





概述
指标的 OpenTelemetry 数据模型由协议规范和语义约定组成,用于投递预聚合的指标时间序列数据,该数据模型旨在从现有系统导入数据并将数据导出到现有系统,并支持内部 OpenTelemetry 用例,以从 Spans 或日志流生成指标。
流行的现有指标数据格式可以明确地转换为OpenTelemetry 的指标数据模型,而不会丢失语义或保真度,明确指定从 Prometheus 和 Statsd exposition 格式进行的翻译。
数据模型指定了许多用于收集路径的保留语义的数据转换,支持灵活的系统配置,该模型通过选择累积和增量传输来支持可靠性和无状态控制,该模型通过空间和时间重新聚合支持成本控制。
OpenTelemetry 收集器旨在接受多种格式的指标数据,使用 OpenTelemetry 数据模型传输数据,然后导出到现有系统。通过明确定义的数据转换,包括自动删除属性和降低直方图分辨率的能力,数据模型可以明确地转换为 Prometheus 远程写入协议,而不会丢失特性或语义。
事件 => 数据流 => 时间序列
OTLP Metrics 协议被设计为传输指标数据的标准,为了描述这些数据的预期用途和相关的语义,OpenTelemetry 指标数据流类型将链接到一个框架中,该框架包含一个关于指标 API 和离散输入值的高级模型,以及一个定义时间序列的低级模型和离散输出值,模型之间的关系如下图所示。

该协议旨在满足 OpenCensus Metrics 系统的要求,特别是满足其 Metrics Views 的概念,通过支持收集路径上的数据转换,在 OpenTelemetry Metrics 数据模型中完成视图。
OpenTelemetry 确定了三种保留语义的度量数据转换,这些转换可用于构建度量收集系统作为控制成本、可靠性和资源分配的方法,OpenTelemetry Metrics 数据模型旨在支持这些转换,既可以在数据生成时在 SDK 内进行,也可以作为 OpenTelemetry 收集器内的重新处理阶段进行。这些转变是:
-
时间重新聚合:以高频收集的指标可以重新聚合为更长的间隔,从而允许预先计算或使用低分辨率时间序列来代替原始指标数据。
-
空间重新聚合:使用不需要的属性生成的指标可以重新聚合为具有较少属性的指标。
-
累计增量:以 增量计算 临时性输入和输出的指标减轻了客户端保持高基数状态的负担。增量的使用允许下游服务承担转换为累积时间序列的成本,或者放弃成本并直接计算费率。
OpenTelemetry Metrics 数据流的设计使得这些转换可以自动应用于相同类型的流,但需满足下述条件,每个 OTLP 数据流都有一个内在的可分解聚合函数,使其在语义上得到明确定义,可以跨时间和空间属性合并数据点,每个OTLP数据点还具有两个有意义的时间戳,结合内在聚合,可以对模型的每个基本点进行标准度量数据转换,同时确保结果具有预期含义。
与 OpenCensus Metrics 一样,只需选择聚合间隔和所需属性,即可将指标数据转换为一个或多个视图,通过配置不同的视图,可以将一串 OTLP 数据转换为多个时间序列输出,并且所需的视图处理可以在 SDK 内部应用,也可以由外部收集器应用。
使用用例
指标数据模型是围绕一系列“核心”用例设计的。虽然此列表并不详尽,但它代表了 OTel 指标使用的范围和广度。
-
OTel SDK 将 10 秒分辨率导出到单个 OTel 收集器,使用有状态客户端、无状态服务器的累积时间性:
-
收集器将原始数据传递到 OTLP 目的地
-
收集器在不更改属性的情况下重新聚合为更长的间隔
-
收集器重新聚合成几个不同的视图,每个视图都有可用属性的子集,输出到相同的目的地
-
-
OTel SDK 将 10 秒分辨率导出到单个 OTel 收集器,使用无状态客户端、有状态服务器的增量时间性:
-
收集器重新聚合为 60 秒分辨率
-
收集器将增量转换为累积时间性
-
-
OTel SDK 将 10 秒分辨率(例如 CPU、请求延迟)和 15 分钟分辨率(例如室温)导出到单个 OTel 收集器。收集器将带有或不带有聚合的流向上游导出。
-
许多本地运行的 OTel SDK 每个导出 10 秒分辨率,每个报告给单个(本地)OTel 收集器
-
收集器重新聚合为 60 秒分辨率
-
收集器重新聚合以消除各个 SDK 的身份(例如不同的 service.instance.id 值)
-
收集器输出到 OTLP 目标
-
-
OTel 收集器池接收 OTLP 并导出 Prometheus 远程写入
-
Collector 将服务发现与指标资源结合起来
-
收集器计算“up”,陈旧标记
-
收集器应用独特的外部标签
-
-
OTel 收集器接收 Statsd 并导出 OTLP
-
具有增量临时性:无状态收集器
-
具有累积临时性:有状态收集器
-
-
OTel SDK直接导出到3P后端
这些被认为是用于分析指标数据模型中的权衡和设计决策的“核心”用例。
超出范围的用例
指标数据模型并不是为了成为完美的指标罗塞塔石碑而设计的。以下是一组用例,虽然不会完全不受支持,但不在关键设计决策的范围内:
-
使用 OTLP 作为两种不兼容格式之间的中间格式
-
TODO:定义其他人
模型详情
OpenTelemetry 将指标分为三个交互模型:
-
事件模型,表示仪器如何报告指标数据
-
Timeseries 模型,表示后端如何存储指标数据
-
指标流模型,定义 OpenTeLemetry 协议 (OTLP),表示如何在事件模型和时间序列存储之间操作和传输指标数据流。这是本文档中指定的模型。
