来越高。如何计算该特征的正确性即为区分不同决策树的关键,下面就要引入一个信息的度量概念,信息增益,而ID3决策树在构建树的过程中,就是以信息增益来判断的。
香浓理论中的信息熵是度量样本集合不确定度(纯度)的最常用的指标。而在ID3算法中,我们采取信息增益这个量来作为纯度的度量。我们选取使得信息增益最大的特征进行分裂!信息熵是代表随机变量的复杂度(不确定度),条件熵代表在某一个条件下,随机变量的复杂度(不确定度)。而我们的信息增益恰好是:信息熵-条件熵。
数据的( Ck表示集合 D 中属于第 k 类样本的样本子集 )信息熵公式为:
针对某个特征 A,对于数据集 D 的条件熵为:
信息增益 = 信息熵 - 条件熵:
信息增益就表示为如果我们知道了属性A的信息,则可以使得样本集合不确定度减少的程度。那么我们选择决策树分裂的条件即为当前特征中信息增益最大的特征。
ID3决策树的构建过程
- 初始化特征集合和数据集合;
- 计算数据集合信息熵和所有特征的条件熵,选择信息增益最大的特征作为当前决策节点;
- 更新数据集合和特征集合(删除上一步使用的特征,并按照特征值来划分不同分支的数据集合);
- 重复 2,3 两步,若子集值包含单一特征,则为分支叶子节点。
ID3决策树的构建过程如上所示, 现在我们以周志华老师的《机器学习》一书中的例子来看一个具体的过程。数据集合如下:
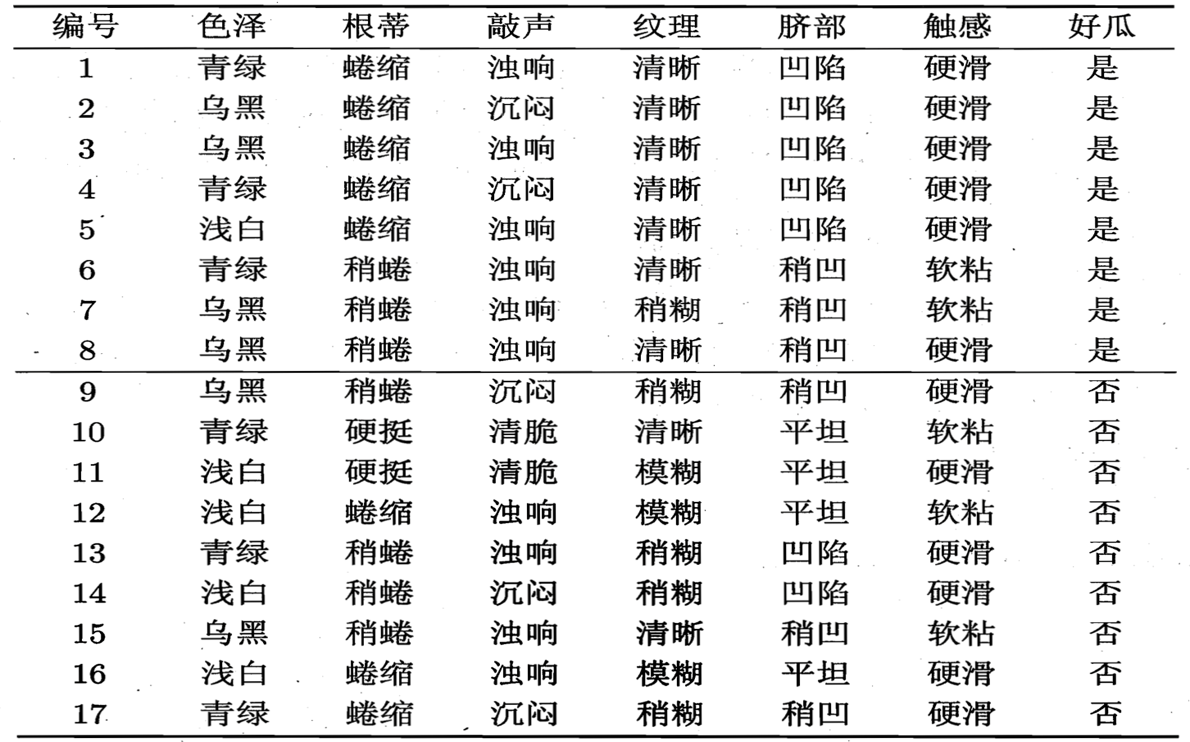
正例(好瓜)占 8/17,反例占 9/17 ,根结点的信息熵为 :
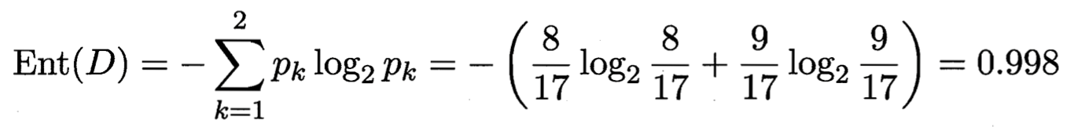
计算当前属性集合{色泽,根蒂,敲声,纹理,脐部,触感}中每个属性的信息增益。
色泽有3个可能的取值:{青绿,乌黑,浅白}
D1(色泽=青绿) = {1, 4, 6, 10, 13, 17},正例 3/6,反例 3/6
D2(色泽=乌黑) = {2, 3, 7, 8, 9, 15},正例 4/6,反例 2/6
D3(色泽=浅白) = {5, 11, 12, 14, 16},正例 1/5,反例 4/5
三个分支结点的信息熵值为:
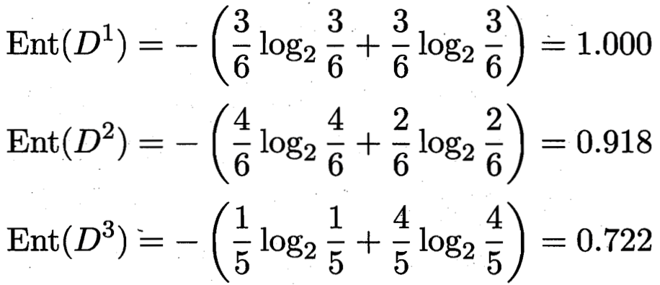
那么我们可以知道属性色泽的信息增益为:
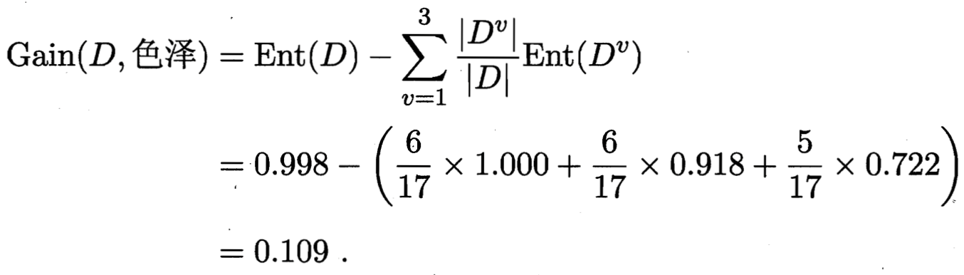
同理其他的特征值的信息增益为:

于是我们找到了信息增益最大的属性纹理,它的Gain(D,纹理) = 0.381最大。
于是我们选择的划分属性为“纹理”。
如下:
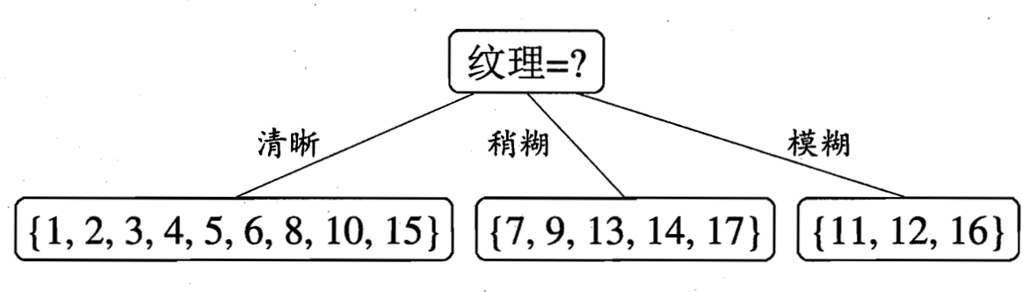
于是,我们可以得到了三个子结点,对于这三个子节点,我们可以递归的使用刚刚找信息增益最大的方法进行选择特征属性,
比如:D1(纹理=清晰) = {1, 2, 3, 4, 5, 6, 8, 10, 15},第一个分支结点可用属性集合{色泽、根蒂、敲声、脐部、触感},基于 D1各属性的信息增益,分别求的如下:

于是我们可以选择特征属性为根蒂,脐部,触感三个特征属性中任选一个(因为他们三个相等并最大),其它俩个子结点同理,然后得到新一层的结点,再递归的由信息增益进行构建树即可。
我们最终的决策树如下:
至此,决策树构建完毕,ID3决策树的构建过程到此位置。
决策树代码实现
import numpy as np
import pandas as pd
import treePlotter
class TreeNode(object):
def __init__(self, ids=None, children=[], entropy=0, depth=0):
