







笔记目录:
【Spark实战】慕课网日志分析(一):数据初步清洗
【Spark实战】慕课网日志分析(二):数据二次清洗之日志解析
【Spark实战】慕课网日志分析(三):清理后数据的存储、统计和入库
【Spark实战】慕课网日志分析(四):将数据清洗的作业提交到YARN上运行
【Spark实战】慕课网日志分析(五):将数据统计和入库的作业提交到YARN上运行
存储清洗后的数据
调优点:
- coalesce(1)保证只有一个输出文件
- mode(SaveMode.Overwrite)保证能够覆盖原有文件
package com.imooc.log
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* 使用Spark完成我们的数据清洗操作
*/
object SparkStatCleanJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SparkStatCleanJob")
.config("spark.sql.parquet.compression.codec","gzip")
.master("local[2]").getOrCreate()
// val accessRDD = spark.sparkContext.textFile("/Users/rocky/data/imooc/access.log")
val accessRDD = spark.sparkContext.textFile("./access.log")
accessRDD.take(10).foreach(println)
//RDD ==> DF的转换
val accessDF = spark.createDataFrame(accessRDD.map(x => AccessConvertUtil.parseLog(x)),
AccessConvertUtil.struct) //1
// accessDF.printSchema()
// accessDF.show(false)
accessDF.coalesce(1).write.format("parquet").mode(SaveMode.Overwrite)
.partitionBy("day").save("./clean2")
spark.stop
}
}

需求一:TopN数据统计:最受欢迎的TopN课程
调优点:分区字段的数据类型调整
config("spark.sql.sources.partitionColumnTypeInference.enabled","false")
新建TopNStatJob.scala:
package com.imooc.log
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.collection.mutable.ListBuffer
/**
* TopN统计Spark作业
*/
object TopNStatJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("TopNStatJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled","false") //分区字段的数据类型调整
.master("local[2]").getOrCreate()
val accessDF = spark.read.format("parquet").load("./clean2")
accessDF.printSchema()
accessDF.show(false)
val day = "20170511"
// StatDAO.deleteData(day)
//
// //最受欢迎的TopN课程
videoAccessTopNStat(spark, accessDF, day)
//
// //按照地市进行统计TopN课程
// cityAccessTopNStat(spark, accessDF, day)
//
// //按照流量进行统计
// videoTrafficsTopNStat(spark, accessDF, day)
spark.stop()
}
/**
* 最受欢迎的TopN课程
*/
def videoAccessTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
/**
* 使用DataFrame的方式进行统计
*/
import spark.implicits._
val videoAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")//过滤出某一天的video类别的数据
.groupBy("day","cmsId").agg(count("cmsId").as("times")) //1.要导入org.apache.spark.sql.functions._ 2.groupBy分组之后,要用agg聚合
.orderBy($"times".desc) //降序排列
videoAccessTopNDF.show(false)
}
}
运行结果:
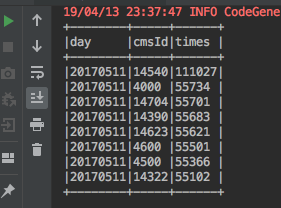
统计结果入库
1.安装MySQL并建库
为了跟教程同步,于是在mac上面下载并安装了5.1.38版本的MySQL。
下载链接:https://cdn.mysql.com/archives/mysql-5.1/mysql-5.1.38-osx10.5-x86_64.tar.gz
安装步骤请参考:
1.https://blog.csdn.net/u013160024/article/details/43401191
2.http://download.nust.na/pub6/mysql/doc/refman/5.1/en/installing-binary.html
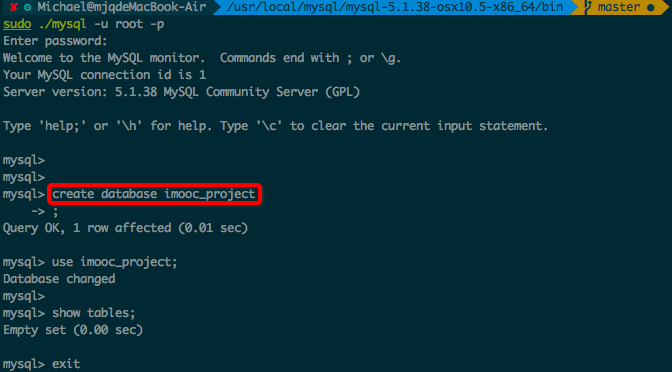
安装好了之后,在命令行使用sudo ./mysql -u root -p进入MySQL
然后,在命令行建库,建库代码:create database imooc_project。
然后执行use imooc_project。
MySQLUtils.scala:
package com.imooc.log
import java.sql.{Connection, PreparedStatement, DriverManager}
/**
* MySQL操作工具类
*/
object MySQLUtils {
/**
* 获取数据库连接
*/
def getConnection() = {