事件模型
事件模型是数据记录发生的地方,它的基础由仪器组成,仪器用于通过事件记录可观测数据。然后,这些原始事件在发送到其他系统之前以某种方式进行转换,OpenTelemetry 指标的设计使得可以以不同的方式使用相同的仪器和事件来生成指标流。
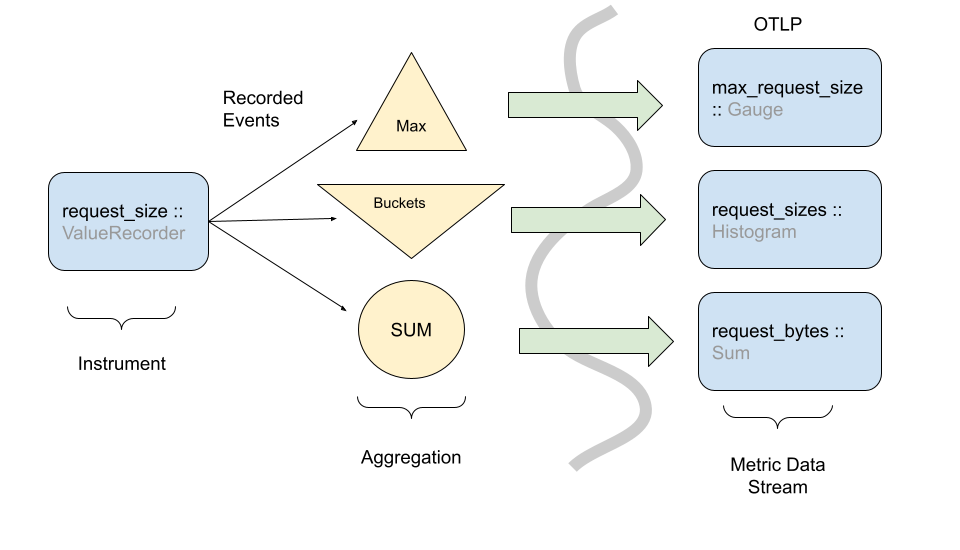
尽管观测事件可以直接报告给后端,但实际上这是不可行的,因为可观测系统中使用的数据量巨大,并且可用于遥测收集目的的网络/CPU 资源有限,最好的例子是直方图指标,其中原始事件以压缩格式而不是单个时间序列记录。
注意:上图显示了一台仪器如何将事件转换为多种类型的指标流,对于何时以及如何执行此操作有一些注意事项和细微差别。指标 API 规范中概述了仪器和指标配置。
虽然 OpenTelemetry 在如何将仪器转换为指标流方面提供了灵活性,但仪器的定义使得可以提供合理的默认映射,API 规范中详细介绍了确切的 OpenTelemetry 仪器。
在事件模型中,主要数据是(仪器,数字)点,最初是实时或按需观察的(分别针对同步和异步情况)。
时间序列模型
在此底层指标数据模型中,时间序列是由多个元数据属性组成的实体定义:
-
指标名称
-
属性(维度)
-
点的值类型(整数、浮点数等)
-
测量单位
每个时间序列的主要数据都是有序的(时间戳,值)点,具有以下值类型之一:
-
Counter(单调、累积)
-
Gauge
-
Histogram
-
Exponential Histogram(指数直方图)
该模型可以被视为 Prometheus Remote Write 的理想化模型,与该协议一样,与隐式或显式不存在相比,我们还关心了解何时定义点值,增量数据点的度量流定义时间间隔值,而不是时间点值。要精确定义数据的存在和不存在,需要进一步开发这些模型之间的对应关系。
注意:Prometheus 并不是 OpenTelemetry 唯一可能映射的时间序列模型,但在本文档中用作参考。
OpenTelemetry 协议数据模型
OpenTelemetry协议(OTLP)数据模型由Metric数据流组成,这些流又由度量数据点组成,指标数据流可以直接转换为时间序列。指标流被分组为单独的指标对象,通过以下方式标识:
-
原始资源属性
-
检测范围(例如,检测库名称、版本)
-
指标流的名称
包括名称在内,Metric 对象由以下属性定义:
-
数据点类型(例如Sum、Gauge、Histogram、ExponentialHistogram、Summary)
-
指标流的单位
-
指标流的描述
-
内在数据点属性(如果适用):AggregationTemporality、Monotonic
数据点类型、单位和内在属性被认为是识别性的,而描述字段本质上是明确不识别的。特定点的外在属性不被视为识别;这些包括但不限于:
-
直方图数据点的桶边界
-
指数直方图数据点的比例或桶计数
Metric 对象包含各个流,由属性集标识,在各个流中,点由一两个时间戳标识,详细信息因数据点类型而异。在某些数据点类型(例如Sum和Gauge)内,数值点值允许存在变化;在这种情况下,相关的变化(即浮点与整数)不被认为是识别的。
OpenTelemetry Protocol 数据模型:生产者建议
生产者应该防止具有相同资源和范围属性的给定名称存在多个度量标识,生产者应该聚合相同 Metric 对象的数据作为基本特征,因此多个 Metric 的出现(被视为“语义错误”)通常需要在某处发生重复的冲突仪器注册。生产者也许能够修复问题,具体取决于他们是 SDK 还是下游处理器:
-
如果潜在冲突涉及非识别属性(即描述),则生产者应该选择较长的字符串
-
如果潜在冲突涉及相似但不同的单位(例如“ms”和“s”),则实现可以转换单位以避免语义错误;否则,实现应该通知用户语义错误并传递冲突的数据
-
如果潜在冲突涉及 AggregationTemporality 属性,则实现可以使用 Cumulative-to-Delta 或 Delta-to-Cumulative 转换来转换时间性;否则,实现应该通知用户语义错误并传递冲突的数据
-
一般来说,对于涉及标识属性(即除描述之外的所有属性)的潜在冲突,生产者应该通知用户语义错误并传递冲突数据
当 OpenTelemetry API 的实现内部发生此类语义错误时,会假定存在固定的 Resource 值,因此,实现 OpenTelemetry API 的 SDK 拥有有关重复仪器注册冲突来源的完整信息,有时能够帮助用户避免语义错误。具体细节请参见SDK规范。
OpenTelemetry 协议数据模型:消费者建议
消费者可以拒绝包含语义错误的 OpenTelemetry Metrics 数据(即给定名称、资源和范围有多个度量标识),尽管这个主题值得关注,但 OpenTelemetry 并未指定任何向最终用户传达此类结果的方法。
点类型
指标流可以使用这些基本点类型之一,所有这些基本点类型都满足上述要求,这意味着它们为同类点定义了可分解的聚合函数(也称为“自然合并”函数)。基本点类型有:
比较 OTLP 指标数据流和时间序列数据模型,OTLP 不会将其点类型 1:1 映射到时间序列点。在 OTLP 中,Sum Point可以表示单调计数或非单调计数。这意味着当Sum是单调时,OTLP Sum被转换为时间序列Counter,或者当Sum不单调时被转换为Gauge。