self.ids = ids # 此节点中的数据索引
self.entropy = entropy # 熵,稍后填充
self.depth = depth # 到根节点的距离
self.split_attribute = None # 选择哪个属性,它是非叶子的
self.children = children # 其子节点列表
self.order = None # 孩子中 split_attribute 的值顺序
self.label = None # 如果是叶子节点的标签
def set_properties(self, split_attribute, order):
self.split_attribute = split_attribute
self.order = order
def set_label(self, label):
self.label = label
def entropy(freq):
# remove prob 0
freq_0 = freq[np.array(freq).nonzero()[0]]
prob_0 = freq_0 / float(freq_0.sum())
return -np.sum(prob_0 * np.log(prob_0))
class DecisionTreeID3(object):
def __init__(self, max_depth=10, min_samples_split=2, min_gain=1e-4):
self.root = None
self.max_depth = max_depth
self.min_samples_split = min_samples_split
self.Ntrain = 0
self.min_gain = min_gain
def fit(self, data, target):
self.Ntrain = data.count()[0]
self.data = data
self.attributes = list(data)
self.target = target
self.labels = target.unique()
ids = range(self.Ntrain)
self.root = TreeNode(ids=ids, entropy=self._entropy(ids), depth=0)
queue = [self.root]
while queue:
node = queue.pop()
if node.depth < self.max_depth or node.entropy < self.min_gain:
node.children = self._split(node)
if not node.children: # leaf node
self._set_label(node)
queue += node.children
else:
self._set_label(node)
def _entropy(self, ids):
# 计算具有索引 id 的节点的熵
# print('ncaa', len(ids))
if len(ids) == 0:
return 0
ids = [i + 1 for i in ids] # 熊猫系列索引从1开始
# print('ids', ids)
freq = np.array(self.target[ids].value_counts())
# print('ncaa', self.target[ids].value_counts())
return entropy(freq)
