









CNN之思考
频域之于CNN泛化性的解释 2020
论文: https://arxiv.org/abs/1905.13545
标题: High Frequency Component Helps Explain the Generalization of Convolutional Neural Networks
作者: Haohan Wang, Xindi Wu, Zeyi Huang, Eric P. Xing
School of Computer Science
Carnegie Mellon University
收录: CVPR 2020
代码: https://github.com/HaohanWang/HFC
关键词:
-
图像可以划分为低频信息(语义信息)和高频信息(边缘或突变),人在标注label时只基于低频信息;

-
在高低频信息分离后,CNN可能会对低频图像进行错误预测,对高频图像进行正确预测。证明CNN训练时可能对两者共同学习;

-
对于同一类别数据,在不同场景下,语义分布应该近乎一致,但高频分布则可能与特定域有关。故CNN的泛化能力与数据分布特性有关;
-
CNN训练时,会先拟合低频信息,在loss值达到瓶颈时,会进一步尝试拟合高频信息;

-
高频信息包含与数据分布特性相关的成分,及与数据无关的噪声。 但CNN无法针对性的训练,故如果训练时噪声引入过多则会出现过拟合,导致泛化能力下降;
-
早停预防过拟合的能力,可能在于预防模型利用高频信息中的噪声进行训练;
-
大batch size训练时,会同时考虑更多的非噪声的同分布高频成分,从而缩小train和test的gap;
-
mix-up缩小了train和test的gap,是因为混淆了低频信息,从而鼓励CNN尽可能多去捕获高频信息;
-
加入对抗样本会快速降低CNN精度。因为对抗样本可能改变了高频分布(人眼无法感知),train阶段实际学到的高频分布和对抗样本的高频分布不一致,故预测错误;

-
Vanilla指无BN的模型。BN优势之一是通过归一化来对齐不同信号的分布差异,让模型更容易获取高频成分。且由于对齐效应,大部分捕获的是有益高频成分,从而加快收敛、提高泛化能力;

-
暂无较好方式去除高频信息中的噪声,目前唯一能尝试用合适的半径阈值 r 去除部分高频信息,预防噪声干扰。同时test也要进行相应高频过滤,或许能提高泛化能力;
-
对抗鲁棒性较好的模型卷积核更加平滑,可以利用该特性稍微提高CNN的鲁棒性。
参考文档:https://mp.weixin.qq.com/s/jdy07LGbChMuSuGjX5qOJg
目标检测
R-CNN
Fast R-CNN
Faster R-CNN
SSD
YOLO
YOLOv2
YOLOv3
YOLOv4 2020
YOLOv4:You Only Look Once v4
论文: https://arxiv.org/abs/2004.10934
标题: YOLOv4: Optimal Speed and Accuracy of Object Detection
作者: Alexey Bochkovskiy∗
Chien-Yao Wang∗
Institute of Information Science
Academia Sinica, Taiwan
Hong-Yuan Mark Liao
Institute of Information Science
Academia Sinica, Taiwan
代码: https://github.com/AlexeyAB/darknet
关键词:
- 对多种网络结构、训练技巧的组合进行了充分实验,对在图像分类和目标检测的作用做了对比;
- 作者目标是让使用者可以轻松使用GPU训练和测试实时的、高质量的结果,在Darknet框架中(如上代码链接)可以轻松使用;
- 对目标检测模型的架构进行划分,含Input、Backbone、Neck、Head,结构见下截图;
- Bag-of-Freebies(BoF),不增加推理损耗而提高模型精度的技巧。文中列举了:
- 数据增强;
- 分类loss;
- 回归loss。
- Bag-of-Spacials(BoS),增加少量推理损耗而提高精度的技巧。文中列举了:
- 提高感受野;
- 引入注意力机制;
- 提高特征聚合能力;
- 激活函数;
- 后处理方法。
- 目标检测的模型需要:
- 更高的输入分辨率,以检测小目标;
- 更大的感受野,即更多的层,以cover更高的分辨率;
- 更多的参数,以适配单一图片下不同分辨率的目标。
- 引入了新的数据增强方式:Mosaic、Self-Adversarial Training (SAT):
- Mosaic混合四张image作为一张image,提高了图片的variance,对BN更有利;
- SAT包含两个前向、后向过程。第一阶段,并不更新网络权重,而是修改原始图像,在图像中产生原本没有的物体,从而达到对自身的对抗攻击。在第二阶段,以正常的方式用修改后的图像进行训练。
- 提出了修改版SAM、修改版PAN、Cross mini-Batch Normalization (CmBN)
- CmBN和BN相比,BN每个mini-batch只计算当前的Mean和Variance,CmBN会计算当前batch的;
- 而和CBN相比,CBN无论batch,都会计算前4个mini-batch的Mean和Variance,并且每个mini-batch都会更新Bias、Scale、W,CBN则聚焦当前batch的Mean和Variance,且每个batch更新一次Bias、Scale、W(见下图解);
- 修改版SAM从空间维度的注意力机制改为像素维度的注意力机制(见下图解);
- 修改版PAN从addition改为connection(见下图解)。
- YOLOv4结构上:
- backbone选择CSPDarknet53,因拥有更大的感受野及更低的时延;
- SPP模块及PANet路径聚合neck;
- 延续YOLOv3的head结构。
- backbone的BoF:CutMix、Mosaic数据增强、DropBlock正则化、Class label smoothing;
- backbone的BoS:Mish激活函数、Cross-stage partial connections (CSP)、Multiinput weighted residual connections (MiWRC);
- detector的BoF:CIoU loss、CmBN、DropBlock、Mosaic、SAT、Eliminate grid sensitivity、多anchor对应单目标、余弦退火策略( Cosine annealing scheduler)、最优超参数( Optimal hyperparameters)、随机训练图像尺寸(Random training shapes);
- detector的BoS:Mish、SPP、SAM、PAN、DIoU-NMS;
- 作者对各种各种BoF和BoS进行了横向对比、消融实验,在落地到自己项目时,可以作为参考。






