ID3算法是一种决策树学习算法,用于分类和预测。下面是实现ID3算法的步骤:
1. 计算每个特征的信息增益,选择信息增益最大的特征作为根节点。
2. 将数据集按照根节点特征值分成不同的子集。
3. 对每个子集递归执行步骤1和2,直到所有的叶子节点都是同一类别。
下面是一个Python实现ID3算法的示例代码:
```python
import math
def entropy(class_probabilities):
"""计算熵"""
return sum(-p * math.log(p, 2) for p in class_probabilities if p)
def class_probabilities(labels):
"""计算各个类的概率"""
total_count = len(labels)
return [count / total_count for count in collections.Counter(labels).values()]
def data_entropy(labeled_data):
"""计算数据集的熵"""
labels = [label for _, label in labeled_data]
probabilities = class_probabilities(labels)
return entropy(probabilities)
def partition_entropy(subsets):
"""计算数据集的加权平均熵"""
total_count = sum(len(subset) for subset in subsets)
return sum(data_entropy(subset) * len(subset) / total_count for subset in subsets)
def partition_by(inputs, attribute):
"""按照某个特征进行分组"""
groups = collections.defaultdict(list)
for input in inputs:
key = input[0][attribute]
groups[key].append(input)
return groups
def partition_entropy_by(inputs, attribute):
"""计算按照某个特征分组后的数据集的加权平均熵"""
partitions = partition_by(inputs, attribute)
return partition_entropy(partitions.values())
def build_tree_id3(inputs, split_attributes):
"""构建ID3决策树"""
class_labels = [label for _, label in inputs]
if len(set(class_labels)) == 1:
# 所有样本属于同一类别,返回叶子节点
return class_labels[0]
if not split_attributes:
# 没有可用特征,返回该节点样本数最多的类别
return max(set(class_labels), key=class_labels.count)
# 选择最优特征
def score(attribute):
return partition_entropy_by(inputs, attribute)
best_attribute = min(split_attributes, key=score)
# 构建子树
partitions = partition_by(inputs, best_attribute)
new_attributes = [a for a in split_attributes if a != best_attribute]
subtrees = {attribute_value: build_tree_id3(subset, new_attributes) for attribute_value, subset in partitions.items()}
subtrees[None] = max(set(class_labels), key=class_labels.count)
return (best_attribute, subtrees)
def classify(tree, input):
"""对输入进行分类"""
if tree in (True, False):
return tree
attribute, subtree_dict = tree
subtree_key = input.get(attribute)
if subtree_key not in subtree_dict:
subtree_key = None
subtree = subtree_dict[subtree_key]
return classify(subtree, input)
# 示例
inputs = [
({'level': 'Senior', 'lang': 'Java', 'tweets': 'no', 'phd': 'no'}, False),
({'level': 'Senior', 'lang': 'Java', 'tweets': 'no', 'phd': 'yes'}, False),
({'level': 'Mid', 'lang': 'Python', 'tweets': 'no', 'phd': 'no'}, True),
({'level': 'Junior', 'lang': 'Python', 'tweets': 'no', 'phd': 'no'}, True),
({'level': 'Junior', 'lang': 'R', 'tweets': 'yes', 'phd': 'no'}, True),
({'level': 'Junior', 'lang': 'R', 'tweets': 'yes', 'phd': 'yes'}, False),
({'level': 'Mid', 'lang': 'R', 'tweets': 'yes', 'phd': 'yes'}, True),
({'level': 'Senior', 'lang': 'Python', 'tweets': 'no', 'phd': 'no'}, False),
({'level': 'Senior', 'lang': 'R', 'tweets': 'yes', 'phd': 'no'}, True),
({'level': 'Junior', 'lang': 'Python', 'tweets': 'yes', 'phd': 'no'}, True),
({'level': 'Senior', 'lang': 'Python', 'tweets': 'yes', 'phd': 'yes'}, True),
({'level': 'Mid', 'lang': 'Python', 'tweets': 'no', 'phd': 'yes'}, True),
({'level': 'Mid', 'lang': 'Java', 'tweets': 'yes', 'phd': 'no'}, True),
({'level': 'Junior', 'lang': 'Python', 'tweets': 'no', 'phd': 'yes'}, False)