def _set_label(self, node):
# find label for a node if it is a leaf
# simply chose by major voting
target_ids = [i + 1 for i in node.ids] # target is a series variable
node.set_label(self.target[target_ids].mode()[0]) # most frequent label
def _split(self, node):
ids = node.ids
best_gain = 0
best_splits = []
best_attribute = None
order = None
sub_data = self.data.iloc[ids, :]
for i, att in enumerate(self.attributes):
values = self.data.iloc[ids, i].unique().tolist()
if len(values) == 1:
continue # entropy = 0
splits = []
for val in values:
sub_ids = sub_data.index[sub_data[att] == val].tolist()
splits.append([sub_id - 1 for sub_id in sub_ids])
# don't split if a node has too small number of points
if min(map(len, splits)) < self.min_samples_split:
continue
# information gain
HxS = 0
for split in splits:
HxS += len(split) * self._entropy(split) / len(ids)
gain = node.entropy - HxS
print(att, ' ⑧⑧⑧⑧⑧⑧⑧⑧ ' , gain,sep=' ')
if gain < self.min_gain:
continue # stop if small gain
if gain > best_gain:
best_gain = gain
best_splits = splits
best_attribute = att
order = values
if best_attribute != None:
print('信息增益最大的属性为', best_attribute)
node.set_properties(best_attribute, order)
child_nodes = [TreeNode(ids=split,
entropy=self._entropy(split), depth=node.depth + 1) for split in best_splits]
return child_nodes
def predict(self, new_data):
"""
param new_data: 一个新的数据框,每一行都是一个数据点
return: 每行的预测标签
"""
npoints = new_data.count()[0]
labels = [None] * npoints
for n in range(npoints):
x = new_data.iloc[n, :] # one point
