






C++语言的表达式模板:表达式模板的入门性介绍
原标题:C++ Expression Templates: An Introduction to the Principles of Expression Templates
原作者:Klaus Kreft与Angelika Langer
原文链接: http://www.angelikalanger.com/Articles/Cuj/ExpressionTemplates/ExpressionTemplates.htm
翻译:Magi Su
翻译已经过原作者许可,转载请先征求原作者的许可。图片均取自原文,如果有水印为CSDN所打和老子没关系。出于清晰起见,文章中所有模板中的class都被改为typename。
模板(template)最早是以将类型(type)参数化为目的引入C++语言的。(译注1)链表 (list)是一个典型的例子。实际编码的时候,人们并不希望为保存不同类型变量的链表 分别编码,而是希望在编写的时候能够使用一个占位符(placeholder)来代替具体的类型 (即是模板参数),而让编译器来生成不同的链表类(模板的实例化)。
时至今日,模板的使用已经远远超过C++模板的发明者所预期的范畴。模板的使用已经涵盖 了泛型编程,编译时求值,表达式模板库,模板元编程,产生式编程(generative programming)等诸多领域。在这篇文章中,我们仅限于探讨一些表达式模板的编程知识, 侧重于编写表达式模板程序库这个方面。
我们必须指出:表达式模板库是相当复杂的。出于这个原因,我们读到过的关于表达式模 板的介绍都不是很容易理解的。因此,本文的作者希望能够通过本文为表达式模板提供一 个通俗的介绍,同时又不失对具体实现细节的阐述,从而对读者阅读模板库的代码能够起 到帮助。作者希望提取出表达式模板编码的一些原则性知识。有关于此领域的更多细节可 以参考其他著作。
创世纪
这段小小的程序引发了之后多年对所谓模板元编程的雪崩般的研究。本文将介绍从中得来 的一些编程技巧和技术。那么,模板元编程的工作原理是什么呢?
从本质上来看,无论是质数的计算,还是本文中所提及的其他技术,都是基于如下原理的 :模板的实例化是一个递归过程。当编译器实例化一个模板时,它可能会发现在此之前另 外的模板需要首先实例化;在实例化这些模板的时候,又会发现有更多的模板需要实例化 。许多模板元编程的技巧就是基于这个原理,来实现递归式的计算的。
阶乘——编译时计算的第一个例子
int factorial(int n)
{
return (n == 0 ? 1 : n * factorial(n - 1));
}
这个函数反复调用自身,直到参数n的值减少到0为止。使用的例子:
cout << factorial(4) << endl;递归式的函数调用是昂贵的,特别是在编译器无法进行内联(inline)优化的时候——这样 函数调用的负担马上就凸显出来。我们可以用编译时计算来避免这一点。做法如下:用递 归式的模板实例化来代替递归式的函数调用。这样,名为factorial的函数将由名为 factorial的类代替:
template <int n>
struct factorial
{
enum { ret = factorial<n-1>::ret * n };
};
这个模板类既没有数据也没有成员函数,而仅仅是定义了有唯一enum值的匿名enum类型。 (之后便可以看到,factorial::ret起到了函数返回值的作用。)为了计算这个值,编译 器必须反复实例化以n-1为模板参数的新的模板类,这就是递归的第一推动力。
值得注意的是,factorial模板类的参数并不常见:它并不是一个类型的占位符,而是一个 int类型的常量。常见的模板参数都和下面的例子类似:
template <typename T> class X {...};其中T是一个实际类型的占位符。在编译器遇到形如X<int>的代码时,T将被具体的类型( int)所取代。在我们的例子中,实际类型int成为了模板的参数,也就是说,在编译时将 被具体的int类型的值所取代。调用此模板类的代码可以是这样的:
cout << factorial<4>::ret <<endl;编译器将依次实例化factorial<4>,factorial<3>……我们注意到,这个递归是没有终点的 。这样可不行。所以,需要利用模板的特化来提供这样一个终点。在我们的这个例子里:
template <>
struct factorial<0>
{
enum { ret = 1 };
};
从上述代码片段中可以看到递归将止步于此。因为此时enum的值已经不再依赖实例化其他 模板类了。
倘若你不熟悉模板的特化,在这里只需要记住对于特定的模板参数,可以提供一个特殊的 类模板即可。在我们的例子中我们提供了一个特殊的,参数为0的阶乘模板类。在这里编译 器可以不再通过递归来计算需要的值。
那么我们这么计算阶乘,好处是什么呢?表达式factorial<4>::ret在编译时将会被其具体 数值,也就是24所取代。运行时无需对此进行计算。在可执行文件里,是找不到计算的痕迹的。
开平方根——编译时计算的又一个例子
让我们试试另外一个编译时计算的例子。这一次,我们试图计算N的平方根的近似值——更准 确的说,我们希望能找到一个整数,使得它的平方是最小的比N的平方大的完全平方数。例 如:10的平方根大约是3.1622776601,所以哦我们希望能通过编程得到4这个比 3.1622776601大的最小的整数。如果采用运行时计算的方法的话,我们就需要调用C的标准 库:ceil(sqrt(N))。但是如果需要用这个值来定义数组的大小的话,那么我们就倒了大霉 :int array[ceil(sqrt(N))];不能通过编译,因为数组的大小在编译时必须是一个常数。(译注3)因此,我们有理由在 编译时进行计算。
回忆一下我们在第一个例子中所做的:我们利用了模板实例化是通过递归进行这一特性。 在这里我们再次通过引发递归式的模板实例化来近似获取相应的值。这里我们定义一个有 一个给定类型int的模板参数N的类模板,并使用一个内部保存的值来返回结果。如果我们 将这个类命名为Root,那么它的一个用例如下:
int array[Root<10>::ret];
Root的代码如下:
template <size_t N, size_t Low = 1, size_t Upp = N> struct Root