]
split_attributes = ['level', 'lang', 'tweets', 'phd']
tree = build_tree_id3(inputs, split_attributes)
print(classify(tree, {'level': 'Junior', 'lang': 'Java', 'tweets': 'yes', 'phd': 'no'})) # True
```
随机森林算法是一种基于决策树的集成学习算法,它通过随机选择特征和数据样本来构建多个决策树,并将它们的预测结果进行投票或平均,最终得到最终的预测结果。下面是实现随机森林算法的步骤:
1. 对于每棵决策树,从训练数据集中随机选择一个子集。
2. 对于每棵决策树,从特征集合中随机选择一个子集。
3. 对于每棵决策树,使用ID3算法构建决策树。
4. 对于测试数据,对每个样本进行预测,将所有决策树的预测结果进行投票或平均,得到最终的预测结果。
下面是一个Python实现随机森林算法的示例代码:
```python
import random
def build_tree_random_forest(inputs, split_attributes):
"""构建随机森林"""
class_labels = [label for _, label in inputs]
if len(set(class_labels)) == 1:
# 所有样本属于同一类别,返回叶子节点
return class_labels[0]
if not split_attributes:
# 没有可用特征,返回该节点样本数最多的类别
return max(set(class_labels), key=class_labels.count)
# 随机选择特征和数据集
selected_inputs = [random.choice(inputs) for _ in inputs]
selected_attributes = random.sample(split_attributes, int(math.sqrt(len(split_attributes))))
# 选择最优特征
def score(attribute):
return partition_entropy_by(selected_inputs, attribute)
best_attribute = min(selected_attributes, key=score)
# 构建子树
partitions = partition_by(selected_inputs, best_attribute)
new_attributes = [a for a in split_attributes if a != best_attribute]
subtrees = {attribute_value: build_tree_random_forest(subset, new_attributes) for attribute_value, subset in partitions.items()}
subtrees[None] = max(set(class_labels), key=class_labels.count)
return (best_attribute, subtrees)
def classify_random_forest(trees, input):
"""对输入进行分类"""
votes = [classify(tree, input) for tree in trees]
return max(set(votes), key=votes.count)
# 示例
inputs = [
({'level': 'Senior', 'lang': 'Java', 'tweets': 'no', 'phd': 'no'}, False),
({'level': 'Senior', 'lang': 'Java', 'tweets': 'no', 'phd': 'yes'}, False),
({'level': 'Mid', 'lang': 'Python', 'tweets': 'no', 'phd': 'no'}, True),
({'level': 'Junior', 'lang': 'Python', 'tweets': 'no', 'phd': 'no'}, True),
({'level': 'Junior', 'lang': 'R', 'tweets': 'yes', 'phd': 'no'}, True),
({'level': 'Junior', 'lang': 'R', 'tweets': 'yes', 'phd': 'yes'}, False),
({'level': 'Mid', 'lang': 'R', 'tweets': 'yes', 'phd': 'yes'}, True),
({'level': 'Senior', 'lang': 'Python', 'tweets': 'no', 'phd': 'no'}, False),
({'level': 'Senior', 'lang': 'R', 'tweets': 'yes', 'phd': 'no'}, True),
({'level': 'Junior', 'lang': 'Python', 'tweets': 'yes', 'phd': 'no'}, True),
({'level': 'Senior', 'lang': 'Python', 'tweets': 'yes', 'phd': 'yes'}, True),
({'level': 'Mid', 'lang': 'Python', 'tweets': 'no', 'phd': 'yes'}, True),
({'level': 'Mid', 'lang': 'Java', 'tweets': 'yes', 'phd': 'no'}, True),
({'level': 'Junior', 'lang': 'Python', 'tweets': 'no', 'phd': 'yes'}, False)
]
split_attributes = ['level', 'lang', 'tweets', 'phd']
trees = [build_tree_random_forest(inputs, split_attributes) for _ in range(10)]
print(classify_random_forest(trees, {'level': 'Junior', 'lang': 'Java', 'tweets': 'yes', 'phd': 'no'})) # True
```
注意,在实际应用中,为了防止过拟合,需要对随机森林进行一些优化,例如设置每棵决策树的最大深度、设置叶子节点的最小样本数等。此外,还可以使用交叉验证来选择最优的超参数。
























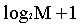 个属性作为随机森林每棵决策树的属性列表,如图:
个属性作为随机森林每棵决策树的属性列表,如图:


















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