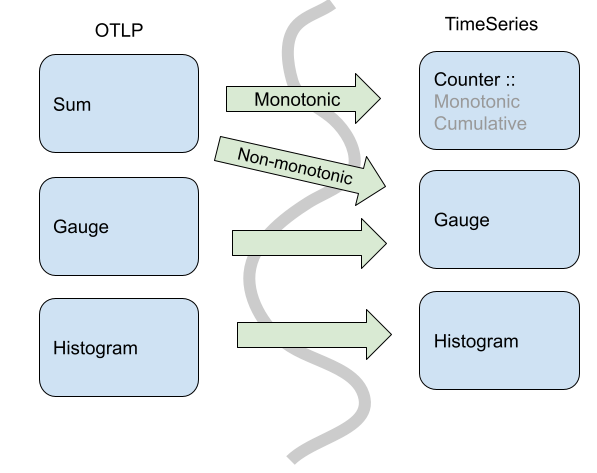
具体来说,在 OpenTelemetry 中,Sums 总是有一个聚合函数,您可以通过加法进行组合,因此,对于 OpenTelemetry 中的非单调Sum,我们可以通过加法(自然地)进行聚合。在时间序列模型中,您不能假设任何特定的 Gauge 都是Sum,因此默认聚合不会是加法。
除了 OTLP 中使用的核心点类型之外,还有专为与现有度量格式兼容而设计的数据类型。
Metric Points
Sums
OTLP 中的Sums由以下部分组成:
-
增量或累积的聚合临时性
-
表示 Sum 是否单调的标志,在指标的这种情况下,这意味着Sums名义上正在增加,我们不失一般性地假设这一点
-
对于增量单调Sums,这意味着读者应该期望非负值
-
对于累积单调Sums,这意味着读者应该期望不小于先前值的值
-
-
一组数据点,每个数据点包含:
-
一组独立的属性名称-值对
-
计算Sum的时间窗口((开始,结束)时间)
-
时间间隔包括结束时间
-
值中指定的时间是自 1970 年 1 月 1 日 00:00:00 UTC 以来的 UNIX 纪元时间(以纳秒为单位)
-
-
(可选)一组示例(请参阅示例)
-
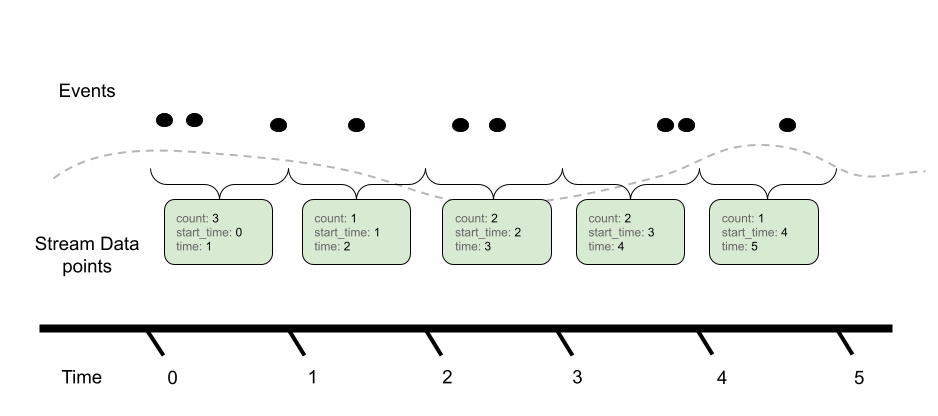
聚合时间性用于理解计算Sum的上下文,当聚合时间为“delta”时,我们期望度量流的时间窗口没有重叠,例如
与累积聚合时间对比,我们期望报告自“开始”以来的全部总和(其中通常开始意味着进程/应用程序启动):
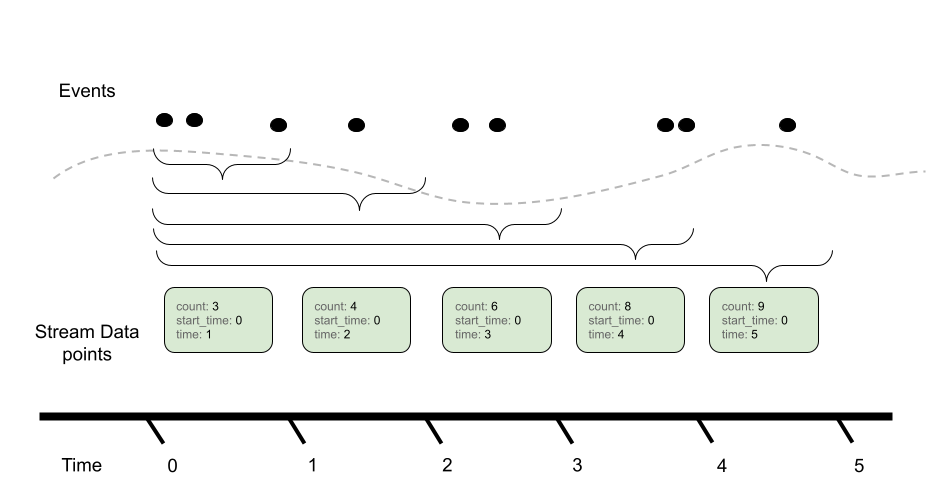
在各种用例中,使用 Delta 与累积聚合之间存在各种权衡,例如:
-
检测进程重新启动
-
计算费率
-
基于推与拉的指标报告
OTLP 支持这两种模型,并允许 API、SDK 和用户确定适合其使用场景的最佳权衡。
Gauge
OTLP 中的 Gauge 表示给定时间的采样值。计量流包括:
-
一组数据点,每个数据点包含:
-
一组独立的属性名称-值对
-
采样值(例如当前 CPU 温度)
-
对值进行采样时的时间戳 (time_unix_nano)
-
(可选)时间戳 (start_time_unix_nano),它最能代表可以记录测量的第一个可能时刻,这通常设置为指标收集系统启动时的时间戳
-
(可选)一组示例(请参阅示例)
-
在 OTLP 中,Gauge 流中的点表示给定时间窗口的最后采样事件。
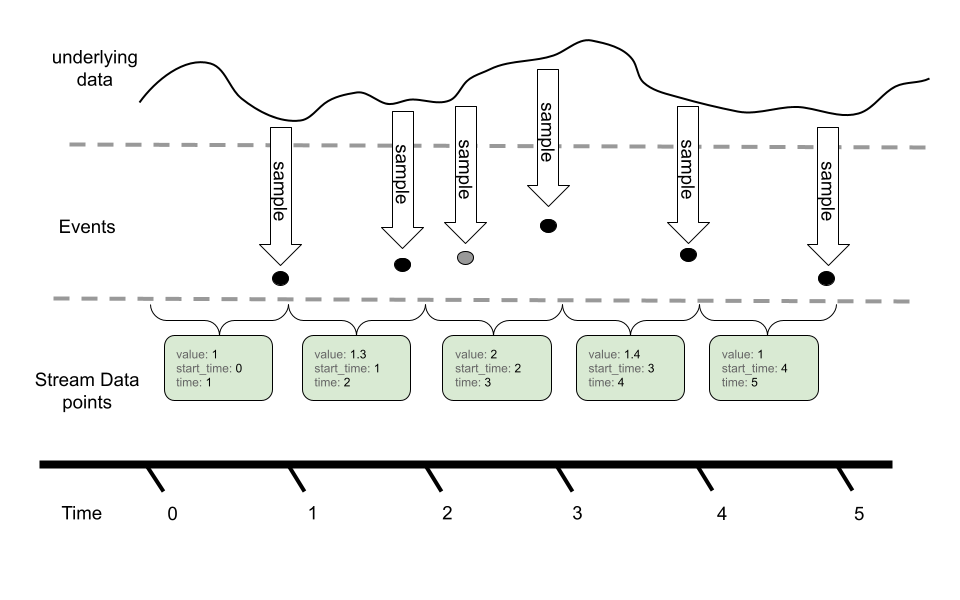
在此示例中,我们可以看到我们使用 Gauge 采样的基础时间序列,虽然事件模型可以在给定的指标报告间隔内多次采样,但通过 OTLP 在指标流中仅报告最后一个值。
Gauge不提供聚合语义,而是在执行时间对齐或调整分辨率等操作时使用“最后一个样本值”。可以通过转换为直方图或其他度量类型来聚合Gauge。这些操作默认情况下不执行,需要用户直接配置。
Histogram
Histogram度量数据点以压缩格式传达大量记录的测量结果。直方图将一组事件捆绑为多个群体,并提供总体事件计数和所有事件的总和。
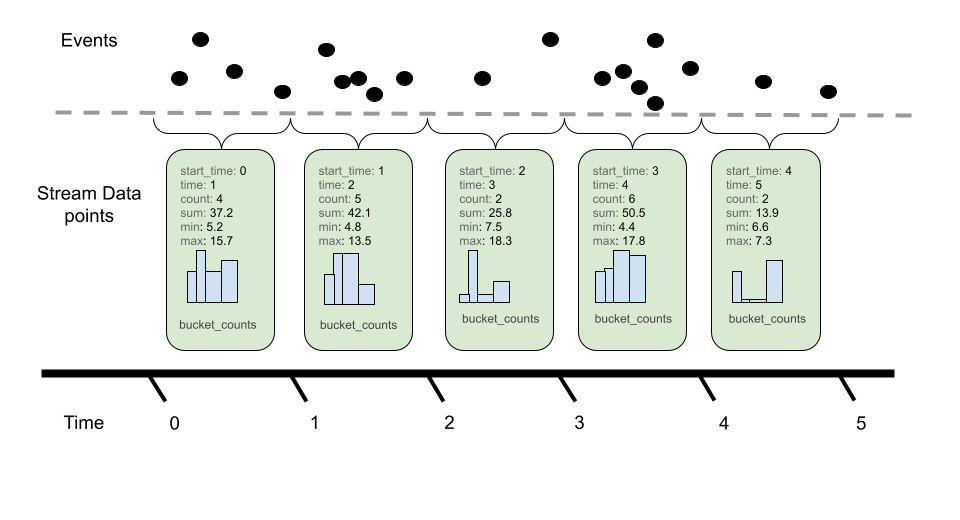
直方图由以下部分组成:
-
增量或累积的聚合临时性
-
一组数据点,每个数据点包含:
-
一组独立的属性名称-值对
-
捆绑直方图的时间窗口((start, end])
-
时间间隔包括结束时间
-
时间值指定为自 UNIX 纪元(1970 年 1 月 1 日 00:00:00 UTC)以来的纳秒
-
-
直方图中点总数的计数(count)
-
直方图中所有值的总和(sum)
-
(可选)直方图中所有值的最小值 (min)
-
(可选)直方图中所有值的最大值(max)
-
(可选)一系列桶,具有:
-
明确的边界值。这些值表示存储桶的下限和上限,以及是否将给定的观察结果记录在该存储桶中
-
属于该存储桶的观测值数量的计数。
-
-
(可选)一组示例(请参阅示例)
-
与Sums一样,直方图也定义聚合时间性。上图表示 Delta 时间性,其中累积的事件计数在报告后重置为零,并发生新的聚合。另一方面,累积继续聚合事件,并使用新的开始时间进行重置。
聚合时间性也对最小和最大字段有影响,最小值和最大值对于增量时间性更有用,因为随着记录更多事件,累积最小值和最大值表示的值将稳定。此外,可以将最小值和最大值从 Delta 转换为 Cumulative,但不能从 Cumulative 转换为 Delta。从累积转换为增量时,可以删除最小值和最大值,或者以替代表示形式(例如仪表)捕获最小值和最大值。
桶数是可选的。没有桶的直方图仅根据总和和计数来传达总体,并且可以解释为具有单桶覆盖的直方图(-Inf,+Inf)
Histogram:桶的包容性
存储桶上限包含在内(上限为+Inf 的情况除外),而存储桶下限不包含在内(左开右闭),也就是说,桶表示大于其下限且小于或等于其上限的值的数量。使用 OpenTelemetry Metrics 数据的导入器和导出器在转换为使用包含下限和排除上限的直方图格式时应忽略此规范。更改边界的包含性和排他性是最坏情况直方图误差的一个示例;用户应该选择直方图边界,以便最坏情况的误差在其误差容忍范围内。
ExponentialHistogram
指数直方图数据点是直方图数据点的替代表示形式,用于以压缩格式传达一组记录的测量值,ExponentialHistogram 使用指数公式压缩桶边界,与类似大小的替代表示相比,使其适合以较小的相对误差传输高动态范围数据。