{
static const size_t ret = Root<N, (down ? Low : mean + 1),
(down ? mean : Upp)>::ret;
static const size_t mean = (Low + Upp) / 2;
static const bool down = ((mean * mean) >= N);
};
在此我们不拘泥于细节,仅仅给出一些注解。(译注4)模板类有三个参数,其中两个有默 认值。在这三个参数中:
- 需要开方的数
- 预期平方根的上界和下界。默认值是1和N。平方根必然是介于1和N之间的某个数。
在这个例子中,返回值ret不是一个enum的值,而是一个静态常数成员,用于引发递归实例 化。余下的静态数据成员mean和down仅仅作为辅助,以简化递归实例化的编码。
在什么时候递归才能停止呢?递归的停止取决于一个特化的,不需要进一步进行模板实例 化的模板。如下是所需的偏特化的Root类:
template <size_t N, size_t Mid>
struct Root<N, Mid, Mid>
{
static const size_t ret = Mid;
};
这里偏特化只有两个模板参数。这是因为在递归结束的时候,上界和下界均已收敛到结果上了。
在我们的递归例子中,会产生如下实例化的模板:
Root<10, 1, 10>;
Root<10, 1, 5>;
Root<10, 4, 5>;
Root<10, 4, 4>;之后得到了4这个预期的结果。
从上述两个例子可以看出,编译时计算通常是通过递归实例化模板这一途径进行的。递归 的函数为类模板所取代。函数的参数为已知类型的常数模板参数代替,而返回值则由类内 保存的常数来表示。递归的终止通常由模板的特化来实现。有了上述的知识,Erwin Unruh 的质数计算程序将不再神秘,因为它无非是使用了与上述两个例子相同的原理而已。
表达式模板
到此为止,我们已经能够在编译时进行数值计算(译注5),然而这还不是本文的主题。下 面我们进行一项更宏伟的计划:在编译时进行更加复杂的表达式计算。首先我们来实现一 个编译时计算向量点乘的功能。点乘定义为两个向量对应元素的积的和。例如:两个三维 向量(1, 2, 3)和(4, 5, 6)的点乘等于1 * 4 + 2 * 5 + 3 * 6,也就是32。我们的目标是 使用表达式模板来计算任意维度向量的点乘,如下所示:int a[4] = {1, 100, 0, -1};
int b[4] = {2, 2, 2, 2};
cout << dot<4>(a, b) <<endl;点乘是表达式模板的一个最简单的例子,不过在这里使用的技术可以被扩展到高阶矩阵的 数值计算上。对于矩阵来说,编译时求值的技巧可以带来比向量计算更加好的性能提升。
反复用不同的参数代入相同函数求值的情况下,表达式模板可以起到有力的辅助作用。如 果使用这种技术,我们不再需要在运行时损失调用函数的时间,而是可以直接将函数在编 译时嵌入到调用之中。例如在计算积分
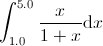
的时候。我们知道积分x / (1 + x)可以通过在积分区间中取n个等距离的点(这里是 [1.0, 5.0])来近似计算。(译注6)如果我们使用表达式模板来实现一个近似求解任意函 数积分的程序,那么它的一个可能的样子如下:
template <typename ExprT>
double integrate(ExprT e, double from, double to, size_t n)
{
double sum = 0;
double step = (to - from) / n;
for(double i = from + step / 2; i < to; i += step)
sum += e.eval(i);
return step * sum;
}
在这个例子里,函数x / (1 + x)将被ExprT表示。我们在下文中可以看到这是如何实现的 。(译注 7)
点乘(I)——表达式模板的第一个应用
为了方便读者理解表达式模板的基本思想,我们在这里采用经典设计模式来描述点乘和算 数表达式的实现。有关于设计模式方面的知识读者可以参考Gamma等人编著的设计模式著作 (/GOF/)。向量的点乘可以看作是组合(composite)的一个特例。
组合模式所表示的是部分——整体之间的关系:用户可以忽略单个对象和组合对象之间的差 别。这里的关键点在于叶结点和组合体。
- 叶结点定义组合体中个体对象的行为。
- 组合体定义叶结点集合的行为。
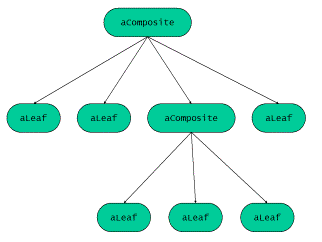
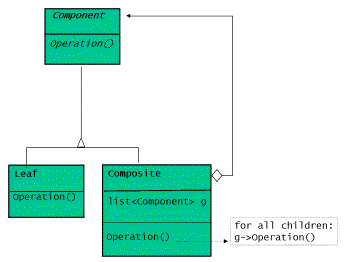
著作GOF提出了一个采用虚基类实现的面向对象的组合体设计:定义叶结点和组合体共有的 操作,而叶结点和组合体均从一个基类派生出来。
向量的点乘可以看作组合体设计模式的一个特例。点乘可以分成两个部分:叶结点是一维 向量的积,而组合体是剩下N-1维向量的点乘。
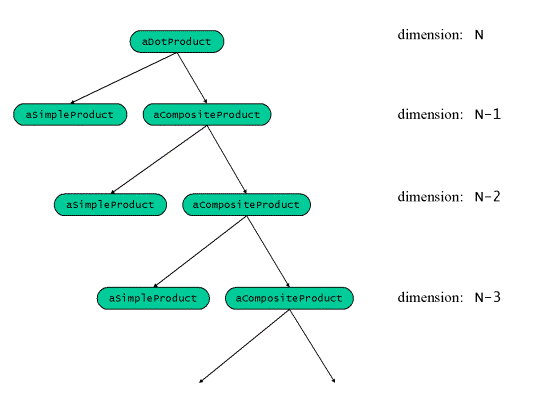
显而易见,这是组合体的某种简并(degenerate)形式,每个组合体包含一个叶结点和一 个组合体。使用面向对象编程的技术,我们可以用一个基类和两个派生类来表示点乘:
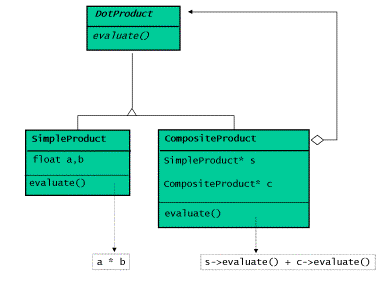
具体的编码实现可以参考列表1-3的内容。列表4给出了一个方便使用的辅助函数,列表5是 一个具体的使用例子。
template <typename T> class DotProduct
{
public:
virtual ~DotProduct () {}
virtual T eval() = 0;
};
列表2:组合体
template <typename T>
class CompositeDotProduct : public DotProduct<T>
{
public:
CompositeDotProduct (T* a, T* b, size_t dim) :
s(new SimpleDotProduct<T>(a, b)),
c((dim == 1) ? 0 : new CompositeDotProduct<T>(a + 1, b + 1, dim - 1))
