







 探讨了通过上下文损失(Contextual Loss)改进GAN训练,维持图像自然统计特性的方法。该方法通过比较特征分布,设计了一种计算简单且易于处理的损失函数,用于生成具有自然特征分布的图像。实验表明,这种方法在感知质量和训练效率方面优于传统方法。
探讨了通过上下文损失(Contextual Loss)改进GAN训练,维持图像自然统计特性的方法。该方法通过比较特征分布,设计了一种计算简单且易于处理的损失函数,用于生成具有自然特征分布的图像。实验表明,这种方法在感知质量和训练效率方面优于传统方法。
Maintaining Natural Image Statistics with the Contextual Loss 2018
https://github.com/roimehrez/contextualLoss
http://cgm.technion.ac.il/Computer-Graphics-Multimedia/Software/Contextual/
问题
GAN:他们很难训练,结果仍然经常受到人为因素的影响。
方法
其目标是训练一个前馈CNN,以保持自然的内部统计。
效果
明确地观察图像中特征的分布,训练网络生成具有自然特征分布的图像。GAN训练优于以前的方法,生成的图像在感知上更真实,同时减少所需的训练图像的数量的数量级。
想法
我们能训练CNN生成显示自然统计的图像吗?
做法
比较特征分布
提出一种计算简单且易于处理的类似于KL近似值的,为比较没有空间对齐的图像而设计的contextual loss.
1.应用于GAN
2.非图像数据
如何度量两个分布之间的差异
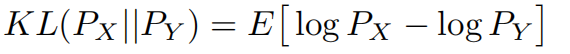
这需要从特征集X = {xi}和Y = {yj}近似化参数化密度PX, PY。最常用的方法是使用多元核密度估计(MKDE),将概率PX(pk)和PY (pk)估计为:
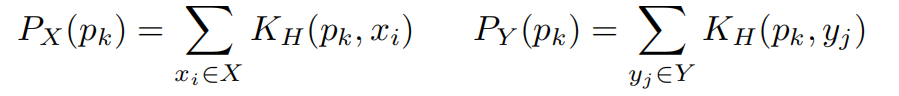
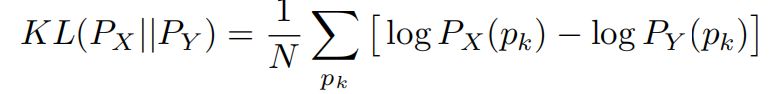
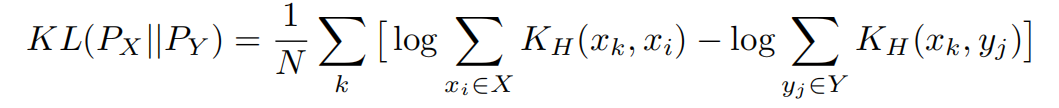
关键是找一个K核…
不仅要求样本的相似性,又要求特征的相似性
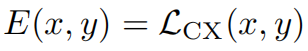
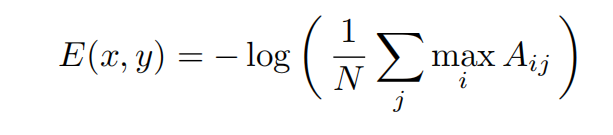
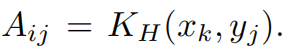
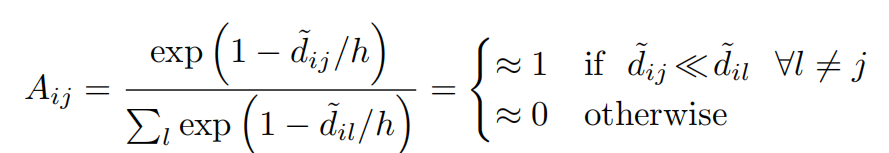
h= 0.1
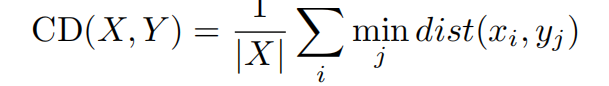
LCX计算规范化亲和力,考虑每个点xi到所有点yj∈Y的距离。因此,它使得两组点之间的匹配更加多样化,并且提供了更好的度量两个分布之间相似度的方法。LCX的训练引导网络在两个点集之间进行匹配,从而使底层分布更加接近。相比之下,CD训练不允许两组选手接近。事实上,我们从经验上发现,CD训练并不收敛,因此,我们从我们的经验报告中排除了它。
实验
- 第一个实验:最小化训练过程中的上下文损失实际上也意味着最小化KL-divergence。他俩的趋势是最相关的。
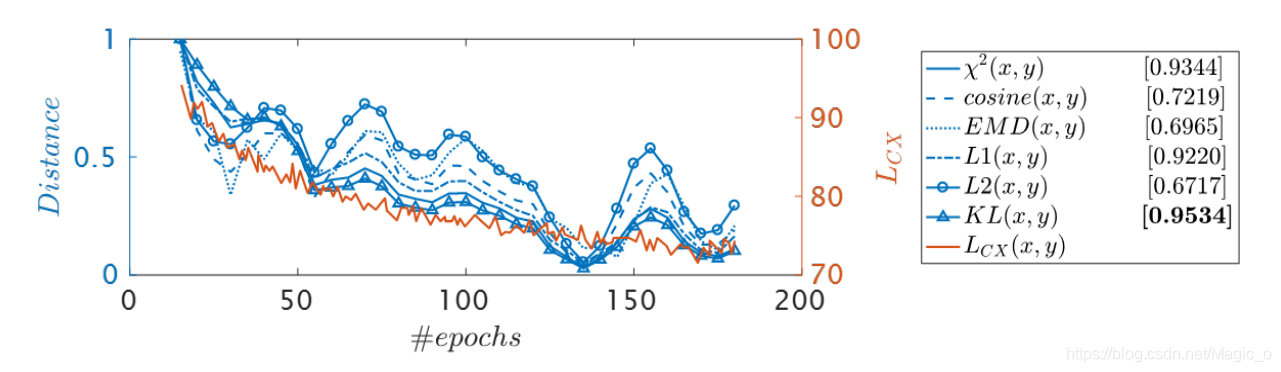
- 第二个实验是评价的关系背景损失和人对图像质量的感知。

兼顾三种损失。 (i)The Contextual loss (ii) TheL2 loss(iii)adversarial term,


我们采用SRGAN架构[https://github.com/tensorlayer/SRGAN],只替换目标。我们训练它只使用800张来自于DIV2K数据集[36]的1500个epoch的图像。我们的网络初始化的第一次训练只使用L2损失100个epoch。
我们在使用VGG19的中间层,即conv3 4的上下文丢失特性时,获得了高感知质量。
这与[9]中的报告形成对比,后者必须使用SRGAN的高层conv5 4来处理感知损失(并且在使用低层如conv2时失败)。同样,EnhanceNet需要混合使用pool2和pool5。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









