







关联式容器:每个元素位置取决于特定的排序准则以及元素值,和插入次序无关。
一、map
map提供一对一(其中第一个称为关键字key,每个关键字只能在map中出现一次,第二个称为该关键字的值value)的数据处理能力,由于这个特性,它完成有可能在我们处理一对一数据的时候,在编程上提供快速通道。map内部自建一颗红黑树(一 种非严格意义上的平衡二叉树),这颗树具有对数据自动排序的功能,所以在map内部所有的数据都是有序的。
二、map的初始化
map <string,int> m;
map <string,int>::iterator it;三、map的大小和容量
- m.size():返回map中元素的个数
- m.max_size():返回最大可允许的map元素数量值
四、map的插入:insert()
- m.insert(pair<T,T>(key, value)) :插入pair数据
- m.insert(map<T,T>::value_type (key, value)):插入value_type数据
- m[key]=value:用数组方式插入数据
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main()
{
map<int, string> mapStudent;
//第一种:用insert函数插入pair数据
mapStudent.insert(pair<int, string>(1, "student_one"));
//第二种:用insert函数插入make_pair数据
mapStudent.insert(make_pair(2, "student_two"));
//第三种:用insert函数插入value_type数据
mapStudent.insert(map<int, string>::value_type (3, "student_three"));
//第四种:用数组方式插入数据
mapStudent[4] = "student_four";
map<int, string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout<<iter->first<<' '<<iter->second<<endl;
}
用insert函数插入数据,当map中有这个关键字时,insert操作是插入数据不了的,但是用数组方式就不同了,它可以覆盖以前该关键字对应的值。我们通过pair的第二个变量来知道是否插入成功,它的第一个变量first返回的是一个map的迭代器,如果插入成功的话第二个变量second应该是true的,否则为false。
五、map的删除:erase()
- m.erase(iterator it):删除map中迭代器指向元素
- m.erase(iterator first,iterator last):删除map中[first,last)中元素
- m.clear():清空map中所有元素
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main()
{
map<int, string> mapStudent;
mapStudent.insert(pair<int, string>(1, "student_one"));
mapStudent.insert(pair<int, string>(2, "student_two"));
mapStudent.insert(pair<int, string>(3, "student_three"));
//如果要删除1,用迭代器删除
map<int, string>::iterator iter;
iter = mapStudent.find(1);
mapStudent.erase(iter);
//如果要删除1,用关键字删除
int n = mapStudent.erase(1);//如果删除了会返回1,否则返回0
//用迭代器,成片的删除
//一下代码把整个map清空
mapStudent.erase( mapStudent.begin(), mapStudent.end() );
//成片删除要注意的是,也是STL的特性,删除区间是一个前闭后开的集合
//自个加上遍历代码,打印输出吧
}
六、map的遍历:借助迭代器或者下标法[]
- m.begin():返回map头指针,指向第一个元素
- m.end():返回map尾指针,指向map最后一个元素的下一个位置
- m.rbegin():反向迭代器,指向最后一个元素
- m.rend():反向迭代器,指向第一个元素之前的位置
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main()
{
map<int, string> mapStudent;
mapStudent.insert(pair<int, string>(1, "student_one"));
mapStudent.insert(pair<int, string>(2, "student_two"));
mapStudent.insert(pair<int, string>(3, "student_three"));
//第一种,利用迭代器
map<int, string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
cout<<iter->first<<' '<<iter->second<<endl;
//第二种,利用反向迭代器
for(iter = mapStudent.rbegin(); iter != mapStudent.rend(); iter++)
cout<<iter->first<<" "<<iter->second<<endl;
//第三种:用数组方式
//此处应注意,应该是 for(int nindex = 1; nindex <= nSize; nindex++)
//而不是 for(int nindex = 0; nindex < nSize; nindex++)
for(int nindex = 1; nindex <= nSize; nindex++)
cout<<mapStudent[nindex]<<endl;
}七、map的查找函数(键)
- m.count():判定关键字是否出现,其缺点是无法定位数据出现位置,返回值只有两个,要么是0,要么是1(出现)
- m.find():定位数据出现位置,它返回的一个迭代器,当数据出现时,它返回数据所在位置的迭代器,如果map中没有要查找的数据,它返回的迭代器等于end函数返回的迭代器。
#include<string>
#include<cstring>
#include<iostream>
#include<queue>
#include<map>
#include<algorithm>
using namespace std;
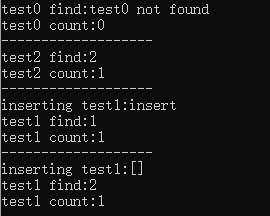
int main(){
map<string,int> test;
test.insert(make_pair("test1",1));//test["test1"]=1
test.insert(make_pair("test2",2));//test["test2"]=2
