







我把面试题大致分为:字符匹配,字符分割,字符截取,字符转换
1、字符匹配
1、匹配:匹配以尖括号括起来的以a开头的字符串
var str = "this is a <a herf='www.baidu.com'>,not a <img src='xxx'>";
var reg = /<a[^>]+>/g;
console.log(str.match(reg));
//["<a herf='www.baidu.com'>"]

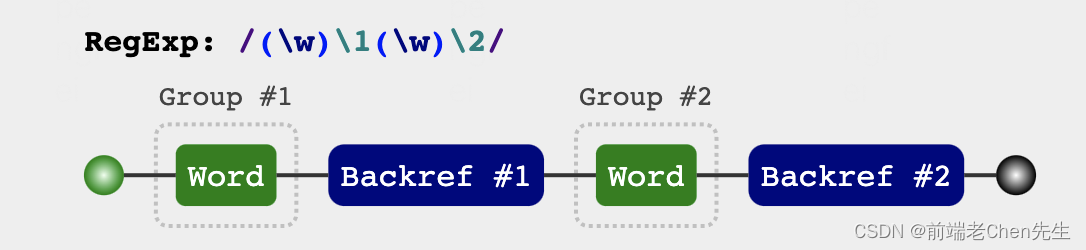
2、匹配:xxyy模式
var reg = /(\w)\1(\w)\2/g;
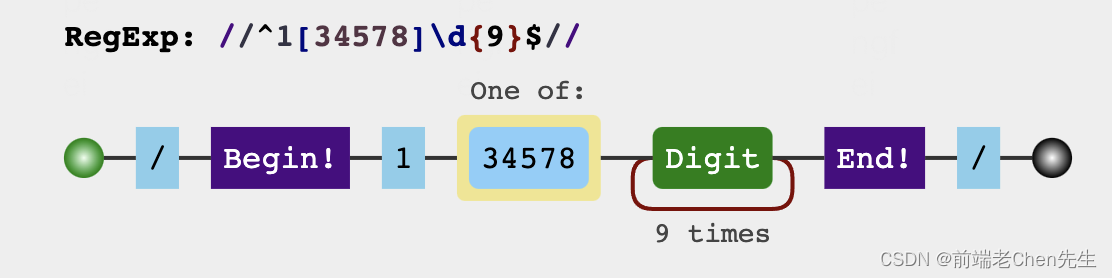
3、匹配:判断是否符合电话号码格式
function isPhone(tel) {
var regx = /^1[34578]\d{9}$/;
return regx.test(tel);
}
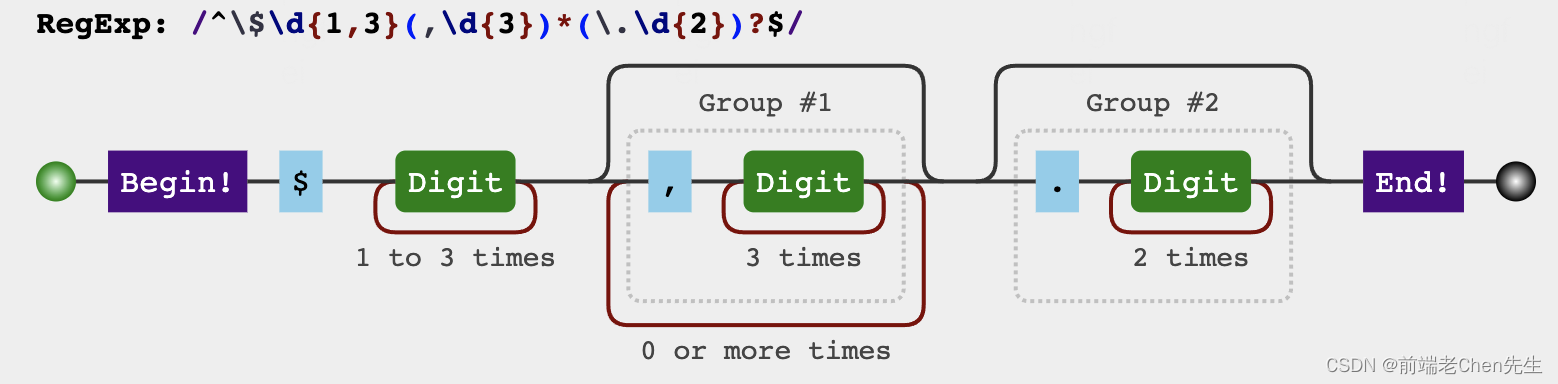
4、匹配:判断是否符合美元$格式
题目:给定字符串 str,检查其是否符合美元$书写格式
1、以 $ 开始
2、整数部分,从个位起,满 3 个数字用,分隔
3、如果有小数部分,则小数部分长度为 2
正确的格式如:$1,023,032.03 或者 $2.03
错误的格式如:$3,432,12.12 或者 $34,344.3
function isUSD(str) {
var regx = /^\$\d{1,3}(,\d{3})*(\.\d{2})?$/;
return regx.test(str);
}
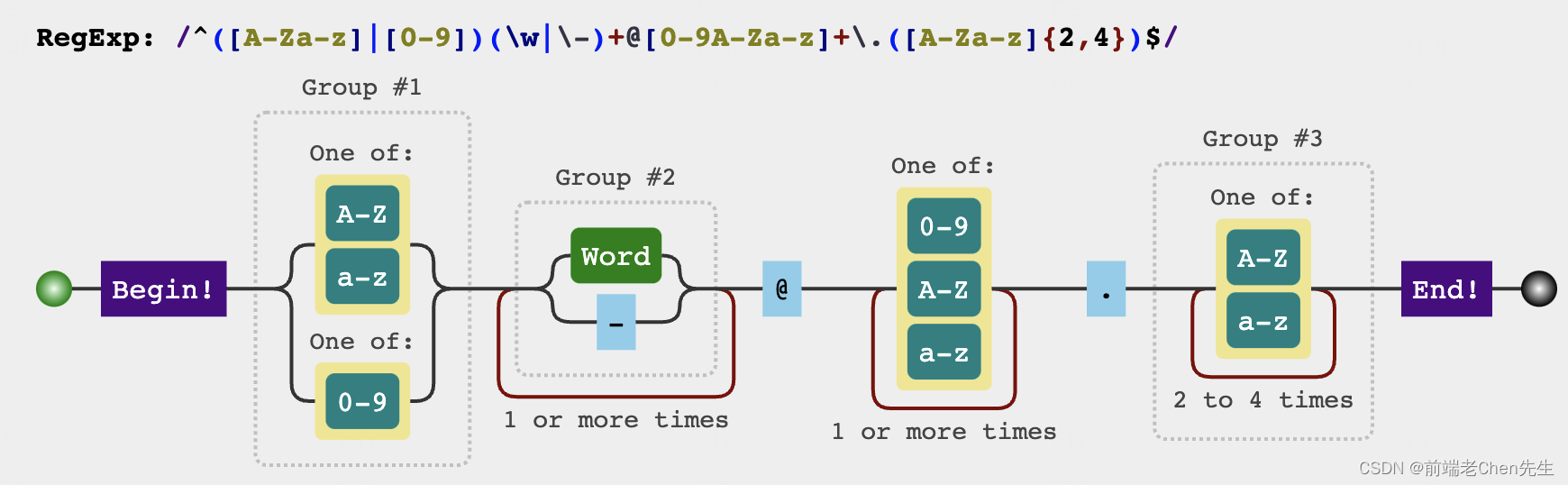
