







原文出处:http://blog.csdn.net/pirage/article/details/9368535
在LDA主题模型之后,需要对模型的好坏进行评估,以此依据,判断改进的参数或者算法的建模能力。
Blei先生在论文《Latent Dirichlet Allocation》实验中用的是Perplexity值作为评判标准。
一、Perplexity定义
源于wiki:http://en.wikipedia.org/wiki/Perplexity
perplexity是一种信息理论的测量方法,b的perplexity值定义为基于b的熵的能量(b可以是一个概率分布,或者概率模型),通常用于概率模型的比较
wiki上列举了三种perplexity的计算:
1.1 概率分布的perplexity
公式:
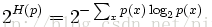
其中H(p)就是该概率分布的熵。当概率P的K平均分布的时候,带入上式可以得到P的perplexity值=K。
1.2 概率模型的perplexity
公式:
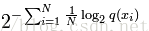
公式中的Xi为测试局,可以是句子或者文本,N是测试集的大小(用来归一化),对于未知分布q,perplexity的值越小,说明模型越好。
指数部分也可以用交叉熵来计算,略过不表。
1.3单词的perplexity
perplexity经常用于语言模型的评估,物理意义是单词的编码大小。例如,如果在某个测试语句上,语言模型的perplexity值为2^190,说明该句子的编码需要190bits
二、如何对LDA建模的主题模型
Blei先生在论文里只列出了perplexity的计算公式,并没有做过多的解释。
在摸索过得知,M代表测试语料集的文本数量(即多少篇文本),Nd代表第d篇文本的大小(即单词的个数),P(Wd)代表文本的概率,文本的概率是怎么算出来的呢?
在解决这个问题的时候,看到rickjin这样解释的:

p(z)表示的是文本d在该主题z上的分布,应该是p(z|d)
这里有个误区需要注意:Blei是从每篇文本的角度来计算perplexity的,而rickjin是从单词的角度计算perplexity的,不要弄混了。
总结一下:
测试文本集中有M篇文本,对词袋模型里的任意一个单词w,P(w)=∑z p(z|d)*p(w|z),即该词在所有主题分布值和该词所在文本的主题分布乘积。
模型的perplexity就是exp^{ - (∑log(p(w))) / (N) },∑log(p(w))是对所有单词取log(直接相乘一般都转化成指数和对数的计算形式),N的测试集的单词数量(不排重)















 6238
6238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