map<string,int>::iterator it;
it=test.find("test0");
cout<<"test0 find:";
if(it==test.end()){
cout<<"test0 not found"<<endl;
}
else{
cout<<it->second<<endl;
}
cout<<"test0 count:";
cout<<test.count("test0")<<endl;
cout<<"-------------------"<<endl;
cout<<"test2 find:";
it=test.find("test2");
if(it==test.end()){
cout<<"test2 not found"<<endl;
}
else{
cout<<it->second<<endl;
}
cout<<"test2 count:";
cout<<test.count("test2")<<endl;
cout<<"-------------------"<<endl;
cout<<"inserting test1:insert"<<endl;
test.insert(make_pair("test1",2));
cout<<"test1 find:";
it=test.find("test1");
if(it==test.end()){
cout<<"test1 not found"<<endl;
}
else{
cout<<it->second<<endl;
}
cout<<"test1 count:";
cout<<test.count("test1")<<endl;
cout<<"-------------------"<<endl;
cout<<"inserting test1:[]"<<endl;
test["test1"]=2;
cout<<"test1 find:";
it=test.find("test1");
if(it==test.end()){
cout<<"test1 not found"<<endl;
}
else{
cout<<it->second<<endl;
}
cout<<"test1 count:";
cout<<test.count("test1")<<endl;
return 0;
}
八、map的排序函数
- 对有序map中的key排序:如果在有序的map中,key是int或string,它们本身的就是有序的,不用额外的操作。
#include<iostream>
#include<algorithm>
#include<stdio.h>
#include <vector>
#include<string>
#include<map>
#include <functional> // std::greater
using namespace std;
struct CmpByKeyLength {
bool operator()(const string& k1, const string& k2)const {
return k1.length() < k2.length();
}
};
int main()
{
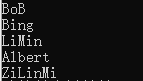
//1、map这里指定less作为其默认比较函数(对象),就是默认按键值升序排列
// map<string, int> name_score_map;
/*Albert
Bing
BoB
LiMin
ZiLinMi*/
// 2、可以自定义,按照键值升序排列,注意加载
// #include <functional> // std::greater
// map<string, int, greater<string>> name_score_map;
//3、按照自定义内容进行排序,比如字符串的长度
map<string, int, CmpByKeyLength> name_score_map;
name_score_map["LiMin"] = 90;
name_score_map["ZiLinMi"] = 79;
name_score_map["BoB"] = 92;
name_score_map.insert(make_pair("Bing", 99));
name_score_map.insert(make_pair("Albert", 86));
map<string, int>::iterator iter;
for ( iter = name_score_map.begin();iter != name_score_map.end();++iter) {
cout << (*iter).first << endl;
}
system("pause");
return 0;
}
- 对有序map中的value排序:把map中的元素放到序列容器(如vector)中,再用sort进行排序。
#include<iostream>
#include<algorithm>
#include<stdio.h>
#include <vector>
#include<string>
#include<map>
#include <functional> // std::greater
using namespace std;
bool cmp(const pair<string, int>& a, const pair<string, int>& b) {
return a.second < b.second;
}
int main()
{
//1、map这里指定less作为其默认比较函数(对象),就是默认按键值升序排列
map<string, int> name_score_map;
name_score_map["LiMin"] = 90;
name_score_map["ZiLinMi"] = 79;
name_score_map["BoB"] = 92;
name_score_map.insert(make_pair("Bing", 99));
name_score_map.insert(make_pair("Albert", 86));
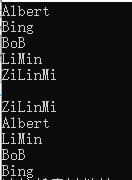
//输出添加的内容
map<string, int>::iterator iter;
for (iter = name_score_map.begin(); iter != name_score_map.end(); ++iter) {
cout << (*iter).first << endl;
}
cout << endl;
// 将map中的内容转存到vector中
vector<pair<string, int>> vec(name_score_map.begin(), name_score_map.end());
//对线性的vector进行排序
sort(vec.begin(), vec.end(), cmp);
for (int i = 0; i < vec.size(); ++i)
cout << vec[i].first << endl;
system("pause");
return 0;
}















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