5、匹配:判断是否符合邮箱格式
题目:写出正则匹配邮箱格式。
因为邮箱的格式每个地方都不一样,但是大致原理都相似,所以这里只写基本的路径匹配
function isEmail(email) {
var regx = /^([a-zA-Z]|[0-9])(\w|\-)+@[a-zA-Z0-9]+\.([a-zA-Z]{2,4})$/;
return regx.test(email);
}
isEmail("12345678@qq.com") //true
function isEmail(email) {
var regx = /^([A-Za-z0-9_\-\.])+\@([A-Za-z0-9_\-\.])+\.([A-Za-z]{2,4})$/
return regx.test(email);
}
isEmail("12345发货678@qq.com")//false
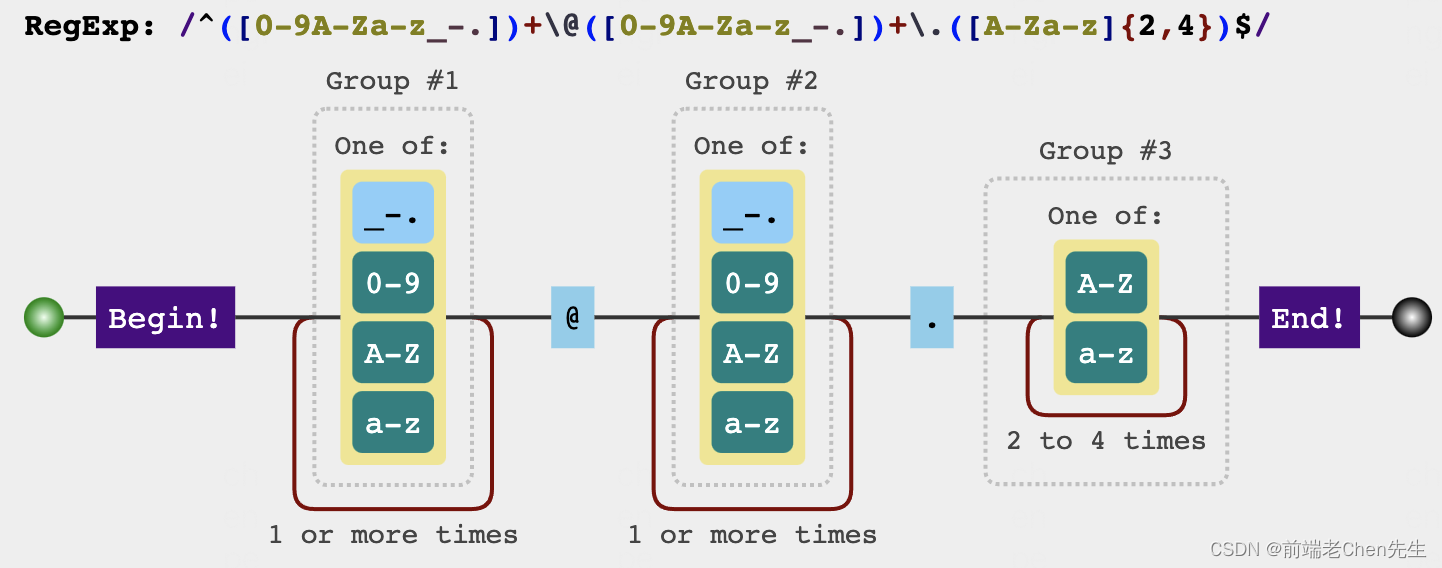
6、匹配:判断是否符合身份证格式
题目:身份证号码可能为15位或18位,15位为全数字,18位中前17位为数字,最后一位为数字或者X,写出正则匹配出身份证格式
function isCardNo(number) {
var regx = /(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)/;
return regx.test(number);
}
isCardNo('123456789012345678') //true
7、匹配:匹配密码合法性
题目:密码长度是6-12位,由数字、小写字母和大写字母组成,但必须至少包括2种字符
