







文章目录
@article{ilyas2019adversarial,
title={Adversarial Examples Are Not Bugs, They Are Features},
author={Ilyas, Andrew and Santurkar, Shibani and Tsipras, Dimitris and Engstrom, Logan and Tran, Brandon and Madry, Aleksander},
pages={125–136},
year={2019}}
概
作者认为, 标准训练方法, 由于既能学到稳定的特征和不稳定的特征, 而导致模型不稳定. 作者通过将数据集分解成稳定和非稳定数据来验证其猜想, 并利用高斯分布作为一特例举例.
主要内容
本文从二分类模型入手.
符号说明及部分定义
(
x
,
y
)
∈
X
×
{
±
1
}
(x,y) \in \mathcal{X} \times \{\pm 1\}
(x,y)∈X×{±1}: 样本和标签;
C
:
X
→
{
±
1
}
C:\mathcal{X} \rightarrow \{\pm 1\}
C:X→{±1}: 分类器;
f
:
X
→
R
f:\mathcal{X} \rightarrow \mathbb{R}
f:X→R : 特征;
F
=
{
f
}
\mathcal{F}=\{f\}
F={f}: 特征集合;
注: 假设
E
(
x
,
y
)
∼
D
[
f
(
x
)
]
=
0
\mathbb{E}_{(x,y) \sim \mathcal{D}}[f(x)]=0
E(x,y)∼D[f(x)]=0,
E
(
x
,
y
)
∼
D
[
f
(
x
)
2
]
=
1
\mathbb{E}_{(x,y) \sim \mathcal{D}}[f(x)^2]=1
E(x,y)∼D[f(x)2]=1.
注: 在深度学习中,
C
C
C可以理解为
C
(
x
)
=
s
g
n
(
b
+
∑
f
∈
F
C
w
f
⋅
f
(
x
)
)
.
C(x) = \mathrm{sgn} \big( b+ \sum_{f \in F_C} w_f \cdot f(x) \big ).
C(x)=sgn(b+f∈FC∑wf⋅f(x)).
ρ \rho ρ可用特征
满足
E
(
x
,
y
)
∼
D
[
y
⋅
f
(
x
)
]
≥
ρ
>
0
,
(1)
\tag{1} \mathbb{E}_{(x,y) \sim \mathcal{D}}[y \cdot f(x)] \ge \rho >0,
E(x,y)∼D[y⋅f(x)]≥ρ>0,(1)
并记
ρ
D
(
f
)
\rho_{\mathcal{D}}(f)
ρD(f)为最大的
ρ
\rho
ρ.
γ \gamma γ稳定可用特征
若
f
f
f
ρ
\rho
ρ可用, 且对于给定的摄动集合
Δ
\Delta
Δ
E
(
x
,
y
)
∼
D
[
inf
δ
∈
Δ
(
x
)
y
⋅
f
(
x
+
δ
)
]
≥
γ
>
0
,
(2)
\tag{2} \mathbb{E}_{(x, y) \sim \mathcal{D}} [\inf_{\delta \in \Delta(x)} y \cdot f(x+ \delta)] \ge \gamma > 0,
E(x,y)∼D[δ∈Δ(x)infy⋅f(x+δ)]≥γ>0,(2)
则
f
f
f 为
γ
\gamma
γ稳定可用特征.
可用不稳定特征
即对于 f f f, ρ D ( f ) > 0 \rho_{\mathcal{D}}(f) >0 ρD(f)>0, 但是不存在 γ > 0 \gamma >0 γ>0使得(2)式满足.
标准(standard)训练