有关直方图的涉及聚合时间性、属性和时间戳以及 sum、count、min、max 和 exemplars 字段的语句与 ExponentialHistogram 相同。这些字段都与直方图具有相同的解释,只是这两种类型之间的存储桶结构不同。
Exponential Scale
指数直方图的分辨率由称为比例的参数来表征,比例值越大,精度越高。指数直方图的桶边界位于基数的整数次幂处,也称为“增长因子”,其中:
base = 2**(2**(-scale))这些公式中的符号 ** 表示求幂,因此 2**x 读作“2 的 x 次方”,通常由 math.Pow(2.0, x) 等表达式计算,所选比例的计算基值如下所示:
| Scale | Base | Expression |
|---|---|---|
| 10 | 1.00068 | 2**(1/1024) |
| 9 | 1.00135 | 2**(1/512) |
| 8 | 1.00271 | 2**(1/256) |
| 7 | 1.00543 | 2**(1/128) |
| 6 | 1.01089 | 2**(1/64) |
| 5 | 1.02190 | 2**(1/32) |
| 4 | 1.04427 | 2**(1/16) |
| 3 | 1.09051 | 2**(1/8) |
| 2 | 1.18921 | 2**(1/4) |
| 1 | 1.41421 | 2**(1/2) |
| 0 | 2 | 2**1 |
| -1 | 4 | 2**2 |
| -2 | 16 | 2**4 |
| -3 | 256 | 2**8 |
| -4 | 65536 | 2**16 |
该设计的一个重要属性被描述为“完美子集”,具有给定比例的指数直方图的桶精确地映射到具有较小比例的指数直方图的桶中,这允许消费者降低直方图的分辨率(即缩小比例)而不会引入误差。
Exponential Buckets
由索引(有符号整数)标识的指数直方图桶表示总体中大于基数**索引且小于或等于基数**(索引+1)的值,直方图的正负范围分别表示。使用与正值范围相同的比例,将负值按其绝对值映射到负值范围。请注意,因此,在负范围内,直方图桶使用下限边界。ExponentialHistogram 数据点的每个范围都使用桶的密集表示,其中桶的范围表示为单个偏移值、有符号整数和计数值数组,其中数组元素 i 表示桶索引的桶计数偏移+i。
对于给定范围(正数或负数):
-
存储桶索引 0 对范围 (1, base] 内的测量进行计数
-
正索引对应于大于基数的绝对值
-
负索引对应于绝对值小于或等于 1
-
连续的 2 次幂之间有 2** 个刻度桶
例如,当scale=3时,1和2之间有2**3个桶,请注意,scale=3 直方图中存储桶索引 4 的下边界映射到scale=2 直方图中存储桶索引 2 的下边界,并映射到scale=3 直方图中存储桶索引 1(即基数)的下边界。 1 个直方图——这些是完美子集的示例。
scale=3 bucket index | lower boundary | equation |
|---|---|---|
| 0 | 1 | 2**(0/8) |
| 1 | 1.09051 | 2**(1/8) |
| 2 | 1.18921 | 2**(2/8), 2**(1/4) |
| 3 | 1.29684 | 2**(3/8) |
| 4 | 1.41421 | 2**(4/8), 2**(2/4), 2**(1/2) |
| 5 | 1.54221 | 2**(5/8) |
| 6 | 1.68179 | 2**(6/8) |
| 7 | 1.83401 | 2**(7/8) |
零计数和零阈值
ExponentialHistogram 包含一个特殊的 Zero_count 存储桶和一个可选的 Zero_threshold 字段,其中 Zero_count 包含绝对值小于或等于 Zero_threshold 的值的计数,Zero_threshold 的精确值是任意的并且与比例无关。
当zero_threshold未设置或为0时,该存储桶存储无法使用标准指数公式表达的值以及已四舍五入为零的值。
具有不同zero_threshold的直方图仍然可以通过取所有涉及的直方图中最大的zero_threshold并将具有较小zero_threshold的直方图的较低桶合并到公共更宽的零桶中来轻松地合并。如果合并的zero_threshold位于填充桶的中间,则需要增加它以匹配桶的上边界。
在特殊情况下,可以使用更宽的零桶来限制填充桶的总数。
Producer Expectations
生产者可以使用不精确的映射函数,因为在一般情况下:
-
精确映射函数的实现要复杂得多
-
对于所有尺度,边界不能精确地表示为浮点数
一般来说,生产者应该使用一个映射函数,其与所有输入的正确结果的预期差异最多为 1。
ExponentialHistogram 设计可以表达太大或太小而无法以 64 位“双”浮点格式表示的值。某些比例值虽然有意义,但不一定有用。
指数直方图表示的数据范围决定了可以有效应用哪些尺度。无论规模如何,生产者都应该确保任何编码桶的索引落在有符号的 32 位整数的范围内。此建议适用于限制标准处理管道(例如 OpenTelemetry 收集器)中使用的整数的宽度。在未来的版本中,线路级协议可以扩展到 64 位存储桶索引。