let reg = /(((?=.*\d)((?=.*[a-z])|(?=.*[A-Z])))|(?=.*[a-z])(?=.*[A-Z]))^[a-zA-Z\d]{6,12}$/
console.log(reg.test('123456')) // false
console.log(reg.test('aaaaaa')) // false
console.log(reg.test('AAAAAAA')) // false
console.log(reg.test('1a1a1a')) // true
console.log(reg.test('1A1A1A')) // true
console.log(reg.test('aAaAaA')) // true
console.log(reg.test('1aA1aA1aA')) // true
分析过程:
题目由三个条件组成:
- 密码长度是6-12位
- 由数字、小写字符和大写字母组成
- 必须至少包括2种字符
第一步:满足条件1、2
cosnt reg = /^[a-zA-Z\d]{6,12}$/
第二步:必须包含某种字符(数字、大写字母、小写字母)
let reg = /(?=.*\d)/
// 这个正则的意思是,匹配的是一个位置
// 这个位置需要满足`任意数量的符号,紧跟着是个数字`,
// 注意它最终得到的是个位置而不是其他的东西
// (?=.*\d)经常用来做条件限制
console.log(reg.test('hello')) // false
console.log(reg.test('hello1')) // true
console.log(reg.test('hel2lo')) // true
第三步:必须包含2种及以上字符
有下面四种排列组合方式:
- 数字和小写字母组合
- 数字和大写字母组合
- 小写字母与大写字母组合