即最小化期望损失(在实际中为经验风险):
E
(
x
,
y
)
∼
D
[
L
θ
(
x
,
y
)
]
,
(3)
\tag{3} \mathbb{E}_{(x,y) \sim \mathcal{D}} [\mathcal{L}_{\theta} (x, y)],
E(x,y)∼D[Lθ(x,y)],(3)
L
θ
\mathcal{L}_{\theta}
Lθ的取法多样, 比如
L
θ
(
x
,
y
)
=
−
[
y
⋅
(
b
+
∑
f
∈
F
C
w
f
⋅
f
(
x
)
)
]
.
\mathcal{L}_{\theta}(x, y) = - [y \cdot \big( b+ \sum_{f \in F_C} w_f \cdot f(x) \big )].
Lθ(x,y)=−[y⋅(b+f∈FC∑wf⋅f(x))].
稳定(robust)训练
E ( x , y ) ∼ D [ max δ ∈ Δ ( x ) L θ ( x + δ , y ) ] . (4) \tag{4} \mathbb{E}_{(x, y) \sim \mathcal{D}} [\max_{\delta \in \Delta(x)} \mathcal{L}_{\theta} (x+\delta, y)]. E(x,y)∼D[δ∈Δ(x)maxLθ(x+δ,y)].(4)
分离出稳定数据
何为稳定数据? 即在此数据上, 利用标准的训练方式训练得到的模型能够在一定程度上免疫攻击. 如果能从普通的数据中分离出稳定数据和不稳定数据, 说明上面定义的稳定和非稳特征的存在性.
首先假设
C
C
C是一个稳定模型(可通过PGD训练近似生成), 则
D
^
R
\hat{D}_{R}
D^R应当满足
E
(
x
,
y
)
∼
D
^
R
[
f
(
x
)
⋅
y
]
=
{
E
(
x
,
y
)
∼
D
[
f
(
x
)
⋅
y
]
i
f
f
∈
F
C
,
0
o
t
h
e
r
w
i
s
e
.
(5)
\tag{5} \mathbb{E}_{(x, y) \sim \hat{D}_{R}}[f(x) \cdot y] = \left \{ \begin{array}{ll} \mathbb{E}_{(x, y) \sim D}[f(x) \cdot y] & if \: f \in F_C, \\ 0 & otherwise. \end{array} \right.
E(x,y)∼D^R[f(x)⋅y]={E(x,y)∼D[f(x)⋅y]0iff∈FC,otherwise.(5)
为了满足第一条, 需要
min
x
r
∥
g
(
x
r
)
−
g
(
x
)
∥
2
,
(6)
\tag{6} \min_{x_r} \quad \|g(x_r) - g(x)\|_2,
xrmin∥g(xr)−g(x)∥2,(6)
其中
g
g
g为将
x
x
x映射到表示层(representation layer)的映射?
为了满足第二条, 在选择 x r x_r xr的初始值的时候, 从 D \mathcal{D} D中随机采样 x ′ x' x′, 以保证 x ′ x' x′和 y y y没有关系, 则 E ( x , y ) ∼ D [ f ( x ′ ) ⋅ y ] = E ( x , y ) ∼ D [ f ( x ′ ) ] ⋅ E ( x , y ) ∼ D [ y ] = 0 \mathbb{E}_{(x, y) \sim D}[f(x') \cdot y] = \mathbb{E}_{(x, y) \sim D}[f(x')] \cdot \mathbb{E}_{(x, y) \sim D}[y] = 0 E(x,y)∼D[f(x′)⋅y]=E(x,y)∼D[f(x′)]⋅E(x,y)∼D[y]=0.