小目标检测
COCO小目标检测的数据增强 2019
论文: https://arxiv.org/abs/1902.07296
标题: Augmentation for small object detection
作者: Mate Kisantal, Zbigniew Wojna, Jakub Murawski, Jacek Naruniec, Kyunghyun Cho

关键词:
- 针对小目标图片较少的问题,使用过采样OverSampling的策略,
- 针对一张图片中小目标较少的问题,在图片中用分割的Mask(COCO数据集有分割Mask)进行裁剪复制,添加旋转、缩放等变换后,在不遮挡其余目标的前提下粘贴;
策略2能让Anchor-base模型有更多的正样本 - 以上两种策略会对其他尺寸(尤其大尺寸)样本造成负面影响,故要衡量两者的重要性;
- 作者对以上两种策略作了各种对比,包括:过采样比例、过采样与粘贴的组合方式、小目标粘贴的数量、对几种(一种、几种、全部)小目标粘贴、粘贴是否重叠以及是否边缘模糊。


轻量型算法
MobileNet
ShuffleNet
SqueezeNet
MixNet
GhostNet
模型加速
卷积核剪枝 2017
论文: https://arxiv.org/abs/1608.08710
标题: Pruning Filters for Efficient ConvNets
作者: Hao Li∗
University of Maryland
Asim Kadav
NEC Labs America
Igor Durdanovic
NEC Labs America
Hanan Samet†
University of Maryland
Hans Peter Graf
NEC Labs America
收录: ICLR 2017
无官方代码
关键词:
- 假设 F i , j F_{i, j} Fi,j是基于第 i i i层特征图生成第 i + 1 i+1 i+1层特征图的第 j j j个通道的卷积核,裁剪该卷积核会另第 i + 1 i+1 i+1层特征图的通道数减1。从而减少 i i i到 i + 1 i+1 i+1一个卷积核的计算量,以及 i + 1 i+1 i+1到 i + 2 i+2 i+2所有卷积核对应这个被减通道的计算量;
- 与其他范数相比,L1范数对激活函数过后的特征图的裁剪效果更好;
- 裁剪第
i
i
i层特征图的m个卷积核的流程:
- 计算每个卷积核所有权重绝对值的和 s j s_j sj;
- 对该层所有 s j s_j sj排序;
- 删除 s j s_j sj最小的m个卷积核,及其对应生成的第 i + 1 i+1 i+1层的特征图,还有第 i + 1 i+1 i+1层的所有卷积核对应这m个通道的通道;
- 创建新的第 i i i和 i + 1 i+1 i+1层的kernel matrix,并把剩余权重赋值。
- 这种按比例或按照排名的裁剪策略,比基于绝对值阈值来一刀切的效果要好,因为后者很难把握threshold的大小,且容易生成稀疏卷积核,难以进行加速;
- figure 2很重要。(b)里随着剪枝百分比增加,曲线依旧平滑的卷积层,就对应(a)里斜率最平滑的层,这些兜是对剪枝敏感度较低的层。