生产者使用映射函数来计算桶索引。假定生产者支持具有 11 位指数和 52 位有效数的 IEEE 双角浮点数。下面将值映射到指数的伪代码引用以下常量:
const (
// SignificandWidth is the size of an IEEE 754 double-precision
// floating-point significand.
SignificandWidth = 52
// ExponentWidth is the size of an IEEE 754 double-precision
// floating-point exponent.
ExponentWidth = 11
// SignificandMask is the mask for the significand of an IEEE 754
// double-precision floating-point value: 0xFFFFFFFFFFFFF.
SignificandMask = 1 << SignificandWidth - 1
// ExponentBias is the exponent bias specified for encoding
// the IEEE 754 double-precision floating point exponent: 1023.
ExponentBias = 1 << (ExponentWidth-1) - 1
// ExponentMask are set to 1 for the bits of an IEEE 754
// floating point exponent: 0x7FF0000000000000.
ExponentMask = ((1 << ExponentWidth) - 1) << SignificandWidth
)以下映射函数的选择已通过参考实现进行了验证。
Scale Zero: Extract the Exponent
对于零标度,值的索引等于其归一化的以 2 为底的指数,这意味着以 2 为底的小数表示形式 1._significand_ * 2**_exponent_ 中的指数值。正常 IEEE 754 双角浮点值的索引范围为 [-1022, +1023],次正常值的索引范围为 [-1074, -1023]。这可以写成:
// MapToIndexScale0 computes a bucket index at scale 0.
func MapToIndexScale0(value float64) int32 {
rawBits := math.Float64bits(value)
// rawExponent is an 11-bit biased representation of the base-2
// exponent:
// - value 0 indicates a subnormal representation or a zero value
// - value 2047 indicates an Inf or NaN value
// - value [1, 2046] are offset by ExponentBias (1023)
rawExponent := (int64(rawBits) & ExponentMask) >> SignificandWidth
// rawFragment represents (significand-1) for normal numbers,
// where significand is in the range [1, 2).
rawFragment := rawBits & SignificandMask
// Check for subnormal values:
if rawExponent == 0 {
// Handle subnormal values: rawFragment cannot be zero
// unless value is zero. Subnormal values have up to 52 bits
// set, so for example greatest subnormal power of two, 0x1p-1023, has
// rawFragment = 0x8000000000000. Expressed in 64 bits, the value
// (rawFragment-1) = 0x0007ffffffffffff has 13 leading zeros.
rawExponent -= int64(bits.LeadingZeros64(rawFragment - 1) - 12)
// In the example with 0x1p-1023, the preceding expression subtracts
// (13-12)=1, leaving the rawExponent equal to -1. The next statement
// below subtracts `ExponentBias` (1023), leaving `ieeeExponent` equal
// to -1024, which is the correct upper-inclusive bucket index for
// the value 0x1p-1023.