- 数字、小写字母、大写字母一起组合(但其实前面三种已经覆盖了第四种了)
// 表示条件1和2
let reg = /((?=.*\d)((?=.*[a-z])|(?=.*[A-Z])))/
// 表示条件条件3
let reg = /(?=.*[a-z])(?=.*[A-Z])/
// 表示条件123
let reg = /((?=.*\d)((?=.*[a-z])|(?=.*[A-Z])))|(?=.*[a-z])(?=.*[A-Z])/
// 表示题目所有条件
let reg = /(((?=.*\d)((?=.*[a-z])|(?=.*[A-Z])))|(?=.*[a-z])(?=.*[A-Z]))^[a-zA-Z\d]{6,12}$/
console.log(reg.test('123456')) // false
console.log(reg.test('aaaaaa')) // false
console.log(reg.test('AAAAAAA')) // false
console.log(reg.test('1a1a1a')) // true
console.log(reg.test('1A1A1A')) // true
console.log(reg.test('aAaAaA')) // true
console.log(reg.test('1aA1aA1aA')) // true
2、字符分割
1、分割:数字价格千分位分割
题目:将123456789变成123,456,789
var str = '123456789000'
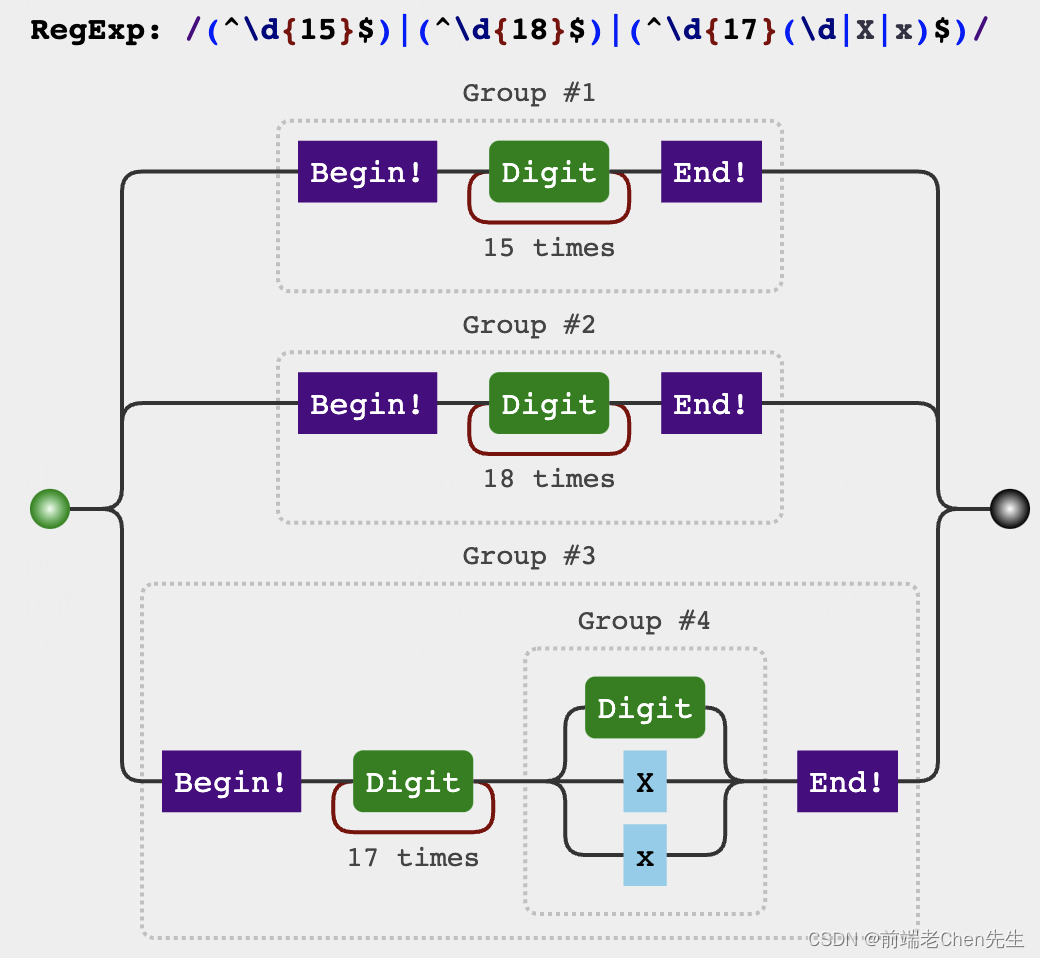
var reg = /(?!^)(?=(\d{3})+$)/g
str.replace(reg,'.')