{}
virtual ~CompositeDotProduct ()
{
delete c;
delete s;
}
virtual T eval()
{
return ( s->eval() + ((c) ? c->eval() : 0));
}
protected:
SimpleDotProduct<T>* s;
CompositeDotProduct<T>* c;
};
列表3:叶结点
template <typename T>
class SimpleDotProduct : public DotProduct<T>
{
public:
SimpleDotProduct (T* a, T* b) : v1(a), v2(b)
{}
virtual T eval()
{
return (*v1)*(*v2);
}
private:
T* v1;
T* v2;
};
列表4:辅助函数
template <typename T>
T dot(T* a, T* b, size_t dim)
{
return (dim == 1) ?
SimpleDotProduct<T>(a, b).eval() :
CompositeDotProduct<T>(a, b, dim).eval();
}
列表5:具体使用
int a[4] = {1, 100, 0, -1};
int b[4] = {2, 2, 2, 2};
cout << dot(a, b, 4);当然,这不是计算点乘的最有效途径。我们可以通过在派生类中消去叶结点和组合体来简化实现。这样,不在构造函数里传递且保存需要计算的向量,以便之后的计算,而是直接将向量传递给求值函数。将构造函数和求值函数由
SimpleDotProduct<T>::SimpleDotProduct (T* a, T* b) : v1(a), v2(b)
{}
virtual T SimpleDotProduct<T>::eval()
{
return (*v1)*(*v2);
}
修改为一个带参数的求值函数:
T SimpleDotProduct::eval(T* a, T* b, size_t dim)
{
return (*a)*(*b);
}
简化的实现可以参考列表6中的代码:基类可以保持不变,但是辅助函数需要进行修改。
template <typename T>
class CompositeDotProduct : public DotProduct <T>
{
public:
virtual T eval(T* a, T* b, size_t dim)
{
return SimpleDotProduct<T>().eval(a,b,dim) + ((dim==1) ?
0 : CompositeDotProduct<T>().eval(a+1,b+1,dim-1));
} };
template <typename T>
class SimpleDotProduct : public DotProduct <T>
{
public:
virtual T eval(T* a, T* b, size_t dim)
{
return (*a)*(*b);
}
};
图5表明了简化模型对应的类图
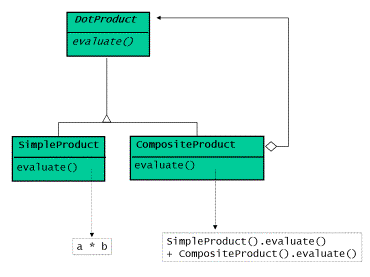
点乘(II)——编译时计算
现在我们来通过在模板的参数中保存结构信息的方式来实现组合体。我们需要保存的结构 信息是这个向量的维度。回忆一下之前我们计算阶乘和平方根的代码:函数实现中函数的 参数变为了编译时处理的模板参数。我们在这里也采用相同的手法,原来在面向对象实现 中传递给求值函数的向量的维度,在这里变为编译时确定的模板参数。因此在组合体中, 这个维度数据将变为模板中的一个常量参数。
叶结点则需要通过组合体类在一维情况下的模板特化类来实现。正如以往一样,我们将运 行时的递归转变为编译时的递归:将对求值虚函数的递归调用转变为模板类在递归实例化 的过程中对一个静态的求值函数的递归调用。如下是编译时计算点乘代码的类图:
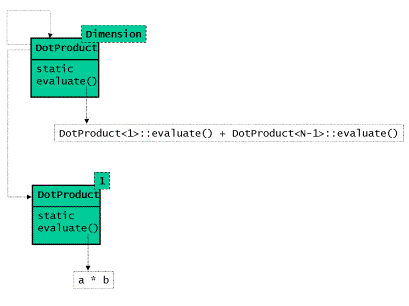
图6:编译时计算点乘的类图
具体实现代码在列表7中供参考。使用的例子可以参见列表8。
template <size_t N, typename T>
class DotProduct
{
public:
static T eval(T* a, T* b)
{
return DotProduct<1,T>::eval(a,b) + DotProduct<N-1,T>::eval(a+1,b+1);
}
};
template <typename T>
class DotProduct<1,T>
{
public:
static T eval(T* a, T* b)
{
return (*a)*(*b);
}
};
template <size_t N, typename T>
inline T dot(T* a, T* b)
{
return DotProduct<N,T>::eval(a, b);
}
int a[4] = {1, 100, 0, -1};
int b[4] = {2, 2, 2, 2};
cout << dot<4>(a,b);
注意到在运行时计算中,点乘函数的调用方法是dot(a, b, 4),而编译时计算中,点乘函 数的调用方法是dot<4>(a, b):
- dot(a, b, 4)等价于CompositeDotProduct<int>().eval(a, b, 4),递归式的引发如下函数在运行时的调用:
SimpleDotProduct<int>().eval(a, b, 1);
CompositeDotProduct<int>().eval(a + 1, b + 1, 3);
SimpleDotProduct<int>().eval(a + 1, b + 1, 1);
CompositeDotProduct<int>().eval(a + 2, b + 2, 2);
SimpleDotProduct<int>().eval(a + 2, b + 2, 1);
CompositeDotProduct<int>().eval(a + 3, b + 3, 1);
SimpleDotProduct<int>().eval(a + 3, b + 3, 1);