- 在(a)里,对于一条曲线,是对同一层所有核L1-sum并排序后,随着横坐标往右,从大到小遍历所有核的L1-sum值。纵坐标是除以最大值后归一化的值,可以对比出每一层的权值突变程度。
- 综上,个人理解是如果这一层所有卷积核的L1-sum值的变化比较平缓,慢慢从1~0,曲线比较平滑,则该层对剪枝的敏感度更低。反之亦然;
- 且相邻相同feature map大小的层对剪枝的敏感度相似,故给予相同的剪枝率;
- 整体裁剪是比逐层裁剪更实际的,除了在时间损耗低外,还能给模型一个全局的视野,或许能提高鲁棒性;而且对于复杂网络也是必要的,如ResNet的残差模块如果剪了第二层,会导致额外的剪枝;
- 整体剪枝时有两种策略,实验证明后者更优(见下图figure 3):
- 虽然第 i i i层会受到上一层 i − 1 i-1 i−1的影响,但我们忽略其影响,即每一层都独立计算;
- 贪心策略: 考虑上一层的影响,即 i − 1 i-1 i−1层裁剪卷积核导致 i i i层被剪枝的通道,在计算 i i i层时对其忽略。
- 对于残差结构,要考虑到模块结尾相加时尺寸的一致性。因shortcut比残差卷积更重要,故残差的第二层卷积的裁剪取决于shortcut的通道重要性。shortcut的通道重要性则通过增加 1 x 1卷积核来体现(见下图figure 4);
- 不太敏感的层可以一次性裁剪后retrain,敏感层或大面积裁剪层可能迭代裁剪retrain会更好,但更耗时;
- 重新训练剪枝网络比retrain效果差,说明小容量网络训练更难;
- 实验表明,裁剪每个block(相同feature size内)的第一层的影响最大;
- 作者对相同block不同layer、不同裁剪策略(随机、裁剪最大)、不同比对指标(L1等)做了比较,后面有实际需要可跳论文详细参照。




TensorRT INT8量化 2017
材料: https://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
标题: 8-bit Inference with TensorRT
作者: Szymon Migacz, NVIDIA
关键词:
-
这是一种训练后的量化方式,并非训练时量化方式;
-
原本通过scale_factor和bias进行FP32和INT8之间的映射,但经过试验表明与性价比需求,bias可移除;




-
量化的方式,或者说从FP32映射至INT8的方式有两种:
- 非饱和方式(No saturation)

- 饱和方式(saturation)

- 非饱和方式(No saturation)
-
非饱和方式是根据FP32的最大、小值对应127、-127映射到INT8的范围中;
-
饱和方式是采用± ∣ T ∣ |T| ∣T∣作为阈值,超出阈值则映射至边界,阈值内则映射至范围内;
-
量化操作其实要对数据(即本层的输入Tensor或上层的输出Tensor,即截图中所述的Activations)和权重进行,实验表明:对权重用非饱和、对数据进行饱和量化效果最佳;
-
饱和量化的阈值选取很重要,也需要有指标显式地衡量阈值的优劣。这里用的是KL散度,来表明把FP32编码为INT8的损失;

