










参考 blog.csdn.net/xqj198404/article/details/28601149
一、Mahout0.9安装
1、首先 从mirror.cc.columbia.edu/pub/software/apache/mahout/0.9/ 下载到 .tar.gz 的mahout源码;
2、解压到某个地方 在 mahout/bin 路径下修改 mahou 文件,添加如下内容:
HADOOP_CONF_DIR="hadoop的配置目录需要以/结尾"
HADOOP_HOME="hadoop的安装目录需要以/结尾"
MAHOUT_HEAPSIZE=2000 mahout可以调用的内存量,建议设的比较大
3、修改 hadoop etc路径下的 mapred-site.xml 添加如下内容:
<pre name="code" class="plain"><property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property> 修改 hadoop etc路径下的 hadoop-env.sh 添加如下内容:
export HADOOP_HEAPSIZE=2000 二、Mahout0,9验证
1、从 http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data 下载测试数据
2、将下载的到的测试数据文本存储到 hdfs 上:
./hadoop fs -put synthetic_control.data /user/root/testdata3、到 mahout 的bin路径下执行如下:
bin/mahout org.apache.mahout.clustering.syntheticcontrol.canopy.Job
bin/mahout org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
bin/mahout org.apache.mahout.clustering.syntheticcontrol.fuzzykmeans.Job
表示我只执行了第一个JOB,看上去是满成功的,花费了 1.7 min,给出了6个 cluster
4、检查 hdfs 里面 mahout 的输出情况却看到一堆头大的乱码如下:
<img src="https://img-blog.csdn.net/20140929212756325" alt="" />
看 <a target=_blank href="tech.ddvip.com/2013-11/1384964006206279.html">tech.ddvip.com/2013-11/1384964006206279.html</a> 这里说是需要反序列化:
<pre name="code" class="plain">mahout seqdumper -i xxx/xxx/xxx/part-r-00000 -o /data/patterns.txt这是找不到output输出路径,改成了 hdfs:// 也找不到思密达...
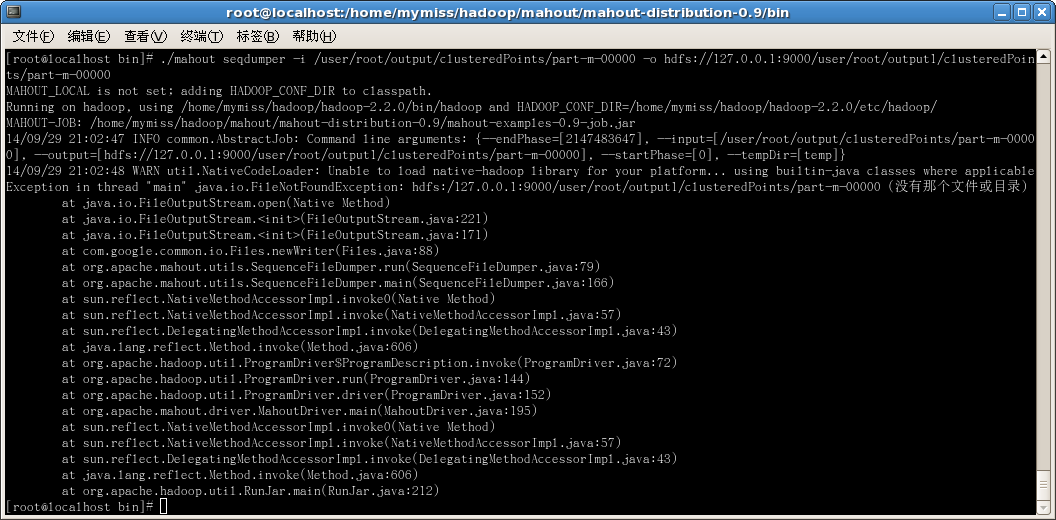
以下是成功反序列化的结果:
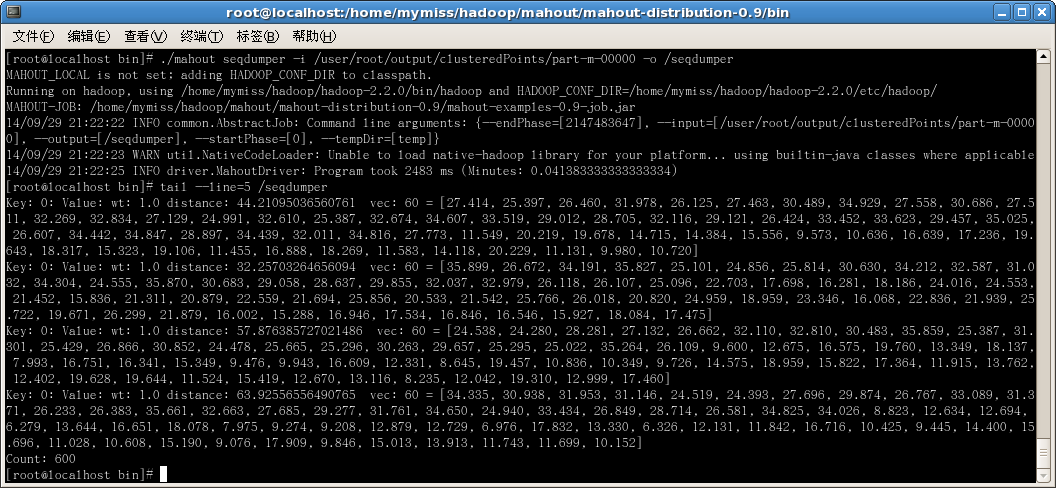















 2396
2396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