}
ieeeExponent := int32(rawExponent - ExponentBias)
// Note that rawFragment and rawExponent cannot both be zero,
// or else the value is exactly zero, in which case the the ZeroCount
// bucket is used.
if rawFragment == 0 {
// Special case for normal power-of-two values: subtract one.
return ieeeExponent - 1
}
return ieeeExponent
}
允许实现将次正常值舍入到最小正常值,这可能允许使用内置函数:
// MapToIndexScale0 computes a bucket index at scale 0.
func MapToIndexScale0(value float64) int {
// Note: Frexp() rounds submnormal values to the smallest normal
// value and returns an exponent corresponding to fractions in the
// range [0.5, 1), whereas an exponent for the range [1, 2), so
// subtract 1 from the exponent immediately.
frac, exp := math.Frexp(value)
exp--
if frac == 0.5 {
// Special case for powers of two: they fall into the bucket
// numbered one less.
exp--
}
return exp
}Negative Scale: Extract and Shift the Exponent
对于负比例,值的索引等于标准化的以 2 为底的指数(如上面的 MapToIndexScale0() 所示)向右移动 -scale。请注意,由于符号扩展,此移位对负索引执行正确的舍入。这可以写成:
// MapToIndexNegativeScale computes a bucket index for scales <= 0.
func MapToIndexNegativeScale(value float64) int {
return MapToIndexScale0(value) >> -scale
}逆映射函数为:
// LowerBoundaryNegativeScale computes the lower boundary for index
// with scales <= 0.
func LowerBoundaryNegativeScale(index int) {
return math.Ldexp(1, index << -scale)
}请注意,即使映射函数将它们舍入为正常值,反向映射函数也预计会产生次正常值,因为包含最小正常值的桶的下边界可能是次正常的。例如,在标度 -4 处,最小正常值 0x1p-1022 落入下边界为 0x1p-1024 的桶中。
All Scales: Use the Logarithm Function
建议使用上述零尺度和负尺度的映射和反向映射函数,因为它们是精确的。在这些规模下,math.Log() 可能不准确,并且比直接计算存储桶索引更昂贵。本节中的方法可以在所有尺度上使用,尽管它们对于正尺度绝对有用。内置的自然对数函数可用于通过应用缩放因子来计算存储桶索引,其推导如下。
-
指数底数定义为底数 == 2**(2**(-scale))
-
我们想要索引,其中 base**index < value <= base**(index+1)
-
应用以底为底的对数,即 log_base(base**index) < log_base(value) <= log_base(base**(index+1)) (其中 log_X(Y) 表示 Y 的以 X 为底的对数)
-
使用 log_X(X**Y) == Y 重写:
-
因此,index < log_base(value) <= index+1
-
使用 Ceiling() 函数简化方程: Ceiling(log_base(value)) == index+1
-
每边减一:index == Ceiling(log_base(value)) - 1
-
使用 log_X(Y) == log_N(Y) / log_N(X) 重写以允许使用自然对数
-
因此,index == Ceiling(log(value)/log(base)) - 1
-
比例因子 1/log(base) 可以使用 (1)、(4) 和 (8) 中的公式导出
缩放因子等于 2**scale / log(2) 可以写为 math.Ldexp(math.Log2E,scale),因为常量 math.Log2E 定义为 1/log(2)。将其放在一起:
// MapToIndex for any scale.
func MapToIndex(value float64) int {
scaleFactor := math.Ldexp(math.Log2E, scale)
return math.Ceil(math.Log(value) * scaleFactor) - 1
}使用 math.Log() 计算存储桶索引不能保证在 2 的幂附近完全正确。由于不准确,边界附近的值可能会被映射到不正确的存储桶中。定义精确的映射函数超出了本文档的范围。
然而,当输入是 2 的精确幂时,可以计算出精确正确的桶索引。由于检查 2 的精确幂相对简单,因此实现应该应用这样的特殊情况:
// MapToIndex for any scale, exact for powers of two.
func MapToIndex(value float64) int {
// Special case for power-of-two values.
if frac, exp := math.Frexp(value); frac == 0.5 {
return ((exp - 1) << scale) - 1
}
scaleFactor := math.Ldexp(math.Log2E, scale)
// Note: math.Floor(value) equals math.Ceil(value)-1 when value
// is not a power of two, which is checked above.
return math.Floor(math.Log(value) * scaleFactor)
}正尺度的逆映射函数为:
// LowerBoundary computes the bucket boundary for positive scales.
func LowerBoundary(index int) float64 {
inverseFactor := math.Ldexp(math.Ln2, -scale)
return math.Exp(index * inverseFactor), nil
}预计实现将验证其映射函数和逆映射函数在最低和最高 IEEE 浮点值附近是否正确。由于累积的浮点计算误差或中间结果的下溢/上溢,数学上正确的公式可能会产生错误的结果。例如,在 Golang 参考实现中,上面的公式计算最大索引存储桶的 +Inf。在这种情况下,适当的做法是从索引中减去 1<<scale,并将结果乘以 2。
func LowerBoundary(index int) float64 {
// Use this form in case the equation above computes +Inf
// as the lower boundary of a valid bucket.