-
以FP32为基准,这是无损编码,称信息熵,编码至INT8后的编码长度为交叉熵,KL散度也即相对熵为两者的差值,故越小越好;
-
具体做法是对训练后的FP32模型,提供一组校准数据集,数据最好来自验证集且分布均匀。遍历各种阈值下的激活值(Activations)分布,以KL散度选取最优的阈值。最终以这个阈值进行量化,记录对应的scale factor;
参考文档:
https://arleyzhang.github.io/articles/923e2c40/
目标跟踪
数据集
VOT
VOT: Visual Object Tracking
官网: https://www.votchallenge.net/
评价指标(2020):
- Accuracy
准确率 - Robustness
鲁棒性,也是错误率 - EAO(Expected Average Overlap)
综合了Accuracy和Robustness的评价指标
评价指标每年都不太一样,可参考官方对当年Challenge的公告。
OTB
OTB: Object Tracking Benchmark
官网:http://cvlab.hanyang.ac.kr/tracker_benchmark/index.html
GOTURN 2016
GOTURN:Generic Object Tracking Using Regression Networks
官网: https://davheld.github.io/GOTURN/GOTURN.html
论文: https://davheld.github.io/GOTURN/GOTURN.pdf
标题: Learning to Track at 100 FPS with Deep
Regression Networks
作者: David Held, Sebastian Thrun, Silvio Savarese
Department of Computer Science
Stanford University
{davheld,thrun,ssilvio}@cs.stanford.edu
收录: European Conference on Computer Vision (ECCV), 2016 (In press)
代码: https://github.com/davheld/GOTURN
关键词:
- 离线学习
- 单目标跟踪
- Regression任务:根据上一frame的crop region,在当前frame的search region中regress Bounding Box
- 根据目标的移动速度和fps,可适当调节crop size
- 除了基于video训练,还基于形变后的image训练,以扩大训练集
- test时需初始化Bounding Box




MDNet 2015
MDNet: Multi-Domain Convolutional Neural Network Tracker
官网: http://cvlab.postech.ac.kr/research/mdnet/
论文: https://arxiv.org/abs/1510.07945
标题: Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
作者: Hyeonseob Nam Bohyung Han
Dept. of Computer Science and Engineering, POSTECH, Korea
{namhs09, bhhan}@postech.ac.kr
竞赛: The Winner of The VOT2015 Challenge
代码: https://github.com/HyeonseobNam/MDNet
关键词:
- 单目标跟踪,需初始化Bounding Box
- 由CNN,Fully Connection组成
- 二分类任务:fc6为二分类器,判断候选框为目标或背景
- 离线学习进行预训练,在线学习进行fine-tune
- 离线学习:相同backbone(CNN+fc4+fc5),以及k个fc6,由k个视频训练,以学习通用的特征层(backbone),和特定的分类层(fc6)
- 在线学习:新建fc6,frozen CNN部分,在线fine-tune fc4-fc6
- 在线学习结合long-term updates和short-term updates策略进行更新
- Hard Minibatch Mining:参考hard negative mining采样策略组合batch
- 仅在在线学习第一帧进行regressor训练,降低损耗



ROLO 2016
ROLO: Recurrent YOLO for object tracking
官网: http://guanghan.info/projects/ROLO/
论文: https://arxiv.org/abs/1607.05781
标题: Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
作者: Guanghan Ning∗
, Zhi Zhang, Chen Huang, Zhihai He
Department of Electrical and Computer Engineering
University of Missouri
Columbia, MO 65201
{gnxr9, zzbhf, chenhuang, hezhi}@mail.missouri.edu
Xiaobo Ren, Haohong Wang
TCL Research America
{renxiaobo, haohong.wang}@tcl.com
代码: https://github.com/Guanghan/ROLO
翻译: https://blog.csdn.net/MacKendy/article/details/110040151
关键词:
- YOLO + LSTM
- 单目标跟踪,无需初始化Bounding Box,离线学习
- Regression任务
- 按原文所述:效果比传统跟踪算法(如YOLO+卡尔曼滤波)要好,尤其在特殊场合鲁棒性更强