DriverManager.getConnection("jdbc:mysql://localhost:3306/imooc_project?user=root&password=")
}
/**
* 释放数据库连接等资源
* @param connection
* @param pstmt
*/
def release(connection: Connection, pstmt: PreparedStatement): Unit = {
try {
if (pstmt != null) {
pstmt.close()
}
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (connection != null) {
connection.close()
}
}
}
def main(args: Array[String]) {
println(getConnection())
}
}
运行效果:
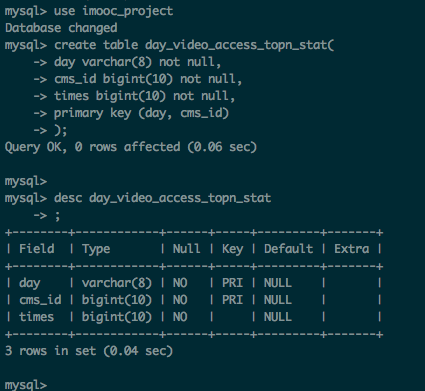
2.在MySQL中建表
建表代码
create table day_video_access_topn_stat(
day varchar(8) not null,
cms_id bigint(10) not null,
times bigint(10) not null,
primary key (day, cms_id)
);
3.创建实体类 DayCityVideoAccessStat.scala
package com.imooc.log
/**
* 每天课程访问次数实体类
*/
case class DayVideoAccessStat(day: String, cmsId: Long, times: Long)
4.批量保存DayVideoAccessStat到数据库
调优点:执行批处理,将数据批量插入数据库,提交使用batch操作。
注意:要将默认的自动提交,设置为手动提交。
package com.imooc.log
import java.sql.{PreparedStatement, Connection}
import scala.collection.mutable.ListBuffer
/**
* 各个维度统计的DAO操作
*/
object StatDAO {
/**
* 批量保存DayVideoAccessStat到数据库
*/
def insertDayVideoAccessTopN(list: ListBuffer[DayVideoAccessStat]): Unit = {
var connection: Connection = null
var pstmt: PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //设置手动提交
val sql = "insert into day_video_access_topn_stat(day,cms_id,times) values (?,?,?) "
pstmt = connection.prepareStatement(sql)
for (ele <- list) {
pstmt.setString(1, ele.day)
pstmt.setLong(2, ele.cmsId)
pstmt.setLong(3, ele.times)
pstmt.addBatch()
}
pstmt.executeBatch() // 执行批量处理
connection.commit() //手工提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
// MySQLUtils.release(connection, pstmt)
}
}
}
5.将统计结果写入到MySQL中
回到TopNStatJob.scala,增加以下代码:
/**
* 将统计结果写入到MySQL中
*/
try {
videoAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val times = info.getAs[Long]("times")
/**
* 不建议大家在此处进行数据库的数据插入
*/
list.append(DayVideoAccessStat(day, cmsId, times))
})
StatDAO.insertDayVideoAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
6.执行代码
右键执行TopNStatJob.scala
控制台输出:
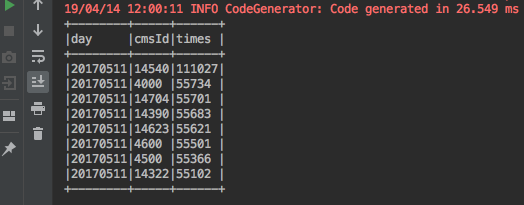
数据库中新增数据:
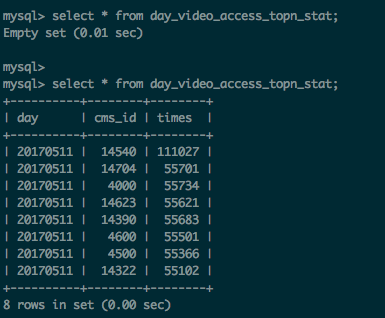
至此,我们已在本地已完成需求一:统计最受欢迎的课程视频。
需求二::按照地市进行最受欢迎课程的统计
1.控制台打印统计数据
/**
* 按照地市进行统计TopN课程
*/
def cityAccessTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
import spark.implicits._
val cityAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")
.groupBy("day", "city", "cmsId")
.agg(count("cmsId").as("times"))
cityAccessTopNDF.show(false)
}
打印结果:
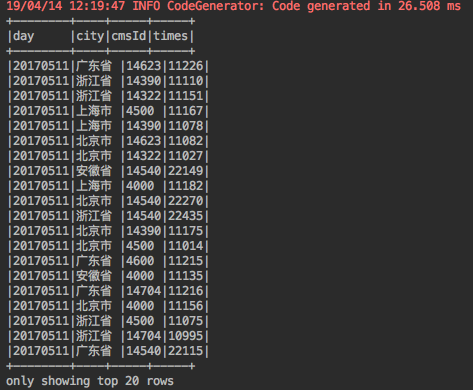
2.在SparkSQL中使用window函数进行排序
def cityAccessTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
import spark.implicits._
val cityAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")
.groupBy("day", "city", "cmsId")
.agg(count("cmsId").as("times"))
cityAccessTopNDF.show(false)
//Window函数在Spark SQL的使用
val top3DF = cityAccessTopNDF.select(
cityAccessTopNDF("day"),
cityAccessTopNDF("city"),
cityAccessTopNDF("cmsId"),