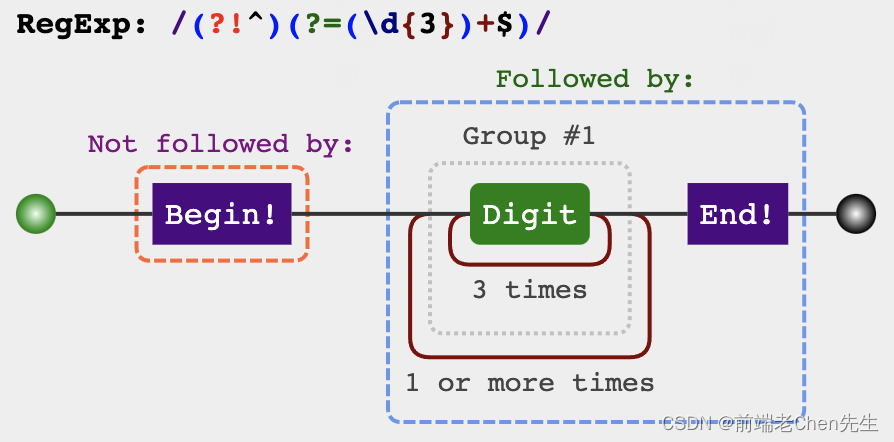
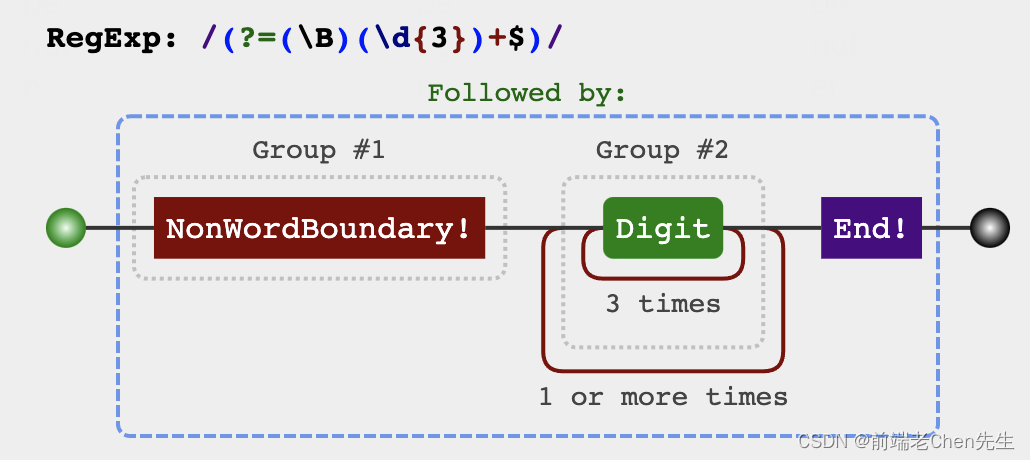
var str = '123456789000'
var reg = /(?=(\B)(\d{3})+$)/g
str.replace(reg,'.')