SORT 2016
SORT: Simple Online and Realtime Tracking
官网:
论文: https://arxiv.org/abs/1602.00763
标题: Simple Online and Realtime Tracking
作者: Alex Bewley†, Zongyuan Ge†, Lionel Ott⋄, Fabio Ramos⋄, Ben Upcroft†
Queensland University of Technology†, University of Sydney⋄
代码: https://github.com/abewley/sort
翻译: https://blog.csdn.net/MacKendy/article/details/110118796
关键词:
- 在线跟踪,离线学习,多目标跟踪,无需初始化Bounding Box
- 能适应视频中增加或减少目标
- Detection + Kalman Filter + Hungarian algorithm
- 跟踪性能取决于Detector性能,可根据跟踪任务选择合适的Detector及对应训练集
- Kalman Filter跟踪目标Bounding Box的[u, v, s, r],并更新[u, v, s],分别是目标中心的坐标、尺寸、纵横比
- 基于IoU距离计算cost矩阵,通过Hungarian算法assign目标
DeepSORT 2017
DeepSORT:
官网:
论文: https://arxiv.org/abs/1703.07402
标题:
作者:
代码: https://github.com/nwojke/deep_sort
翻译:
动作识别
Two-Stream Conv 2014
论文: https://arxiv.org/abs/1406.2199
标题: Two-Stream Convolutional Networks for Action Recognition in Videos
作者: Karen Simonyan
Andrew Zisserman
Visual Geometry Group, University of Oxford
收录: NIPS 2014
关键词:
- 针对视频信息,划分为空间(Spatial)域和时间(Temporal)域。前者可直观通过单帧判断目标的动作信息,后者则在时序上弥补单帧所无法分别的信息(如开门和关门);
- 基于上述直觉,使用了两个卷积网络,分别为Spatial stream ConvNet、Temporal stream ConvNet(见后图Figure 1);
- 两个网络的fusion方式有二:两者取平均、训练分类器进行权重划分;
- Spatial stream基于ImageNet预训练;
- Temporal stream把Optical flow(光流)作为输入,如后图Figure 2对光流的可视化,a、b为相邻两帧,c为蓝色框的光流可视化,d、e分别为x、y方向的displacement vector可视化(即Temporal的输入);
- 对于L帧视频,每帧间有
d
x
d_x
dx、
d
y
d_y
dy即2L个通道,作者提出多种计算方式:
- Optical flow stacking。每个点表示帧 t 移动到帧 t+1 的对应点。如下图Figure 3左,多个帧每次都在相同位置采样,不跨帧进行考虑(公式见下式1);
- Trajectory stacking。每个点表示沿轨迹的位移,如下图Figure 3右;
- Bi-directional optical flow。双向光流,即当前帧后L/2正向和帧前L/2反向堆叠,通道数为2L不变。且可与前两种方法共同使用;
- Mean flow subtraction。光流对于正向和反向运动是有表示作用的,但摄像机的移动可能导致整体画面的方向偏移,故需要归一化来抵消整体移动。这里通过减每层均值来实现;
- 基于多任务训练进行学习,针对不同训练集,模型后接对应的Softmax,一同对骨干网络进行训练,以弥补Temporal stream数据不足的情况(Spatial stream可ImageNet预训练);