cityAccessTopNDF("times"),
row_number().over(Window.partitionBy(cityAccessTopNDF("city"))
.orderBy(cityAccessTopNDF("times").desc)
).as("times_rank")
).filter("times_rank <=3").show(false) //Top3
}
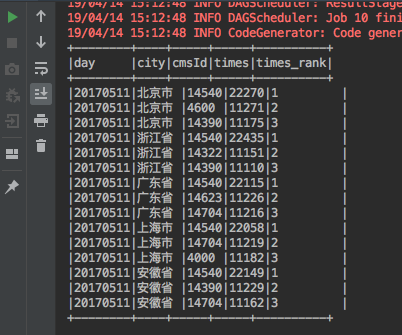
3.在MySQL中建表
建表代码:
create table day_video_city_access_topn_stat(
day varchar(8) not null,
cms_id bigint(10) not null,
city varchar(20) not null,
times bigint(10) not null,
times_rank int not null,
primary key (day, cms_id,city)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
建表结果:
4.将统计结果写入到MySQL中
def cityAccessTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
import spark.implicits._
val cityAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")
.groupBy("day","city","cmsId")
.agg(count("cmsId").as("times"))
cityAccessTopNDF.show(false)
//Window函数在Spark SQL的使用
val top3DF = cityAccessTopNDF.select(
cityAccessTopNDF("day"),
cityAccessTopNDF("city"),
cityAccessTopNDF("cmsId"),
cityAccessTopNDF("times"),
row_number().over(Window.partitionBy(cityAccessTopNDF("city"))
.orderBy(cityAccessTopNDF("times").desc)
).as("times_rank")
).filter("times_rank <=3")//.show(false) //Top3
/**
* 将统计结果写入到MySQL中
*/
try {
top3DF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayCityVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val city = info.getAs[String]("city")
val times = info.getAs[Long]("times")
val timesRank = info.getAs[Int]("times_rank")
list.append(DayCityVideoAccessStat(day, cmsId, city, times, timesRank))
})
StatDAO.insertDayCityVideoAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
这里遇到一个坑:地址插入到MySQL中乱码,解决方法在此:错误解决:使用SparkSQL进行MySQL插入操作出现的中文乱码问题。
执行结果:
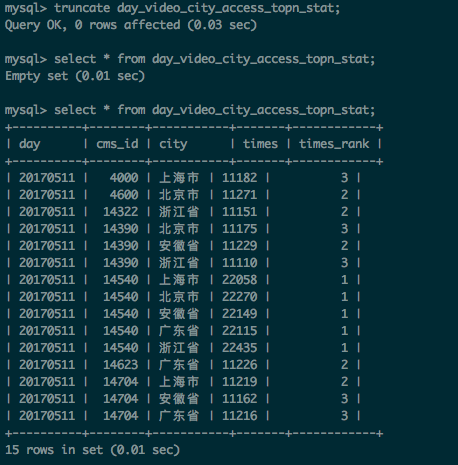
需求三:按照流量进行最受欢迎课程的统计
- 建表
create table day_video_traffics_topn_stat(
day varchar(8) not null,
cms_id bigint(10) not null,
traffics bigint(20) not null,
primary key(day, cms_id));
- 代码实现
/**
* 按照流量进行统计
*/
def videoTrafficsTopNStat(spark: SparkSession, accessDF:DataFrame, day:String): Unit = {
import spark.implicits._
val cityAccessTopNDF = accessDF.filter($"day" === day && $"cmsType" === "video")
.groupBy("day","cmsId").agg(sum("traffic").as("traffics"))
.orderBy($"traffics".desc)
//.show(false)
/**
* 将统计结果写入到MySQL中
*/
try {
cityAccessTopNDF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayVideoTrafficsStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val traffics = info.getAs[Long]("traffics")
list.append(DayVideoTrafficsStat(day, cmsId,traffics))
})
StatDAO.insertDayVideoTrafficsAccessTopN(list)
})
} catch {
case e:Exception => e.printStackTrace()
}
}
运行效果:

合并三个需求
1.为了实现数据覆盖的需求,StatDAO.scala中新增函数,用于删除指定日期的数据:
/**
* 删除指定日期的数据
*/
def deleteData(day: String): Unit = {
val tables = Array("day_video_access_topn_stat",
"day_video_city_access_topn_stat",
"day_video_traffics_topn_stat")
var connection:Connection = null
var pstmt:PreparedStatement = null
try{
connection = MySQLUtils.getConnection()
for(table <- tables) {
// delete from table ....