2、分割:手机号按照 3-4-4 位分割
题目:将手机号18379836654转化为183-7983-6654
整体思路和前面千分位分割类似,
let mobile = '18379836654'
let reg = /(?=(\d{4})+$)/g
console.log(mobile.replace(reg, '-'))
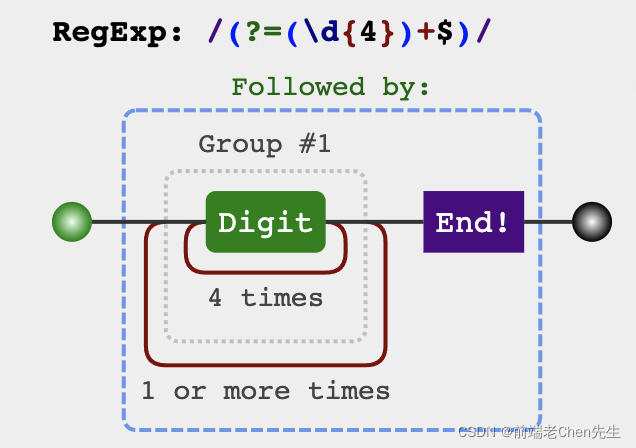
3、分割(扩展):手机号按照 3-4-4 分割
题目:
我们希望在输入手机号码的过程中,边输入边分割,这就需要不断格式化。
123 => 123
1234 => 123-4
12345 => 123-45
123456 => 123-456
1234567 => 123-4567
12345678 => 123-4567-8
123456789 => 123-4567-89
12345678911 => 123-4567-8911
正则结果:
const abc = (mobile) => {
return String(mobile).slice(0,11)
.replace(/(?<=\d{3})\d+/, ($0) => '-' + $0)
.replace(/(?<=[\d-]{8})\d{1,4}/, ($0) => '-' + $0)
}
console.log(abc(13812345678))
分析:
在前面数字金额按照千分位分割的时候,我们使用了(?=p),即 零宽正向先行断言,该断言的作用如下:
exp1(?=exp2):表示查找 exp2前面的 exp1
当时是要保证要寻找的位置后面应该满足某些要求
现在匹配手机号则是按照从前到后的输入顺序,所以这里用(?=p)就不太合适了,例如1234就会变成-1234。我们需要另寻他法, 即可以使用(?<=p),零宽正向后行断言,该断言的作用如下:
(?<=exp2)exp1:表示查找 exp2后面的 exp1
所以,第一步,把第一个-匹配出来
const abc = (mobile) => {
return String(mobile).replace(/(?<=\d{3})\d+/, ($0)=>'-'+$0)
}
console.log(abc(123)) // 123
console.log(abc(1234)) // 123-4
console.log(abc(123456789)) // 123-456789
第二步,把第二个-匹配出来
const abc = (mobile) => {
return String(mobile).slice(0,11)
.replace(/(?<=\d{3})\d+/, ($0) => '-' + $0)
.replace(/(?<=[\d-]{8})\d{1,4}/, ($0) => '-' + $0)
}
console.log(abc(123)) // 123
console.log(abc(1234)) // 123-4
console.log(abc(12345)) // 123-45
console.log(abc(123456)) // 123-456
console.log(abc(1234567)) // 123-4567
console.log(abc(12345678)) // 123-4567-8