# 如果没有遇到叶子,则从根开始并递归旅行
node = self.root
while node.children:
node = node.children[node.order.index(x[node.split_attribute])]
labels[n] = node.label
return labels
def show_tree(tnode: TreeNode):
global decs_tree
flag = True
if not tnode.children:
return
if tnode.split_attribute != None:
decs_tree += "'{}':{{".format(tnode.split_attribute)
print(tnode.split_attribute, ':{', sep='', end='')
ans = tnode.order
for i in range(len(ans)):
temp = tnode.children[ans.index(ans[i])]
decs_tree += "'{}':".format(ans[i])
print(ans[i], ':', sep=' ', end='')
if temp.label != None:
decs_tree += "'" + temp.label + "'"
print(temp.label,end='')
else:
flag = not flag
decs_tree += '{'
print('{',end='')
show_tree(temp)
if not flag:
decs_tree += '}'
print('}',end='')
flag = True
if i != len(ans) - 1:
decs_tree += ','
print(',',end='')
decs_tree += '}'
print('}',end='')
# if tnode.label != None:
if __name__ == "__main__":
global decs_tree
decs_tree = ''
df = pd.read_csv('weather.csv', index_col=0, parse_dates=True)
print(df)
X = df.iloc[:, :-1]
y = df.iloc[:, -1]
tree = DecisionTreeID3(max_depth=3, min_samples_split=2)
tree.fit(X, y)
print(tree.predict(X))
node = tree.root
show_tree(node)
print()
decs_tree = '{' + decs_tree + '}'
print(eval(decs_tree))
treePlotter.ID3_Tree(eval(decs_tree))
可视化呈现决策树
至此机器已经可以理解我们所写的决策树,但是人仍不便于理解,为了从数据集合中将决策树抽象成人能理解的树图,我们输出训练的决策树的结构,且将其进行可视化。(相关代码存放于Github中,虽然我也是借鉴别人的,>灬<,HJNODM)
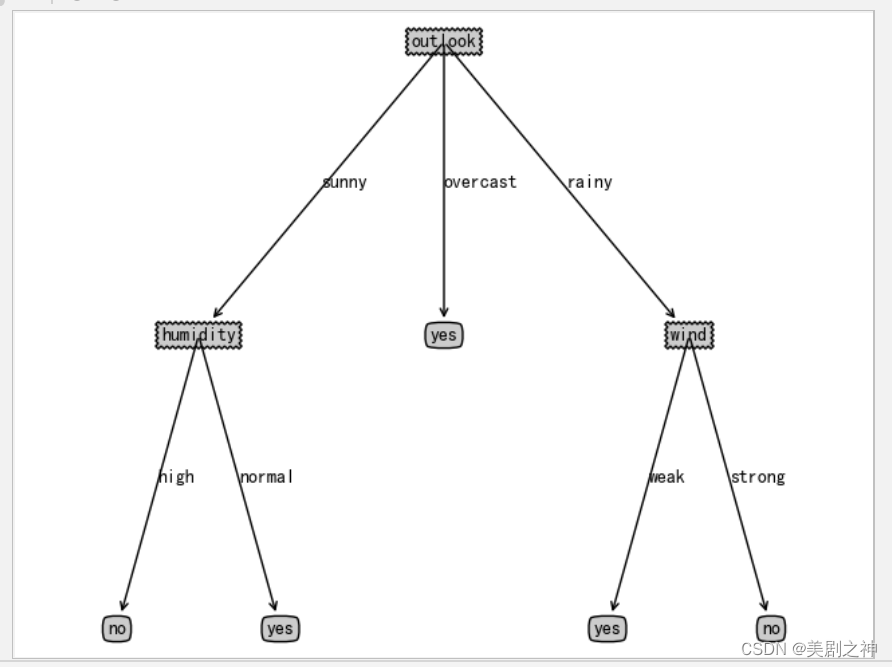
参考书籍 周志华老师的西瓜书
参考博客 ID3算法思想
参考博客 决策树过程理解
[原文连接已失效]















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









