






学习内容:
1 机器学习
1.1 机器学习定义
①Arthur Samuel:在没有明确设置的情况下,使计算机具有学习能力的研究领域。
e.g.跳棋游戏,使计算机与自己对弈上万次,使计算机学习到什么是好布局并获得丰富的下棋经验。
②Tom Mitchell:计算机程序从经验E中学习解决某一任务T,进行某一性能度量P,通过P测定在T上的表现因经验E而提高。
e.g.跳棋游戏:经验E是程序与自己下几万次跳、任务T是玩跳棋、性能度量P是与新对手玩跳棋时赢的概率。
1.2 监督学习
教计算机如何去完成任务。它的训练数据是有标签的,训练目标是能够给新数据(测试数据)以正确的标签。
1.2.1 回归类问题
给定的数据集是真实的一系列连续的值。计算机通过学习选择适当的模型来模拟这个数据值(比如一次函数或二次函数等)。
1.2.2 分类问题
计算机通过学习,根据输入的特征值,得出的结果是一个离散值,比如肿瘤问题,根据年龄、肿瘤大小,得出肿瘤是良性0或恶性1。
1.3 无监督学习
只给算法一个数据集,但是不给数据集的正确答案,由算法自行分类。
1.3.1 聚类算法
- 谷歌新闻每天搜集几十万条新闻,并把相似的新闻进行分类
- 市场对用户进行分类
- 鸡尾酒算法
2 线性回归
- 假设函数(用来进行预测的函数)
2.1 代价函数
(平方误差代价函数):解决回归问题最常用的手段。
(其中m表示训练样本的数量)
优化目标:
2.1.1 只含一个参数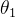
不断改变的值,通过代价函数
得到多组结果,并找到最小的的代价结果,即最优目标

2.1.2 同时考虑两个参数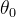 、
、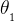
此时,将代价函数变成三维图像以及平片图(等高线图),其中等高线最小椭圆中心点代表代价函数的最小值,即。


2.2 梯度下降算法
- 目标:最小化代价函数
- 思路:
①初始化参数 和
的值(通常为0)
②不断地一点点改变两个参数 和
的值,使代价函数的值
变小,直到找到
的最小值或局部最小值。
- 梯度: 函数中某一点(x, y)的梯度代表函数在该点变化最快的方向(当所选的开始点有偏差的时候,可能到达另一个局部最小值)。


- 梯度下降算法的公式
其中被称为学习率,控制梯度下降的步子大小,
越大,梯度下降越快。

同时, 和
的值需要同时更新,若先更新了
的值,会影响temp1的值,使其与同时更新的值不同。
的选取:如果
如果

- 更新
的原理
在梯度下降法中,当接近局部最低点时,梯度下降法会自动采取更小的幅度(因为局部最低时导数等于零),所以越靠近最低点,导数值越小,所以实际上没有必要另外减小α.

2.3 线性回归(Batch)的梯度下降
- 公式推导过程
- 当
时,对
- 当
时,对
- 更新
- 线性回归的梯度下降函数是凸函数,凸函数没有局部最优解,只有一个全局最优(总是收敛到全局最优)。

3 矩阵
3.1 矩阵加法、标量乘法运算
- 两个矩阵相加,将这两个矩阵的每一个元素都逐个相加(只有相同维度的两个矩阵才能相加,结果还是与相加的两个矩阵维度相同的矩阵)。

-
矩阵中每个元素逐个乘以标量。

3.2 矩阵向量乘法
- 一个矩阵和一个向量乘得到一个新的列向量。
- 列向量的维数就是矩阵的行数。
- 矩阵的列数必须等于向量的维数。

3.3 矩阵乘法及特征
- 矩阵A×B,只要求A的列数要等于B的行数,而不一定要求A的行数等于B的列数;得到的结果矩阵C的行数和A的行数相等、C的列数和B的列数相等。
- A矩阵每一行分别于B矩阵的每一列逐个相乘求和。