总共进行7次虚函数的调用。
- dot<4>(a, b)通过计算DotProduct<4, int>::eval(a, b),从而递归式的引发下列模板依次实例化展开:
DotProduct<4, size_t>::eval(a, b);
DotProduct<1, size_t>::eval(a, b) + DotProduct<3, size_t>::eval(a + 1, b + 1);
(*a) * (*b) + DotProduct<1, size_t>::eval(a + 1, b + 1) + DotProduct<2, size_t>::eval(a + 2, b + 2);
(*a) * (*b) + (*a + 1) * (*b + 1) + DotProduct<1, size_t>::eval(a + 2, b + 2) + DotProduct<1, size_t>::eval(a + 3, b + 3);
(*a) * (*b) + (*a + 1) * (*b + 1) + (*a + 2) * (*b + 2) + (*a + 3) * (*b + 3)在可执行文件中,只会有(*a) * (*b) + (*a + 1) * (*b + 1) + (*a + 2) * (*b + 2) + (*a + 3) * (*b + 3)对应的代码;具体的展开过程是在编译时完成的。
很明显,模板编程提升了运行时的计算性能,但是代价是延长了编译的时间。递归的模板 实例化展开所造成的编译时间延长是以数量级形式进行的。而面向对象的代码虽然编译时 间短,却花费了更多的运行时间。
编译时计算的另一个局限性在于,向量的维度必须在编译时就已知,因为这个值需要通过 模板参数来传递。实际上这反而不是太大的问题,因为通常这个值在编码的时候的确是已 知的,例如,我们如果要计算空间中的向量,那么向量的维度显然是3。
点乘的代码未必能给读者留下深刻印象,因为事实上我们只需要手工展开乘法,就能带来 和模板编程带来的相同的性能提升。然而这里所提及的技术并不仅仅局限于点乘,而是可 以扩展到高阶矩阵的算术计算上去。这样的编码将大大简化编程的复杂性。如果定义a为 10x20的矩阵,b为20x10的矩阵,而c为10x10的矩阵(译注8),那么使用a * b + c来表达 计算将显得非常简洁明了。程序员显然宁愿让编译器自动的,同时也是可靠的处理这个问 题,而不愿意手工展开如此高阶的矩阵。
算术表达式——表达式模板的另一个应用
让我们通过一个更加现实的组合体来进一步研究这种编程技术。算术表达式是由一元和二 元的算术运算符,以及变量和常量这些元素组成的。GOF这本书中采用解释器( Interpreter)模式来应对这种情况。解释器模式采用一个抽象语法树来描述算术表达式语言,同时用一个解释器来处理这个语 法树。这是组合体的一个特例。组合体中“部分-整体”的关系与解释器中子表达式和表达式 之间的关系相互照应。
- 叶结点是一个终点表达式(terminal expression)。
- 组合体是一个非终点表达式(nonterminal expression)。
- 通过解释表达式树和其中包含的表达式来进行求值。
形如(a + 1) * c或者log(abs(x - N))的算术表达式将由语法树来实现。共有两种终点表 达式:常数(literial)与数值变量(variable)。常数对应的是已知的数值,而数值变 量则可能在每次求值时取不同的值。非终点表达式则由一元或者二元运算符组成,每个非 终点表达式可能包含一到两个终点表达式。表达式中可能有各种不同语义的运算符,比如+ ,-,*,/,++,--,exp,log,sqrt等等。
我们通过(x + 2) * 3这个具体实例来分析。组合体的结构,也就是语法树的结构,如下图所示:
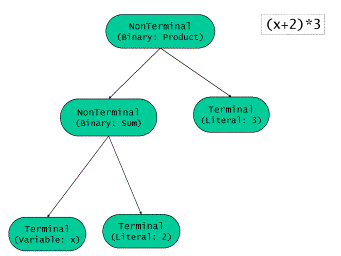
在GOG中,解释器的经典的面向对象设计如下类图所示:
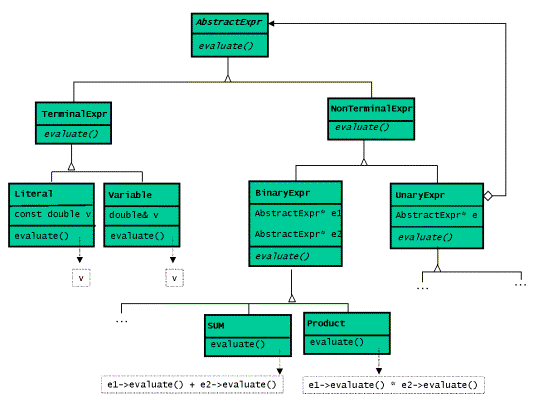
与之相关的代码实现可以参见列表9.UnaryExpr的基类与BinaryExpr的类相似,所有的一元 和二元运算均和类Sum相似。
class AbstractExpr
{
public:
virtual double eval() const = 0; };
class TerminalExpr : public AbstractExpr
{ };
class NonTerminalExpr : public AbstractExpr
{ };
class Literal : public TerminalExpr
{
public:
Literal(double v) : _val(v)
{}
double eval() const
{
return _val;
}
private:
const double _val;
};
class Variable : public TerminalExpr
{
public:
Variable(double& v) : _val(v)
{}
double eval() const
{
return _val;
}
private:
double& _val;
};
class BinaryExpr : public NonTerminalExpr
{
protected:
BinaryExpr(const AbstractExpr* e1, const AbstractExpr* e2) : _expr1(e1),_expr2(e2)
{}
virtual ~BinaryExpr ()
{
delete const_cast<AbstractExpr*>(_expr1);
delete const_cast<AbstractExpr*>(_expr2);
}
const AbstractExpr* _expr1;
const AbstractExpr* _expr2;
};
class Sum : public BinaryExpr
{
public:
Sum(const AbstractExpr* e1, const AbstractExpr* e2) : BinExpr(e1,e2)
{}
double eval() const
{
return _expr1->eval() + _expr2->eval();
}
};
//...