inverseFactor := math.Ldexp(math.Ln2, -scale)
return 2.0 * math.Exp((index - (1 << scale)) * inverseFactor), nil
}例如,在 Golang 参考实现中,上述公式并不能准确计算最小索引桶的下边界(它是一个次正常值)。在这种情况下,适当的做法是在索引上加上 1<<scale,并将结果除以 2。
请注意,上面的代码片段中省略了浮点到整数类型的转换,以提高可读性。
指数直方图:生产者建议
在 64 位 IEEE 浮点的最低或最高端,桶的范围只能部分地由浮点数格式表示。当在这些桶中映射数字时,生产者可以正确返回此类部分可表示的桶的索引。这被认为是正常情况。
对于正尺度,对数方法是首选,因为它需要很少的代码,易于验证,并且几乎与查找表方法一样快速和准确。对于零刻度和负刻度,直接从浮点表示计算索引更有效。
使用内置对数函数可能会导致结果与使用任意精度或查找表计算的存储桶索引不同,但生产者不需要执行精确计算。因此,指数直方图示例可以映射到计数为零的桶中。我们期望找到在相邻桶中计数的此类值。
指数直方图:消费者建议
ExponentialHistogram 桶索引预计会映射到桶中,其中上边界和下边界都可以使用 IEEE 754 双宽浮点值表示。消费者可以将部分可表示的存储桶索引的不可表示边界舍入到最接近的可表示值。
消费者应该拒绝带有溢出或下溢此表示的比例和桶索引的 ExponentialHistogram 数据。拒绝此类数据的消费者应该通过错误记录来警告用户收到了超出范围的数据。
指数直方图:桶包含性
针对显式边界直方图数据制定的桶包含性规范同样适用于指数直方图数据。
Summary (Legacy)
Summary度量数据点传达分位数摘要,例如我的 HTTP 服务器的第 99 个百分位延迟是多少?与 OpenTelemetry 中的其他点类型不同,Summary点不能始终以有意义的方式合并。不建议将这种点类型用于新应用程序,而是为了与其他格式兼容而存在。
Summary包括以下内容:
-
一组数据点,每个数据点包含:
-
一组独立的属性名称-值对
-
对值进行采样时的时间戳 (time_unix_nano)
-
(可选)时间戳 (start_time_unix_nano),表示Summary的观察收集的开始时间
-
数据点总体中观测值的计数
-
总体中值的总和
-
一组分位数值(按严格递增顺序),包括:
-
分布的分位数,在区间 [0.0, 1.0] 内。例如,值 0.9 代表第 90 个百分点
-
分位数的值。这必须是非负的
-
-
分位数值 0.0 和 1.0 分别定义为等于最小值和最大值,分位数值不需要表示在 start_time_unix_nano 和 time_unix_nano 之间观察到的值,并且预计将根据最近的时间窗口(通常是最后 5-10 分钟)进行计算。
Exemplars
示例是将 OpenTelemetry 上下文与指标中的指标事件相关联的记录值。一种用例是允许用户将跟踪信号与指标链接起来。
示例包括:
-
(可选)与记录关联的跟踪(trace_id、span_id)
-
观察时间(time_unix_nano)
-
记录值(值)
-
一组过滤属性 (filtered_attributes),可在进行观察时提供对上下文的额外洞察
对于直方图,当存在样本时,其值已经参与到直方图点报告的bucket_counts、count和sum中;对于 Sums,当存在样本时,其值已包含在总和中;对于量规,当存在样本时,其值会在同一源的量规间隔内的某个点看到。
Single-Writer
OTLP 中的所有度量数据流必须有一个逻辑写入器。从概念上讲,这意味着从协议创建的任何时间序列都必须有一个原始的事实来源。实际上,这意味着以下内容:
- OTel SDK 生成的所有指标数据流在任何给定时间点都应具有全局唯一标识。度量标识如上定义。
-
度量流的聚合必须仅在任何给定时间点从单个逻辑源写入。注意:这意味着聚合的指标流必须到达一个目的地。
在系统中,多个写入器可能会为同一度量流发送数据(重复)。例如,如果 SDK 实现无法找到组件的唯一标识资源属性,则该组件的所有实例都可能会报告指标,就好像它们来自同一资源一样。在这种情况下,将以不一致的时间间隔报告指标。对于诸如累积总和之类的指标,这可能会导致问题,即成对的点似乎会重置累积总和,从而导致指标不可用。
度量标准流的多个编写器被视为错误状态或行为不当的系统。接收者应该假定单个写入者是有意的并消除重叠/重复数据删除。
注意:身份是大多数度量系统中的一个重要概念。比如普罗米修斯就直接喊出了唯一性: 请注意 labeldrop 和 labelkeep,以确保在标签被删除后指标仍然具有唯一的标签。
对于 OTLP,单写入器原则提供了一种对错误场景进行推理并采取纠正措施的方法。此外,它还确保行为良好的系统可以执行度量流操作,而不会出现不必要的性能下降或可见性损失。
请注意,违反单写入器原则不是语义错误,通常是由于配置错误造成的。虽然语义错误有时可以通过配置视图来纠正,但违反单写入者原则可以通过区分所使用的资源或确保给定资源和属性集的流在时间上不重叠来纠正。
Temporality
时间性的概念是指与时间相关的累加量的表达方式,指示报告的值是否包含先前的测量值。特别是,总和、直方图和指数直方图数据点支持聚合时间性的选择。
每个 OTLP 指标数据点都有两个关联的时间戳。第一个强制时间戳是与观察相关的时间戳,即测量生效或生效的时刻,称为 TimeUnixNano。第二个可选时间戳用于指示点序列何时未中断,称为 StartTimeUnixNano。
强烈建议对 Sum、Histogram 和 ExponentialHistogram 点使用第二个时间戳,因为有必要以可识别重新启动的方式正确解释 OTLP 流中的速率。使用 StartTimeUnixNano 来指示不间断的点序列的开始意味着它也可以用于对流中的隐式间隙进行编码。
-
累积时间性意味着连续的数据点重复起始时间戳。例如,从开始时间 T0 开始,累积数据点涵盖时间范围 (T0, T1]、(T0, T2]、(T0, T3] 等)。
-
增量时间性意味着连续的数据点提前开始时间戳。例如,从开始时间 T0 开始,增量数据点涵盖时间范围 (T0, T1]、(T1, T2]、(T2, T3] 等)。
对单调和使用累积时间性很常见,普罗米修斯就是一个例子。就增加可靠性的成本而言,基于累积单调和的系统自然更简单。当收集间歇性失败时,数据中的间隙自然会根据累积测量值进行平均。累积数据要求发送者记住所有先前的测量结果,这是与基数成正比的“预先”内存成本。