- 特征:①矩阵乘法不符合交换律;②矩阵乘法符合结合律。
- 单位矩阵(I):①维度n*n;②主对角线上为1,其余为0;③矩阵
3.3 逆和转置
- 逆矩阵:①
的逆矩阵为
;②
;③不存在逆矩阵的矩阵为奇异矩阵(退化矩阵);
- 转置矩阵:①
;②
的维度与

4 多元线性回归
4.1 假设函数(含有多个特征)
4.1.1 多变量样本数据及假设函数公式

其中, 表示特征数量;
表示第i组样本的特征值组合;
表示第i组样本特征值中第j个特征值数据。
- 公式:
(定义
=1,即
=1)
4.2 多元梯度下降法
- 代价函数
- 梯度下降算法:
- 先求偏导:
- 然后更新:
4.3 梯度下降法Ⅰ——特征缩放
- 使不同特征的取值在相近的范围内,梯度下降法可以更快收敛。所以如果特征值范围相差较大,特征缩放就是一种有效的方法。

- 执行特征缩放的目的:将特征的取值约束到-1到+1的范围内。(-1、+1不绝对,仅表示适中的范围,不过大,不过小)
- 均值归一化:使特征值减去平均值再除以取值范围
(
为此特征的平均值,
为此特征范围max-min)
e.g. 房子的面积(取值0~2000,假设平均面积为1000)
- 只要特征值转换为相近似的范围即可,特征范围无需很精确,仅为了让梯度下降更快,迭代次数更少。
4.4 梯度下降法Ⅱ——学习率
- 在梯度下降算法正常工作的情况下,每一步迭代之后代价函数值
都应该下降,

- 此图像可帮助判断梯度下降算法是否已经收敛,当迭代次数达到一定值,代价函数值趋于不变,此时近乎收敛。
- 图像还可帮助确定梯度下降算法是否正常运行。当学习率

- 只要学习率
- 选取合适的
4.5 特征和多项式回归
4.5.1 特征
- 有时可以不用一开始使用的特征,定义新的特征可能会产生新的更好的模型,这取决于审视特定问题的角度。例如房价预测:可设两个特征,房子土地宽度
,和土地长度
,那么假设函数可写为
;还可直接设一个特征,即为房子所占土地面子x,因为面积为长乘宽,此时假设函数可写为
.
4.5.2 多项式回归
比如有一个住房价格数据集,可能存在多个不同的模型用于拟合。
- 选择二次函数与数据拟合

但随着面积继续增大,住房价格开始下降,二次模型不合理。
- 选择三次函数与数据拟合

但使用三次函数,需要进行特征缩放,因为三个特征值范围相差较大。

- 选择平方根函数与数据拟合

4.6 正规方程(区别于迭代方法的直接解法)
对于某些线性回归问题,是一种更好求参数最优值的方法。
- 求最优值过程:对代价函数
的最优值。
求偏导,再求

根据例子可知
需要加入一列,令其都等于1
对求偏导并令其等于0得
可求得
- 梯度下降的优点: 在特征变量很多的情况下,也能运行的相当好。
梯度下降得缺点:①需要选择合适的学习率(需要运行多次尝试不同的学习率);②需要更多次迭代过程,计算可能会更慢。
- 正规方程优点即不需要选择学习率,也不需要迭代。只需要运行一次。
正规方程的缺点:需要计算,若矩阵维度n较大,计算会很慢。
4.7 正规方程在矩阵不可逆的情况下的解决办法
矩阵不可逆的情况很小,导致不可逆可能有以下两个原因:①两个及两个以上的特征量呈线性关系,如,此时可以删去其中一个。②特征量过多。当样本量较小时,无法计算出那么多个偏导,所以也求不出最优结果,这种情况可以在无影响的情况下,可以删掉一些,或进行正则化。
学习时间:
- 周一至周五晚上 7 点—晚上10点
学习产出:
- 初步了解了机器学习
- 通过吴恩达机器课程对单变量线性回归、矩阵、多变量线性回归理论进行学习
- 整理了以上四部分笔记















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









