







 本文介绍了一个基于Python的12306火车票查询系统,通过解析命令行参数,调用12306接口获取指定日期、出发地和目的地的火车票信息,并使用PrettyTable进行美观展示。系统支持查询高铁、动车、特快等多种车次类型,通过命令行即可轻松操作。
本文介绍了一个基于Python的12306火车票查询系统,通过解析命令行参数,调用12306接口获取指定日期、出发地和目的地的火车票信息,并使用PrettyTable进行美观展示。系统支持查询高铁、动车、特快等多种车次类型,通过命令行即可轻松操作。
火车站名对应的编号可以先在网上下载这个字典
https://pan.baidu.com/s/1hLb3DLB6uC6ADtXKALPBZA
可以这里下载的,整理好的py文件,可以直接使用.
Code:
coding: utf-8
“”"命令行火车票查看器
Usage:
tickets [-gdtkz]
Options:
-h,–help 显示帮助菜单
-g 高铁
-d 动车
-t 特快
-k 快速
-z 直达
Example:
tickets 北京 上海 2016-10-10
tickets -dg 成都 南京 2016-10-10
from docopt import docopt
from prettytable import PrettyTable
from colorama import Fore
import requests, stationsInfo, warnings
def cli():
arguments = docopt(__doc__, version='ticket 1.0')
from_station = stationsInfo.stations2CODE[arguments.get('<from>')]
to_station = stationsInfo.stations2CODE[arguments.get('<to>')]
date = arguments.get('<date>')
# 列表推导式,得到的是查询车次类型的集合
options = ''.join([key for key, value in arguments.items() if value is True])
print(options)
url = ('https://kyfw.12306.cn/otn/leftTicket/query?'
'leftTicketDTO.train_date={}&'
'leftTicketDTO.from_station={}&'
'leftTicketDTO.to_station={}&'
'purpose_codes=ADULT').format(date, from_station, to_station)
warnings.filterwarnings("ignore") # 这个网站是有安全警告的,这段代码可以忽略警告
r = requests.get(url, verify=False)
# print(r.json())
# requests得到的是一个json格式的对象,r.json()转化成python字典格式数据来提取,所有的车次结果result
raw_trains = r.json()['data']['result']
pt = PrettyTable()
pt._set_field_names("车次 车站 时间 经历时 商务座 一等座 二等座 高级软卧 软卧 动卧 硬卧 软座 硬座 无座".split())
for raw_train in raw_trains:
# split切割之后得到的是一个列表
data_list = raw_train.split("|")
train_no = data_list[3]
initial = train_no[0].lower()
# print(train_no[0])
# 判断是否是查询特定车次的信息
if not options or initial in options:
from_station_code = data_list[6]
to_station_code = data_list[7]
from_station_name = ''
to_station_name = ''
start_time = data_list[8]
arrive_time = data_list[9]
time_duration = data_list[10]
business_seat = data_list[32] or "--"
first_class_seat = data_list[31] or "--"
second_class_seat = data_list[30] or "--"
high_soft_sleep = data_list[21] or "--"
soft_sleep = data_list[23] or "--"
move_sleep = data_list[33] or "--"
hard_sleep = data_list[28] or "--"
soft_seat = data_list[24] or "--"
hard_seat = data_list[29] or "--"
no_seat = data_list[26] or "--"
pt.add_row([
# 对特定文字添加颜色
train_no,
'\n'.join([Fore.GREEN + stationsInfo.stations2CN[from_station_code] + Fore.RESET,
Fore.RED + stationsInfo.stations2CN[to_station_code] + Fore.RESET]),
'\n'.join([Fore.GREEN + start_time + Fore.RESET, Fore.RED + arrive_time + Fore.RESET]),
time_duration,
business_seat,
first_class_seat,
second_class_seat,
high_soft_sleep,
soft_sleep,
move_sleep,
hard_sleep,
soft_seat,
hard_seat,
no_seat
])
print(pt)
if __name__ == '__main__':
cli()
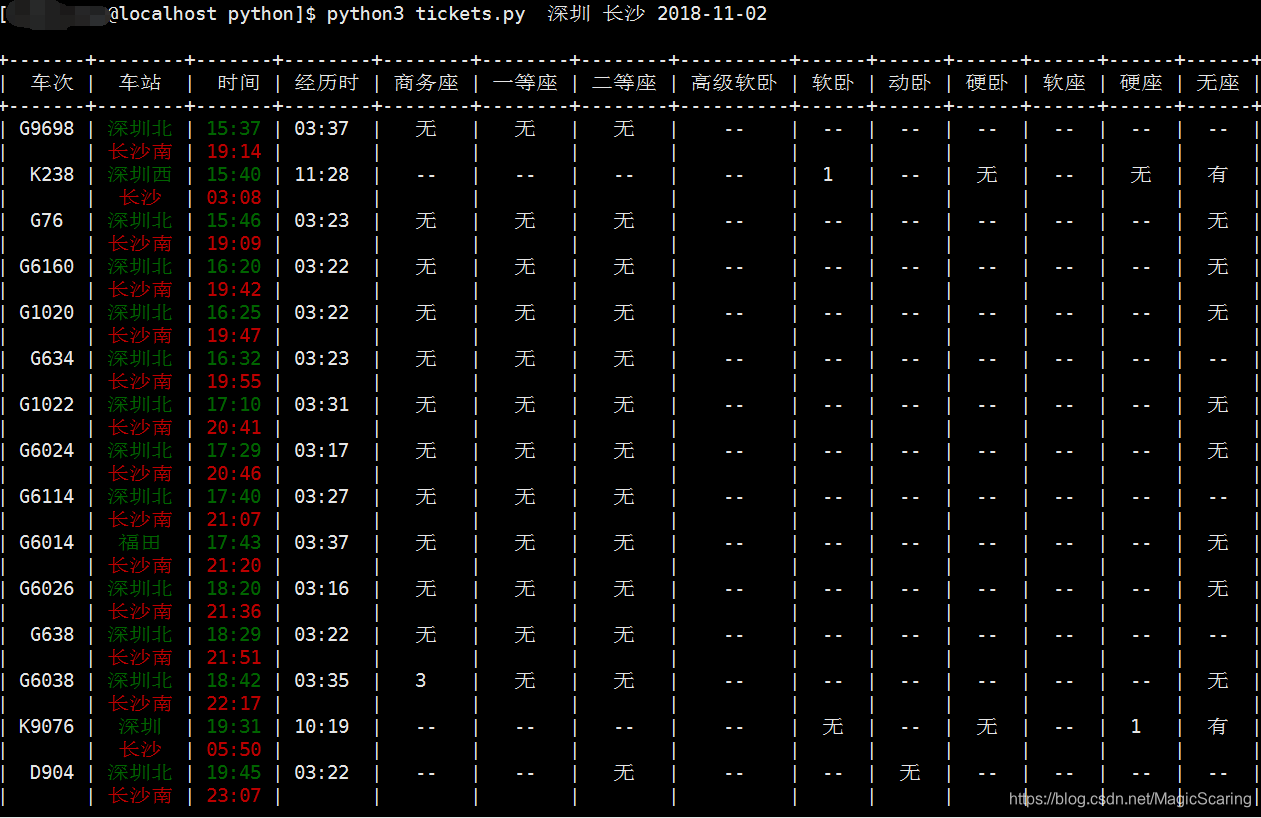
实现效果

















 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