Optical flow stacking:
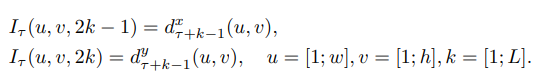
Trajectory stacking:
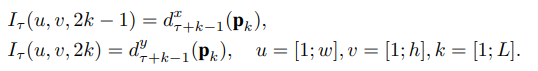
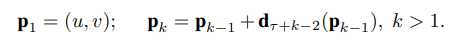
TSN 2016
TSN: Temporal Segment Networks
论文: https://arxiv.org/abs/1608.00859
标题: Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
作者: Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, Luc Van Gool
Computer Vision Lab, ETH Zurich, Switzerland
Department of Information Engineering, The Chinese University of Hong Kong
Shenzhen Institutes of Advanced Technology, CAS, China
收录: ECCV 2016
代码: https://github.com/yjxiong/temporal-segment-networks
https://github.com/yjxiong/caffe
关键词:
- Two-stream(双流)模型是对视频做密集采样,难以获取长跨度的视频信息,故在此基础上改用稀疏采样方式;
- 对视频进行切片,如下图Fig 1切成K=3片,每片中随机选择snippet(小片段),再对每个snippet输入双流网络中,最后对K个snippet的结果进行融合。可以理解为长视频中稀疏采样,每个稀疏片段中再密集采样;
- 【切片-双流-融合】的流程可表示为下公式1, T k T_k Tk就是第k个片段里的snippet(实际上里面包含一个RGB图和两个光流特征图), W W W是网络参数,所以 F F F就是指卷积网络计算, g g g是分别对Spatial和Temporal多个 F F F进行融合,文中使用均值,得到两个Stream的多片段融合结果(Fig 1中的Segmental Consensus),最后用 H H H结合两个Stream的结果,文中用Softmax(Fig 1中的Class Score Fusion);
- 对于最后的 H H H使用交叉熵Loss,对于 g g g则使用下图公式2,其中 C C C是类别总数, y i y_i yi是第i类的label, G i G_i Gi是Segmental Consensus对于第i类的预测;
- 双流模型由原本的ClarifaiNet改用BN-Inception。且需注意,所有片段的Spatial ConvNet权重共享,Temporal ConvNet亦然;
- 针对Spatial提出RGB difference,即前后两图的差值,加入了运动关联性(如下图2);
- 针对Temporal提出wraped optical flow,达到抑制背景运动的影响(如下图2);
- 将Spatial的预训练迁移到Temporal中;
- 因数据量少可能导致过拟合,故使用partial BN,冻结第一层以外的BN层,仅通过第一层BN学习特征分布;
- 并在global average pooling后接dropout,Spatial的dropout ratio是0.8而Temporal是0.7;
- 实验证明Optical Flow + Warped Flow + RGB效果最好,RGB difference的负面影响可能来自于其不稳定性。


公式1:
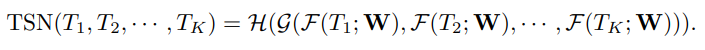
公式2:
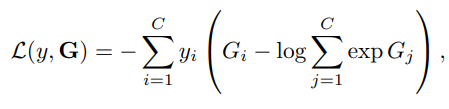
参考链接:https://blog.csdn.net/u014380165/article/details/79029309
TRN 2017
TRN: Temporal Relation Network
官网: http://relation.csail.mit.edu/
论文: https://arxiv.org/abs/1711.08496v2
标题: Temporal Relational Reasoning in Videos
作者: Bolei Zhou, Alex Andonian, Aude Oliva, Antonio Torralba
CSAIL, MIT
代码: https://github.com/zhoubolei/TRN-pytorch
收录: ECCV 2018
关键词:
- 结合2帧、3帧、一直到n帧的结果,进行多时序尺度的融合(参考下图Fig 2);
- 如下公式1和公式2,是2帧推理过程和3帧推理过程的示例,其中 f i f_i fi是第 i i i帧经CNN的输出, g g g和 h h h是MLP多层感知机;
- 多时序尺度推理结果(2帧、3帧等)的融合如下公式3, T n T_n Tn代表 n n n帧的结果,需注意的是不同时序尺度中 g g g和 h h h使用各自独立的权重,而CNN权重统一;
- 个人感觉和TSN的区别如下:
- 舍弃了Temporal ConvNet;
- 两者都对多帧进行了融合,TSN是在分别在Spatial和Temporal上取均值后,再Softmax得到结果,而TRN是多帧结果concat后,用多层感知机计算结果。感觉这种改动比前者的Average多了可学习时序的参数;
- 因算力的限制,采每帧之间都会相隔数帧,那么采帧的频率越高,就越可能采到对预测起关键作用的帧;
- 实验证明,TRN的优势在于有方向性的动作的识别性能上,对于无明显方向的动作,乱序和顺序数据的性能差异较小;

公式1:
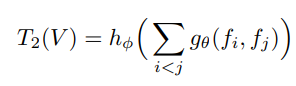
公式2:
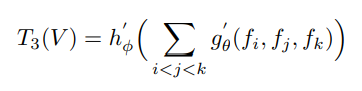
公式3:
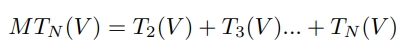
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