列表10中则表明了解释器是如何解析算术表达式(x + 2) * 3的:
void someFunction(double x)
{
Product expr(new Sum(new Variable(x), new Literal(2)), new Literal(3));
cout << expr.eval() <<endl;
}
在这里,首先创造了一个表达式对象,用以表示(x + 2) * 3。之后该对象对自身进行求值 。自然而然的,我们觉得这是一个极其低效的计算方法。现在我们将它转化为表达式模板 。
正如之前点乘的例子中所示,我们首先要消除所有的虚基类。因为模板类中没有继承,取 而代之的是相同的成员名称。因此,我们不再使用基类,而将所有的终点表达式和非终点 表达式都用单独的类来表示,它们共有一个相同的名为eval的函数。
下一步,我们将通过类模板UnaryExpr和BinaryExpr来生成所有的形如Sum和Product的非终 点表达式。这里结构信息将全部保存在类模板的参数中。这些类模板将其子表达式的类型 作为其类型模板。另外,我们将具体的运算符操作抽象为类模板中一个类型,通过仿函数 对象传递。
实现,与面向对象实现没有很大的差别。
同样的,运行时递归将由编译时递归所代替:我们将虚的求值函数的递归调用改为表达式 模板的递归实例化。
图9是基于模板实现表达式求值问题的类图:
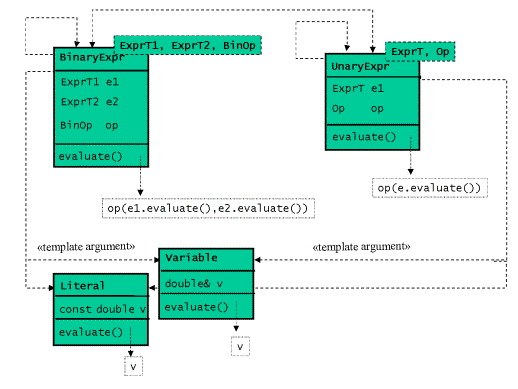
图9:基于模板实现的表达式求值解释器的类图
源码请参考列表11:
class Literal
{
public:
Literal(const double v) : _val(v)
{}
double eval() const
{
return _val;
}
private:
const double _val;
};
class Variable
{
public:
Variable(double& v) : _val(v)
{}
double eval() const
{
return _val;
}
private:
double& _val;
};
template <typename ExprT1, typename ExprT2, typename BinOp>
class BinaryExpr
{
public:
BinaryExpr(ExprT1 e1, ExprT2 e2,BinOp op=BinOp()) :
_expr1(e1),_expr2(e2),_op(op)
{}
double eval() const
{
return _op(_expr1.eval(),_expr2.eval());
}
private:
ExprT1 _expr1;
ExprT2 _expr2;
BinOp _op;
};
//...
UnaryExpr的类模板与BinaryExpr的类模板相似。对于实际操作,我们可以使用已经编写好 的STL的仿函数类plus,minus,等等,或者我们也可以自行编写。一个用来表示和的二元 表达式的类型是BinaryExpr<ExprT1, ExprT2, std::plus<double>>。(译注9)这样的类 型使用起来较为复杂,因此我们写一个产生函数,方便以后的使用。
我们将用产生函数来简化表达式对象的生成。列表12给出了产生函数的两个例子:产生函数
产生函数是在模板编程中广泛使用的一种技巧。在STL中有大量的产生函数,例如 make_pair()。产生函数的优势在于,可以利用编译器对函数模板参数的自动推导来简化 编程,而对类模板,编译器是无法进行自动推导的。
每次我们从一个类模板中创建一个对象的时候,我们需要给出完整的类模板参数的实例化信息。在很多情况下,这些信息非常复杂,难于理解。例如包含pair的pair: pair<pair<string, complex<double>>, pair<string, complex<double>>>。产生函数可以简化这个问题:它将生成给定类型的对象,而无需我们写出冗长的类型声明信息。
更准确的说,产生函数是一类函数模板。这种函数模板与它生成的对象对应的模板类有着相同的模板参数。以pair为例,pair类模板有两个类型参数T1和T2,表示它所包含的两个 元素的类型,而make_pair()产生函数同样包含这两个类型参数:
template <typename T1, typename T2> class pair { public: pair(T1 t1, T2 t2); // ... }; template <typename T1, typename T2> pair<T1,T2> make_pair(t1 t1, T2 t2) { return pair<T1,T2>(t1, t2); }
产生函数与构造函数非常相似:我们传递给产生函数的参数和我们传递给构造函数的 参数是一样的。因为编译器能够自动推导函数模板中模板参数所表示的类型,我们可以借 此省去这个声明,而把这一繁重的工作交给编译器来进行。因此,我们不用通过
pair< pair<string,complex<double>>, pair<string,complex<double>>>( pair<string,complex<double> >("origin", complex<double>(0,0)), pair<string,complex<double> >("saddle", aCalculation()))
来声明一个复杂的pair,而通过产生函数进行:
make_pair(make_pair("origin", complex<double>(0,0)), make_pair("saddle", aCalculation()))
template <typename ExprT1, typename ExprT2>
BinaryExpr<ExprT1,ExprT2,plus<double>> makeSum(ExprT1 e1, ExprT2 e2)
{
return BinaryExpr<ExprT1,ExprT2,plus<double> >(e1,e2);
}
template <typename ExprT1, typename ExprT2>
BinaryExpr <ExprT1,ExprT2,multiplies<double>> makeProd(ExprT1 e1, ExprT2 e2)
{
return BinaryExpr<ExprT1,ExprT2,multiplies<double> >(e1,e2);
}
列表13给出了基于模板实现的解释器解析(x + 2) * 3的方式:
void someFunction (double x)