分离出不稳定数据
分离出不稳定数据所需要的是标准的模型
C
C
C, 且
x
a
d
v
=
arg
min
∥
x
′
−
x
∥
≤
ϵ
L
C
(
x
′
,
t
)
,
(7)
\tag{7} x_{adv} = \arg \min_{\|x'-x\| \le \epsilon} L_C(x', t),
xadv=arg∥x′−x∥≤ϵminLC(x′,t),(7)
其中
L
C
L_C
LC是认为给定的损失函数(比如:交叉熵), 而
t
t
t是通过某种方式给定的标签, 且
C
(
x
)
=
y
C(x) = y
C(x)=y,
C
(
x
′
)
=
t
C(x')=t
C(x′)=t.
既然摄动很小, 且
x
a
d
v
x_{adv}
xadv的标签为
t
t
t, 所以此时
F
C
F_C
FC中既有稳定特征, 又有不稳定特征.
t t t随机选取
此时稳定性特征和 t t t不相关, 故其可用度应当为0, 而不稳定特征可用度大于0, 故
E ( x , y ) ∼ D ^ r a n d [ f ( x ) ⋅ y ] { . > 0 i f f n o n − r o b u s t l y u s e f u l , ≈ 0 o t h e r w i s e . (8) \tag{8} \mathbb{E}_{(x, y) \sim \hat{D}_{rand}}[f(x) \cdot y] \left \{ \begin{array}{ll} .> 0 & if \: f \: non-robustly \: useful, \\ \approx 0 & otherwise. \end{array} \right. E(x,y)∼D^rand[f(x)⋅y]{.>0≈0iffnon−robustlyuseful,otherwise.(8)
t t t选取依赖于 y y y
E ( x , y ) ∼ D ^ d e t [ f ( x ) ⋅ y ] = { . > 0 i f f n o n − r o b u s t l y u s e f u l < 0 i f f r o b u s t l y u s e f u l ∈ R o t h e r w i s e . (9) \tag{9} \mathbb{E}_{(x, y) \sim \hat{D}_{det}}[f(x) \cdot y] = \left \{ \begin{array}{ll} .> 0 & if \: f \: non-robustly \: useful \\ < 0 & if \: f\: robustly \: useful \\ \in \mathbb{R} & otherwise. \end{array} \right. E(x,y)∼D^det[f(x)⋅y]=⎩⎨⎧.>0<0∈Riffnon−robustlyusefuliffrobustlyusefulotherwise.(9)