使用增量时间性来计算度量总和也很常见,Statsd 就是一个例子。 OpenTelemetry 跟踪之间存在联系,其中 Span 事件通常被转换为两个度量事件(1 计数和计时测量)。 Delta 时间性支持采样并支持将基数成本转移到流程之外。
重置和差距
当 StartTimeUnixNano 字段存在时,它允许使用者观察流中何时存在间隙和重叠写入器。如果使用得当,消费者可以观察到暂时和持续违反单写入器原则的行为以及重置事件。在不间断的观察序列中,StartTimeUnixNano 始终与同一序列中其他点的 TimeUnixNano 或 StartTimeUnixNano 匹配。对于连续序列中的初始点:
-
当 StartTimeUnixNano 小于 TimeUnixNano 时,新的不间断观察序列以已知开始时间的“真实”重置开始。零值是隐式的,不需要记录起始点。
-
当 StartTimeUnixNano 等于 TimeUnixNano 时,新的不间断观察序列会以未知开始时间的重置开始。记录初始观测值以指示恢复不间断的观测序列。这些点的持续时间为零,表明对先前报告的点一无所知,并且数据可能已丢失。
对于连续序列中的后续点:
-
对于具有增量聚合时间性的点,每个点的 StartTimeUnixNano 与前一个点的 TimeUnixNano 匹配
-
否则,每个点的 StartTimeUnixNano 与初始观察的 StartTimeUnixNano 匹配。
度量流有一个间隙,在该间隙中它是隐式未定义的,只要存在时间范围,则没有点通过其 StartTimeUnixNano 和 TimeUnixNano 字段覆盖该范围。
累积流:处理未知的开始时间
如上所述,不间断的观察流以零持续时间点和非零值恢复。对于具有累积聚合时间性的点,每个点对时间序列的贡献率取决于流中的先前点值。
要正确计算不间断序列中第一个点的速率贡献,需要知道它是否是第一个点。未知的开始时间重置点出现,TimeUnixNano 等于点流的 StartTimeUnixNano,在这种情况下,第一个点的速率贡献被视为零。较早的观测序列预计会在观测间隙之前报告相同的累积状态。
TimeUnixNano 等于 StartTimeUnixNano 的点的存在或不存在指示如何从序列中的第一个点开始计算速率贡献。如果未知启动时间重置序列中的第一个点丢失,则该数据的使用者可能会过度计算第二个点的速率贡献,因为它看起来像是“真正的”重置。
可以采取各种方法来避免过度计数。例如,系统可以使用流中较早的状态来解决开始时间的歧义。
累积流:插入真正的重置点
累积计数器的绝对值通常被认为是有意义的,但是当累积值仅用于计算速率函数时,可以丢弃初始未知的启动时间重置点,但记住最初观察到的值以便修改随后的观察。随后在累积序列中输出相对于初始值的值,因此显示为未知常数的真实重置偏移。
此过程称为插入真正的重置点,是累积序列重新聚合的特殊情况。
重叠
当在一个时间窗口内为度量流定义多个度量数据点时,就会发生重叠。重叠通常是由于错误配置引起的,并且可能导致对数据的严重误解。建议使用 StartTimeUnixNano,以便消费者能够识别并响应重叠点。
我们定义了处理重叠的三个原则:
-
分辨率(通过滴点校正)
-
可观察性(允许数据流向后端)
-
插值(通过数据操作进行校正)
重叠分辨率
当多个进程写入相同的度量数据流时,OTLP 数据点可能会出现重叠。这种情况通常是由于配置错误造成的,但也可能是由于运行相同的进程造成的(表明操作系统或 SDK 错误,例如缺少进程属性)。当存在重叠点时,接收者应该消除点,以便不存在重叠。没有指定在重叠情况下选择哪些数据。
重叠可观察性
OpenTelemetry 收集器在观察数据流中的重叠点时应该导出遥测数据,以便用户可以监视错误的配置。
重叠插值
当一个进程在另一个进程退出时启动时,可能会出现重叠点。在这种情况下,OpenTelemetry 收集器应该使用 Sum 数据点插值来修改转换时的点,以在这些情况下将间隙减少到零宽度,而没有任何重叠。
流操作
总和:Delta 到累积
虽然 OpenTelemetry(和一些指标后端)允许报告增量和累积总和,但我们目标的时间序列模型不支持增量计数器。为此,需要定义从增量到累积的转换,以便后端可以使用此机制。
从增量点转换为累积点本质上是一个有状态的操作。为了成功转换,我们需要所有传入的增量点到达一个目的地,该目的地可以保持当前计数器状态并生成新的累积数据流(请参阅单写入器原理)。
算法安排如下:
-
在收到给定计数器的第一个 Delta 点后,我们进行以下设置
-
存储累积和的新计数器,设置为初始计数器。
-
与第一个点的开始时间一致的开始时间。
-
与第一个点的时间一致的“上次查看”时间。
-
-
在收到未来的达美积分后,我们将执行以下操作:
-
如果下一个点与预期的下一次窗口一致(请参阅检测增量重新启动)
- 更新“上次查看”时间以与当前点的时间保持一致。
- 将当前值添加到累积计数器
- 输出一个新的累积点,其中包含原始开始时间和当前上次看到的时间和计数。
- 如果当前点早于开始时间,则删除该点。注意:有一些算法可以处理迟到的点。
- 如果下一个点与预期的下一次窗口不对齐,则按照与当前点是第一个看到的点相同的步骤执行操作来重置计数器。
-
Sums:检测对齐问题
当给定指标流报告的下一个增量总和与我们预期的不一致时,可能会发生以下几种情况之一:
- 流程报告指标已重新启动,导致指标出现新的报告间隔。
- 多个进程报告相同的指标流,违反了单写入者原则。
-
数据点丢失或信息丢失。
在所有这些场景中,我们尽最大努力提供一些数据丢失的累积指标知识,并重置计数器。
我们通过两种机制检测对齐:
-
如果传入的增量时间间隔与前一个时间间隔有显着重叠,我们假设违反了单写入器原则,并且可以使用以下选项之一进行处理:
-
只需报告时间间隔的不一致,因为错误情况可能是由错误配置引起的。
-
消除接收端的重叠/重复数据删除。
-
通过区分所使用的给定资源和属性集与重叠时间来纠正不一致的时间间隔
-
-
如果传入的增量时间间隔与上次看到的时间有很大差距,我们假设某种重新启动/重新启动并重置累积计数器。
总和:缺少时间戳
增量到累积算法的一种退化情况是度量数据点中缺少时间戳。虽然使用 OpenTelemetry 生成的指标时不应出现这种情况,但在采用其他指标格式时可能会发生这种情况,例如StatsD 计数。
在这种情况下,由于无法确定对齐或点重叠,上面列出的算法将重置每个数据点的累积和。为了进行比较,请参阅 statsd sum 中使用的简单逻辑,其中添加所有点,并忽略丢失的点。
附注
[1] OTLP 支持不满足这些条件的数据点类型;它们定义明确,但不支持标准度量数据转换。

















 1724
1724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