{
BinaryExpr< BinaryExpr < Variable, Literal, plus<double> >, multiplies<double>>
expr = makeProd (makeSum (Variable(x), Literal(2)), Literal(3));
cout << expr.eval() << endl;
}
首先生成了一个代表(x + 2) * 3的表达式对象,然后这个对象对自身进行求值。表达式对 象的结构本身即是语法树的结构。
我们其实完全不必给出如此冗长的类型信息,而是可以直接使用产生函数来自动生成,如 下所示:
cout << makeProd(makeSum(Variable(x),Literal(2)),Literal(3)).eval() << endl;
通过模板来实现解释器这个设计模式的优越性是什么呢?倘若所有的产生函数,构造函数 和求值函数都能被编译器内联的话(这应该是可以办到的,因为这些函数本身都很简单) ,表达式makeProd(makeSum(Variable(x),Literal(2)),Literal(3)).eval()最终将被编 译器转化为(x + 2) * 3进行编译。
回过头来看列表10中的代码
Product expr(new Sum(new Variable(x),new Literal(2)), new Literal(3)).eval()仅仅这一小段中就包含了大量的堆上的内存申请和对象构造,同时也引入了不少对虚函数 eval()的调用。这些虚函数调用很难被内联,因为编译器一般不会内联通过指针调用的函 数。(译注10)
可见,基于模板的实现将比面向对象的实现效率高上许多。
表达式模板的进一步应用
为了使用上的方便,我们进一步的修改表达式模板。首先要考虑的是增加可读性。我们希 望的是如下的语句
makeProd(makeSum(Variable(x), Literal(2)), Literal(3)).eval() 可以更像是它所表示的表达式(x + 2) * 3。只要稍稍修改代码,并且使用运算符重载,我 们就可以把它变为eval((v + 2) * 3.0)。
首先我们要将产生函数修改为重载的运算符。也就是说,将makeSum改为operator+,将 makeProd改为operator*,等等。这样产生的效果就是将
makeProd(makeSum(Variable(x), Literal(2)), Literal(3))转化为
((Variable(x) + Literal(2)) * Literal(3))这已经是一大进步了。但是距离我们所希望的直接写(x + 2) * 3还有一定差距。因此我们 需要设法消除Variable和Literal的构造函数的直接调用。
为了解决这个问题我们首先考察形如x + 2的表达式的意义。我们将产生函数从makeSum改 为operator+。这个函数的具体代码参见列表14:
template <typename ExprT1, typename ExprT2>
BinaryExpr<ExprT1, ExprT2, plus<double>> operator+(ExprT1 e1, ExprT2 e2)
{
return BinaryExpr<ExprT1, ExprT2, plus<double>>(e1,e2);
}
我们希望x + 2可以和之前的makeSum(x, 2),如今的operator+(x, 2)相对应。x + 2应当 创造一个代表求和的二元表达式对象,而这个对象的构造函数将以double类型的变量x以及 整形常量2作为构造参数。更准确的说,这将生成一个BinaryExpr<double, int,
plus<double>>(x, 2)的匿名对象。然而我们所期望的类型并非如此:需要的是BinaryExpr <Variable, Literal, plus<double>>类型的对象。可是,自动模板参数类型推导并不知道x是一个变量,而2是一个常量。编译器只能检查传递给函数的参数类型,从而从x中推导出double类型,从2中推导出int类型。
看起来我们需要稍稍给编译器一些更多的信息,从而得到我们所需要的结果。如果我们给函数传递的不是double类型的x,而是一个Variable类型的参数,那么编译器应该能够自动产生BinaryExpr<Variable, int, plus<double>>,这将更接近我们的目标。(我们将很快解决int到Literal的转换问题)因此,用户不得不对代码做一些小小的改动:他们需要用Variable类来包装他们的变量。如列表15所示:
void someFunction (double x)
{
Variable v = x;
cout << ((v + 2) * 3).eval() << endl;
}通过使用Variable对象v来代替一个数值类型的参数,我们可以将v + 2转化为一个等价于BinaryExpr<Variable, int, plus<double>>(v, 2)的匿名对象。这样的BinaryExpr对象有两个数据成员,一个是Variable,一个是int。求值函数BinaryExpr<Variable, int, plus<double>>::eval()将计算并且返回两个数据成员的和。问题是,int类型的数据无法自行转化为可以自动求值的对象,我们必须将常数2转化为Literal类型,才能进行自动求值。如何做到这种自动转化呢?我们需要使用traits。
Traits *TRAITS*
在模板编程中,traits是另一种常用的技术。traits类是一种只与另外一种类型配合,保存这种类型的具体信息的影子类(shadow class)。
C++ STL中有多个traits的例子,字符traits就是其中之一。读者大约知道标准库中的string类其实是一个类模板,这个类模板的参数是具体的字符类型。这就使得string可以处理普通的字符和宽字符。实际上,string类的实际名称是basic_string。basic_string可以通过实例化来接受任何类型的字符,而不仅仅是上述提及的两种。倘若有人需要保存以Jchar定义的日文字符,那么他就可以用basic_string模板实现:basic_string<Jchar>。
读者可以自己设想如何设计这样的string类模板。有一些必须的信息并不能由字符的类型本身所提供。例如,如何计算字符串的长度?这可以通过数一下字符串里的所有字符个数来实现。这样就需要知道字符串的结束记号是什么。但是如何知道这一点呢?虽然我们知道对于一般的字符,'\0'是结束符;宽字符wchar_t有它自己定义的结束符,但是对于Jchar呢?很明显,结束符这个信息与字符的类型直接相关,但是却不包括在类型本身所能提供的信息之中。这时traits就派上了用场:它们可以提供这些额外的,却是必须的信息。