console.log(abc(123456789)) // 123-4567-89
console.log(abc(12345678911)) // 123-4567-8911
3、字符截取
1、截取:获取 url 中?后的query参数
题目:
- 指定参数名称,返回该参数的值 或者 空字符串
- 不指定参数名称,返回全部的参数对象 或者 {}
- 如果存在多个同名参数,则返回数组
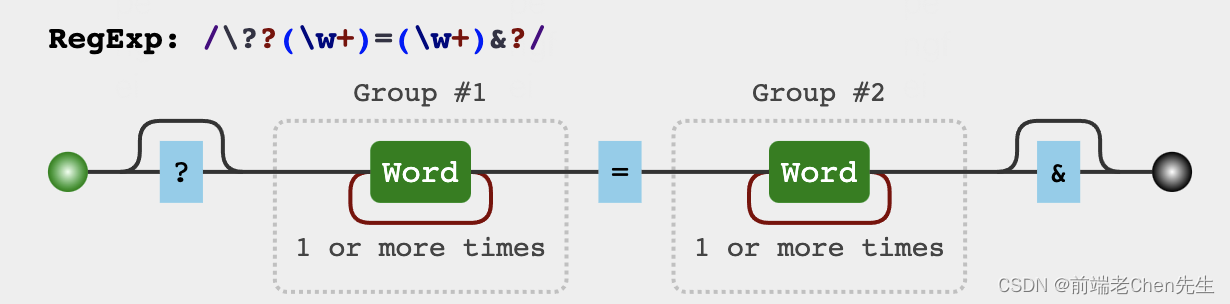
function getUrlParam(url, key) {
var arr = {};
url.replace(/\??(\w+)=(\w+)&?/g, function(match, matchKey, matchValue) {
if (!arr[matchKey]) {
arr[matchKey] = matchValue;
} else {
var temp = arr[matchKey];
arr[matchKey] = [].concat(temp, matchValue);
}
});
if (!key) {
return arr;
} else {
for (ele in arr) {
if (ele = key) {
return arr[ele];
}
}
return '';
}
}
getUrlParam('https://www.xxxxx.com/?car=binli&adc=uzi&name=zhanwei&age=41&name=chen&age=24&cityId=100&app=wps')
2、截取:去除字符串首尾的空格符号(即trim函数)
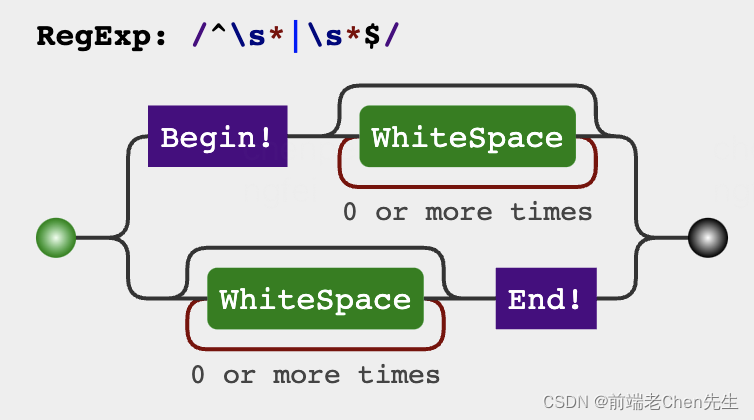
题目:去除字符串首部和尾部的空格符
正则结果:
// 去除空格法
const trim = (str) => {
return str.replace(/^\s*|\s*$/g, '')
}
trim(' 老Chen先生 123 哈哈哈 ') //'老Chen先生 123 哈哈哈'
3、截取:将一串数字中连续且重复的数字提取出来
题目:将有重复的字符提取出来,例如:123237987981028686,提取 [‘23’, ‘798’, ‘86’]
正则结果:
const abc = (str) => {
let arr = []
const reg = /(.+)\1+/g
str.replace(reg, ($0, $1) => {
$1 && arr.push($1)
})
return arr
}
console.log(abc('123237987981028686'))
//['23', '798', '86']
其中,三次的$0和$1分别是:
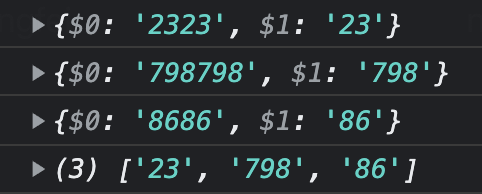
分析:
题目中有几个关键信息:
- 连续重复的字符
- 长度是不限的(如23、45是两位、6是一位)
那什么是连续重复呢?
11是连续重复、22也是连续重复、111当然也是。也就是说某些字符X之后一定也是跟着X,就叫连续重复。如果很明确知道X是就是1,那么/11+/也就可以匹配了,但关键是这里的X是不明确的,怎么办呢?