比较重要的实验
1
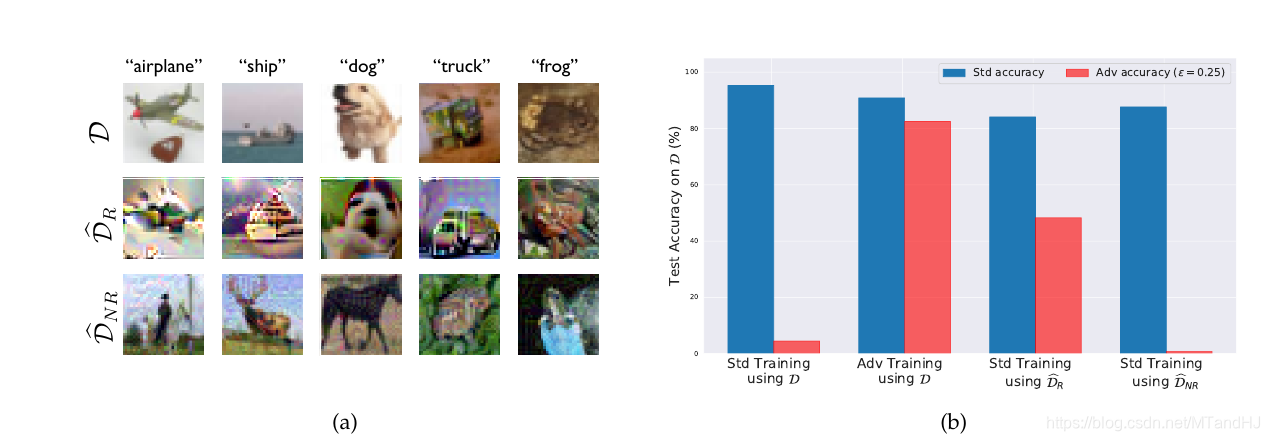
上面左图从上到下分别是标准数据, 稳定数据和不稳定数据, 右图进行了四组不同的实验:
- 在标准数据上标准训练并对其攻击
- 在标准数据上稳定训练并对其攻击
- 在稳定数据上标准训练并对其攻击
- 在不稳定数据上标准训练并对其攻击
不难发现, 在稳定数据上标准训练能够一定程度上免疫攻击, 而在不稳定数据上标准训练, 能够逼近在标准数据上标准训练的结果, 而其对攻击的免疫程度也正如我们所想的一塌糊涂.
这些实验可以说明, 稳定特征和不稳定特征是存在的, 标准训练由于最大限度地追求准确度, 所以其对二类特征一视同仁, 全盘接受, 这导致了不稳定.
迁移性
adversarial attacks的一个很明显的特征便是迁移性, 稳定特征和不稳定特征能够解释这一点, 既然数据相同, 不同结构的网络会从中提取出类似的不稳定特征.
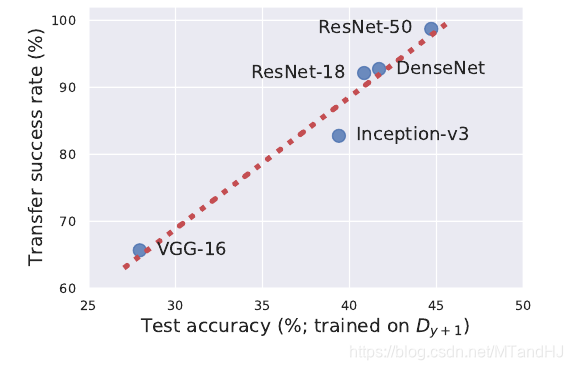
利用从ResNet-50中提取的不稳定数据, 提供给别的模型训练, 可以验证迁移性.
理论分析
作者通过一个正态分布的例子来告诉我们稳定特征和不稳定特征的存在和作用.
注: 下面涉及到的 Σ , Σ ∗ \Sigma, \Sigma_* Σ,Σ∗均为对角阵.
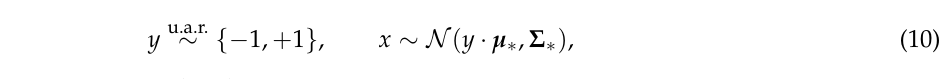
标准训练的目标是通过极大似然估计
Θ
=
(
μ
,
Σ
)
\Theta=(\mu, \Sigma)
Θ=(μ,Σ),
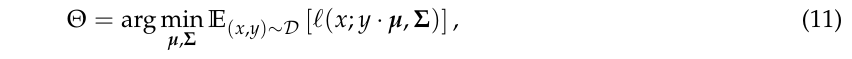
其中
ℓ
\ell
ℓ为密度函数的
−
log
-\log
−log.
于是,
C
(
x
)
=
s
i
g
n
(
x
T
Σ
−
1
μ
)
.
C(x)= \mathrm{sign}(x^T \Sigma^{-1} \mu).
C(x)=sign(xTΣ−1μ).
注: 无特别约束(11)的最优解即位
μ
∗
,
Σ
∗
\mu_*, \Sigma_*
μ∗,Σ∗.
稳定训练的目标是
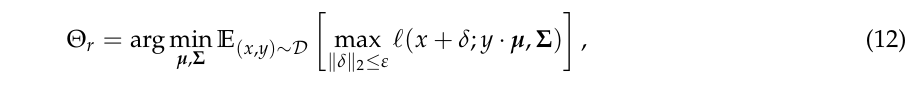
则有以下结论
定理1

注: L ( Θ ) = E ( x , y ) ∼ D [ ℓ ( x , y , μ , Σ ) ] \mathcal{L}(\Theta)=\mathbb{E}_{(x, y) \sim \mathcal{D}}[\ell(x, y,\mu, \Sigma)] L(Θ)=E(x,y)∼D[ℓ(x,y,μ,Σ)], L a d v ( Θ ) \mathcal{L}_{adv}(\Theta) Ladv(Θ)的定义是类似的.
定理2
注意, 此时考虑的问题与上面的不同(定理3同定理2), 为
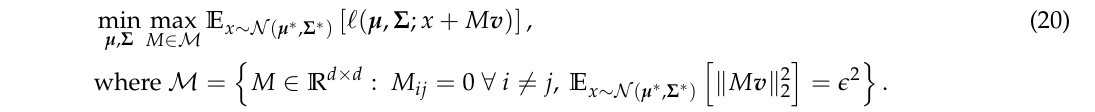

定理3

定理的证明, 这里不贴了, 其中有一个引理的证明很有趣.















 1805
1805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