traits类型是一种可以被具体的一组类型实例化或者特化的影子(shadow)类模板,在实例化或者特化的时候,它们包含了额外的信息。C++标准库中字符的traits,即是char_traits类模板,就包含了一个静态的字符常量,用以表示这种字符对应的字符串结束符的值。
我们使用traits技术来解决常数到Literal类型的转换问题。对于每一种表达式的类型,我们定义表达式的traits用以保存它们在各种运算符对象中的存储方式。所有的常数类型都应该以Literal类型的对象保存;所有的Variable对象都应该以本身的类型保存在Variables之中;而所有的非终端表达式都应该按照本身类型保存。列表16给出了traits的编码:
template <typename ExprT>
struct exprTraits
{
typedef ExprT expr_type;
};
template <>
struct exprTraits<double>
{
typedef Literal expr_type;
};
template <>
struct exprTraits<int>
{
typedef Literal expr_type;
};
//...
表达式traits类定义了一个嵌套类型expr_type,代表表达式对象的具体类型。未特化的traits模板类将所有常用的表达式类型保存为其本身。但是对于C++语言内置的数值类型,例如short,int,long,float,double等则进行了特化,它们在表达式中对应的类型均为Literal。
在BinaryExpr和UnaryExpr类中,我们将使用表达式traits来确认存有子表达式的数据成员的类型。
template <typename ExprT1, typename ExprT2, typename BinOp>
class BinaryExpr
{
public:
BinaryExpr(ExprT1 e1, ExprT2 e2,BinOp op=BinOp()) :
_expr1(e1), _expr2(e2), _op(op)
{}
double eval() const
{
return _op(_expr1.eval(),_expr2.eval());
}
private:
exprTraits<ExprT1>::expr_type _expr1;
exprTraits<ExprT2>::expr_type _expr2;
BinOp _op;
};
通过使用表达式traits,BinaryExpr<Variable, int, plus<double>>可以将它的两个运算元的类型分别保存为Variable和Literal。这正是吾等草民所期望的。
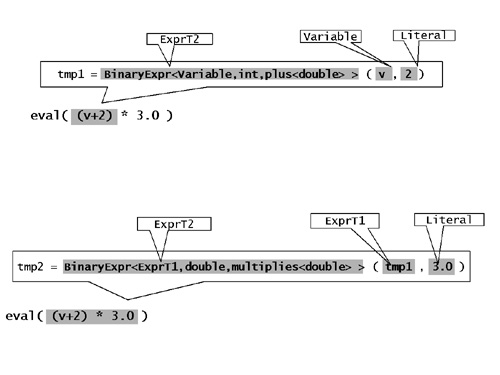
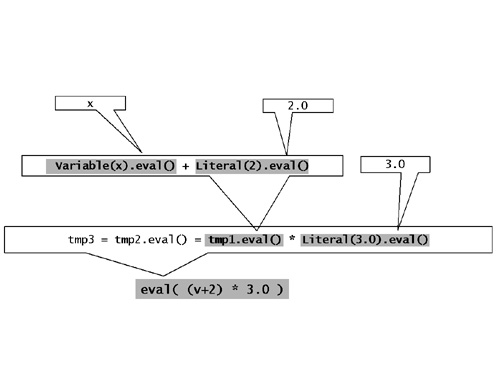
现在我们已经可以使用((v + 2) * 3).eval()来进行求值了。在这里v是一个Variable类型,其中封装了一个double类型的对象x。这样,实际上的求值就是(x + 2) * 3了。我们可以为可读性着想,稍稍再做进一步的改进。人们通常觉得调用表达式的一个成员函数进行求值看上去很古怪。不过我们可以设计一个辅助函数,将((v + 2) * 3).eval()变为eval((v + 2) * 3)。这两段代码虽然事实上是等价的,但是却更符合诸君的阅读习惯。列表18给出了这个辅助函数:
template <class ExprT> double eval(ExprT e)
{
return e.eval();
}图10给出了表达式((v + 2) * 3).eval()在v作为Variable封装了一个double类型的x的情况下,在编译过程中是如何逐步的展开为(x + 2) * 3的。
表达式对象的反复计算
读者可能仍然在考虑表达式对象的优势在何处。每个表达式对象代表了一个算术表达式的分解,从而形成了一个语法树,而这个语法树又能够自动求值。简而言之,我们创造了一个机械式的表达式求值途径——虽然这个途径C++语言本身就支持。那么这么做到底有何好处呢?下面我们来考察这一点。
迄今为止,我们所用到的语法树都是静态的。每个语法树在构造之后,只被调用一次。然而我们可以通过给定一个语法树,并传入不同的参数值,来动态的使用这个模型。如上文所述,我们希望能够用如下的近似函数:
template <class ExprT>
double integrate (ExprT e,double from,double to,size_t n)
{
double sum = 0;
double step = (to - from) / n;
for (double i = from + step / 2; i < to; i += step)
sum += e.eval(i);
return step * sum;
}
计算类似下面的积分式:
为此我们可以用下面的例子给出的方式来调用这个函数:
Identity<double> x;
cout << integrate(x / (1.0 + x), 1.0, 5.0, 10) << endl;这里我们需要的是一个被反复调用的表达式对象,然而我们现有的代码尚不支持这样的操作。不过一些小小的修改即可满足我们的要求。只要让我们的eval函数接受一个值作为参数即可。非终端的表达式将把参数传递给它们的子表达式。Literal类只需要形式上的接受这个参数即可,它们的值不受这个参数所影响。Variable将不再返回Variable的值,而是它所接受到的这个参数的值。出于这个目的,我们把Variable改名为Identity。列表19给出了修改过的类。
class Literal
{
public:
Literal(double v) : _val(v)
{}
double eval(double) const
{
return _val;
}
private:
const double _val;
};
template<class T> class Identity
{
public:
T eval(T d) const
{
return d;
}
};
template <class ExprT1,class ExprT2, class BinOp> class BinExpr
{
public:
double eval(double d) const
{
return _op(_expr1.eval(d),_expr2.eval(d));
}
};
//...