使用反向引用的正则知识可以很方便解决这个问题。
第一步:写出表示有一个重复字符的正则
// 这里的X可用.来表示,即所有的字符,并用括号进行引用,紧跟着反向应用\1,也就是体现了连续重复的意思啦
let repeatRe = /(.)\1/
console.log(repeatRe.test('11')) // true
console.log(repeatRe.test('22')) // true
console.log(repeatRe.test('333')) // true
console.log(repeatRe.test('123')) // false
第二步:写出表示有n个重复字符的正则
注意:因为并不确定是要匹配11还是45 ,45所以括号内需要用量词+来体现n个重复字符,而反向引用本身也可以是大于一个的,例如 45 45 45
let repeatRe = /(.+)\1+/
console.log(repeatRe.test('11')) // true
console.log(repeatRe.test('22')) // true
console.log(repeatRe.test('333')) // true
console.log(repeatRe.test('454545')) // true
console.log(repeatRe.test('124')) // false
第三步:提取连续重复的字符
const abc = (str) => {
let arr = []
const reg = /(.+)\1+/g
str.replace(reg, ($0, $1) => {
$1 && arr.push($1)
})
return arr
}
console.log(abc('123237987981028686'))
//['23', '798', '86']
4、字符转换
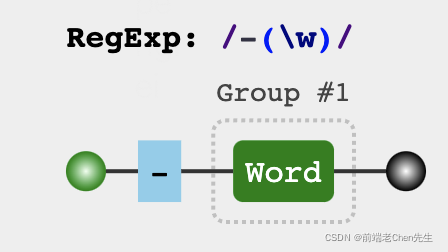
1、转换:将字符串 - 转为 驼峰
题目:the-first-name 变成 theFirstName
var str = "the-first-name"
var reg = /-(\w)/g
str.replace(reg,($,$1)=>{
return $1.toUpperCase()
})
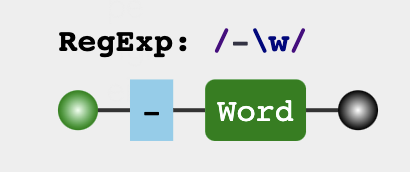
或
var str = "get-element-by-id"
var reg = /-\w/g
str.replace(reg,($)=>{
return $.slice(1).toUpperCase()
})
2、转换:字符串aaabbbbcccc变成abc
var str = 'aaaaaaaaabbbbbbbbcccccc'
var reg = /(\w)\1*/g
console.log(str.replace(reg,'$1'))

3、转换:将数字替换成汉字
var str = '20171001';
var arr = ["零","壹","贰","叁","肆","伍","陆","柒","捌","玖"];
str = str.replace(/\d/g,function () {
var num = arguments[0]; // 把捕获的内容,作为数组的下标
return arr[num];
});
console.log(str); //贰零壹柒壹零零壹
4、转换:HTML转义
前提:防止XSS攻击的方式之一就是做HTML转义,转义规则如下,要求将对应字符转换成等值的实体。而反转义则是将转义后的实体转换为对应的字符
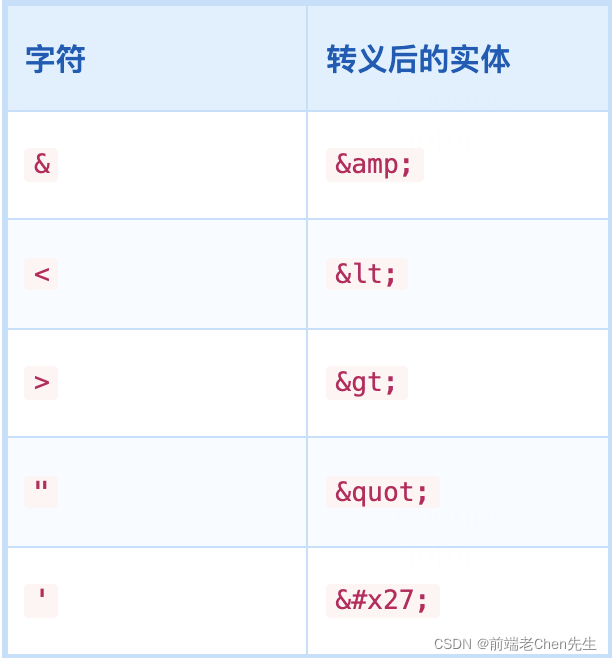
正则结果:
var reg = /[&<>"']/g
var obj = {
'&': 'amp',
'<': 'lt',
'>': 'gt',
'"': 'quot',
"'": '#39'
}
var str = '<div>哈哈123<p>里面字符</p></div>'
str.replace(reg, ($0) =>{
console.log('$0',$0)
return `&${obj[$0]}`
})
$0 <
$0 >
$0 "
$0 "
$0 <
$0 >
'<div>大家好,我是"帅哥"</div>'
(注意:类似这种某个字符可能是多种情况之一的时候,我们一般会使用字符组来做 ,动态的改变,即[&<>"'])
本博客参考:














 1957
1957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