val deleteSQL = s"delete from $table where day = ?"
pstmt = connection.prepareStatement(deleteSQL)
pstmt.setString(1, day)
pstmt.executeUpdate()
}
}catch {
case e:Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
}
}
}
2.在TopNStatJob.scala中的main函数中调用上述函数,并同时调用实现上述三个需求的函数
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("TopNStatJob")
.config("spark.sql.sources.partitionColumnTypeInference.enabled","false") //分区字段的数据类型调整
.master("local[2]").getOrCreate()
val accessDF = spark.read.format("parquet").load("./clean2")
accessDF.printSchema()
accessDF.show(false)
val day = "20170511"
StatDAO.deleteData(day)
//
// //最受欢迎的TopN课程
videoAccessTopNStat(spark, accessDF, day)
//
// //按照地市进行统计TopN课程
cityAccessTopNStat(spark, accessDF, day)
//
// //按照流量进行统计
videoTrafficsTopNStat(spark, accessDF, day)
spark.stop()
}
运行结果:
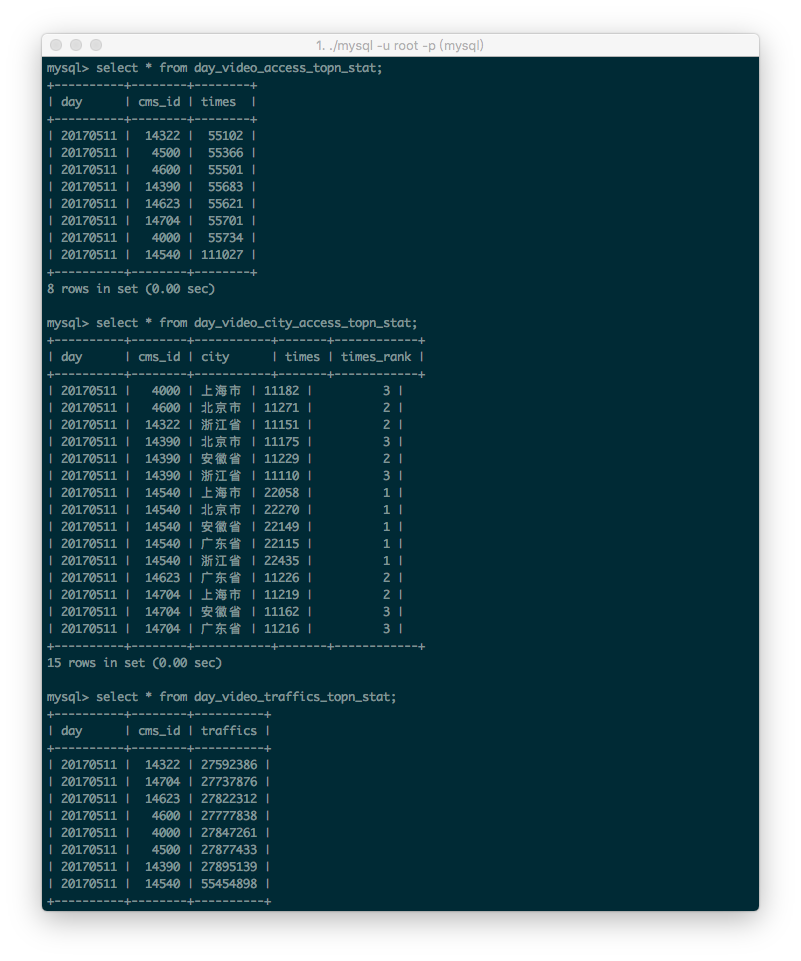














 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