如果编写sqrt(),sqr(),exp(),log()等等数值函数的非终点表达式代码,我们甚至可以计算高斯分布:
double sigma = 2.0;
double mean = 5.0;
const double Pi = 3.141593;
cout << integrate(
1.0 / (sqrt(2 * Pi) * sigma) * exp(sqr(x - mean) / (-2 * sigma * sigma)),
2.0, 10.0, 100) << endl;
我们可以通过调用C标准库里的相应函数来实现这些非终点表达式,只要增加相应的一元或者二元运算符的产生函数即可。列表21给出了一些例子:
template <typename ExprT>
UnaryExpr<ExprT, double(*)(double)> sqrt(const ExprT& e)
{
return UnaryExpr<ExprT, double(*)(double)>(e, ::std::sqrt);
}
template <typename ExprT>
UnaryExpr<ExprT, double(*)(double)> exp(const ExprT& e)
{
return UnaryExpr<ExprT,double(*)(double)>(e,::std::exp);
}
// ...
通过这些修改,我们得到了一个有力的高性能数值表达式计算库。利用本文所述的技术,不难为这个库增添逻辑计算的功能。如果将求值函数eval()改为括号算符的重载operator()(),我们可以很容易的将表达式对象转换为仿函数对象,这样就可以应用在STL的算法库中。下面是一个将逻辑表达式应用于计算链表中符合条件的元素个数的例子:
list<int> l;
Identity<int> x;
count_if(l.begin(), l.end(), x >= 10 && x <= 100);一旦编写好相应的表达式模板,就可以如上述例子所示一般,令代码兼具高度可读性和高效的运行时表现。建立这样的表达式模板库则相当复杂,需要使用本文尚未提及的许多模板编程技巧。但是无论如何,本文中涉及的编程原理已经覆盖了所有的模板库。
参考文献
已经有很多成熟的表达式模板库供读者下载。下文中仅仅提及了一部分。不过这些模板库程序并不一定具有较好的可读性或者代表性。如果读者希望获取更多资料,作者推荐读者访问下面的资料(参见/JUL/和/OON/)。| /GOF/ | Design Patterns: Elements of Reusable Object-Oriented Software |
| /VAN/ | C++ Templates – The Complete Guide |
| /UNR/ | Compile-Time Computation of Prime Numbers |
| /DUR/ | Design Patterns for Generic Programming in C++ |
| /VEL/ | T. Veldhuizen, "Expression Templates," C++ Report,Vol. 7 No. 5 June 1995, pp. 26-31 |
| /JÜL/ | Research Centre Jülich |
| /OON/ | The Object-Oriented Numerics Page |
| /BLI/ | The Blitz Project |
| /PET/ | PETE (Portable Expression Template Engine) |
| /POO/ | POOMA (Parallel Object-Oriented Methods and Applications) |
| /MET/ | MET (Matrix Expression Templates) |
| /MTL/ | MTL (Matrix Template Library) |
| /FAC/ | FACT! (Functional Additions to C++ through Templates andClasses) |
| /FCP/ | FC++ (Functional Programming in C++) |
| /BLL/ | BLL (The Boost Lambda Library) |
| /PHO/ | Phoenix (A parser used by Spirit) |
作者感谢在C++ UsersJ 阅读了我们文章的Gary Powell。他的邮件中提及了我们之前没有注意到的FACT!,FC++,Boost Lambda Library,以及Phoenix程序库。
译注:
译注1:参见《The Design and Evolution of C++》。
译注2:阶乘在数学上可以用Gamma函数定义。
译注3:C99是允许变长数组的,但是即便是最新的C++11标准也不支持变长数组。
译注4:这其实是使用二分法搜索平方根。作为一个优化,默认的Upp可以定为N的一半甚至 更少。
译注5:编译时数值计算是有相当局限性的,例如浮点数的计算就无法执行,这是因为浮点 数计算是和机器/编译器实现直接相关的。
译注6:参见Riemann积分定义。
译注7:C++11的Lambda语法可能大大减少此类技巧的使用。
译注8:原文中a,b,c均为20x10的矩阵,明显有误,这里更改为一个合理的值。
译注9:原文中>和>之间有一个多余的空格,这是C++03标准的要求。在C++11中这个空格可 以去掉。
译注10:虚函数是通过查询虚表进行的调用的,因此编译时很难确认具体哪个函数会被调 用,然而现在也有编译器可以在一定程度上预测调用的具体函数,参见g++的参数 -fdevirtualize。

















 1156
1156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









