






LDA Part2: topic个数的选择
目前比较成熟的判断一个LDA模型是否合理的标准一般有两个,一个是一致性,另一个是困惑度。
困惑度perplexity表示的对于一篇文章来说,我们有多不确定它是属于某个主题的。即主题的个数越多,模型的困惑度就越低,即主题的个数越多,模型的困惑度就越低,但是注意一点,当主题数很多的时候,生成的模型往往会过拟合,所以不能单纯依靠困惑度来判断一个模型的好坏。这时候我们的另一个判断标准就有作用了——一致性!
一致性评估基于词语共现的频率,衡量了主题中词语之间的相关性。通过计算每个主题的一致性评分,并在不同主题数量下比较这些分数,可以找到使一致性评分最高的主题数量。
通常,一致性评估会随着主题数量的增加而增加,但在某个点之后会达到饱和状态,不再增加,这时候的主题数量可以被认为是最佳的选择。
Coherence:
Topic个数的选取,一致性角度(即两个词语的语境相关性)
#定义函数,计算在观察到词语word2的情况下,观察到词语word1的条件概率的对数值
def log_prob_see_word1_given_see_word2(word1, word2, feature_names, eps=0.1):#eps:一个小的正数,用于平滑计算,防止分母为0导致的数学错误
word1_column_idx = tf_vectorizer.vocabulary_[word1]#获取字典中的列索引
word2_column_idx = tf_vectorizer.vocabulary_[word2]#获取字典中的列索引
documents_with_word1 = (tf[:, word1_column_idx].toarray().flatten() > 0)
documents_with_word2 = (tf[:, word2_column_idx].toarray().flatten() > 0)
documents_with_both_word1_and_word2 = documents_with_word1 * documents_with_word2
return np.log2((documents_with_both_word1_and_word2.sum() + eps) / documents_with_word2.sum())
#利用这些索引,在稀疏矩阵 tf 中找出含有这两个词的文档。接着计算两个词共同出现的文档数,并用这个数目除以含有word2的文档总数来计算条件概率,最后返回这个概率的对数值。
#定义函数计算所有主题的平均一致性,主题-词概率矩阵,每个主题中权重最高的词的数量,词汇表,打印详细信息
def compute_average_coherence(topic_word_probabilities, num_top_words, feature_names, verbose=True):
num_topics = len(topic_word_probabilities) # 10个topic
average_coherence = 0
for topic_idx in range(num_topics): # 依次循环topic
if verbose:
print('[Topic ', topic_idx, ']', sep='')
sort_indices = np.argsort(topic_word_probabilities[topic_idx])[::-1] # 回忆topic_word_distributions,k*v矩阵,每个topic中单词的权重是多少,np.argsort()[::-1] 返回从大到小的索引值,即topic中词权重最大的索引到最小的索引
coherence = 0.#初始化 coherence 为0,用于累计当前主题的一致性得分
for top_word_idx1 in sort_indices[:num_top_words]: # 选择对排名前20的词计算coherence
word1 = feature_names[top_word_idx1] # 按index输出单词是什么
for top_word_idx2 in sort_indices[:num_top_words]: # 选择第二个单词
word2 = feature_names[top_word_idx2]
if top_word_idx1 != top_word_idx2: # 排除相同单词,前20的每一对不同的word1和word2,计算它们的条件概率的对数值,并累加到 coherence
coherence += log_prob_see_word1_given_see_word2(word1, word2, feature_names, 0.1) # 依次计算并累加,在出现了word2的情况下,word1出现的概率,整体概率越高说明coherence越好
if verbose:
print('Coherence:', coherence) # 输出每个topic的总coherence
print()
average_coherence += coherence # 将不同Topic的coherence累加
average_coherence /= num_topics # 累加的coherence求/Topic个数,得模型coherence的平均值
if verbose:
print('Average coherence:', average_coherence)
return average_coherence
# 查看每个tpoic最可能的单词(概率大小排序),并试图用这些单词来解释不同主题对应的内容。
num_top_words = 20 # 概率大小排序后前20个词
compute_average_coherence(topic_word_probabilities, num_top_words, feature_names, True)
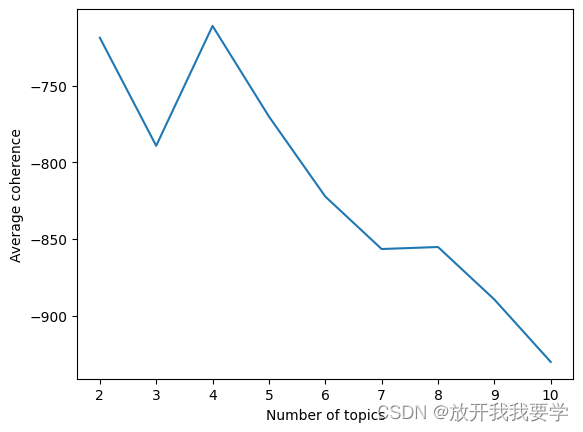
将topic值依次循环,计算每个LDA模型的 average coherence,我们希望 average coherence 越大越好
k_values = range(2, 11) # 设置不同的主题数量,从2到10
avg_coherences = [] # 存储每种主题数量的平均一致性
avg_num_unique_words = []
num_top_words = 20 # 定义每个主题要显示的最多词数
for k in k_values: # 遍历不同的主题数量
lda_candidate = LatentDirichletAllocation(n_components=k, random_state=0)
lda_candidate.fit(tf) # 使用文档-词频矩阵tf拟合LDA模型
# 计算每个主题的词概率分布
topic_word_contributions = lda_candidate.components_
topic_word_totals = topic_word_contributions.sum(axis=1)
topic_word_probabilities = topic_word_contributions / topic_word_totals[:, np.newaxis]
print('-' * 80)
print('Number of topics:', k)
print()
# 打印每个主题的主要词汇及其概率
print_top_words_probabilities(topic_word_probabilities, num_top_words, feature_names)
print()
print()
avg_coherences.append(compute_average_coherence(topic_word_probabilities, num_top_words, feature_names, False))
绘图可视化
plt.plot(k_values, avg_coherences)
plt.xlabel('Number of topics')
plt.ylabel('Average coherence')
Perplexity
通过调包+循环的方式计算Perplexity
import numpy as np
from sklearn.decomposition import LatentDirichletAllocation
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
# 加载数据
data, _ = fetch_20newsgroups(shuffle=True, random_state=1, remove=('headers', 'footers', 'quotes'), return_X_y=True)
tf_vectorizer = CountVectorizer(max_df=0.95, min_df=2, max_features=1000, stop_words='english')
tf = tf_vectorizer.fit_transform(data)
# 设置主题数范围
topic_range = range(2, 31)#定义k值的范围
perplexity_scores = [] #初始化困惑度
for k in topic_range:
lda = LatentDirichletAllocation(n_components=k, random_state=0)
lda.fit(tf)
perplexity = lda.perplexity(tf)
perplexity_scores.append(perplexity)
print(f"Number of topics: {k}, Perplexity: {perplexity}")
在所有模型中找到具有最低困惑度的模型——评估结果
# 找到最低困惑度的主题数
min_perplexity = min(perplexity_scores)
optimal_topics = topic_range[perplexity_scores.index(min_perplexity)]
print(f"Optimal number of topics: {optimal_topics}, Minimum Perplexity: {min_perplexity}")
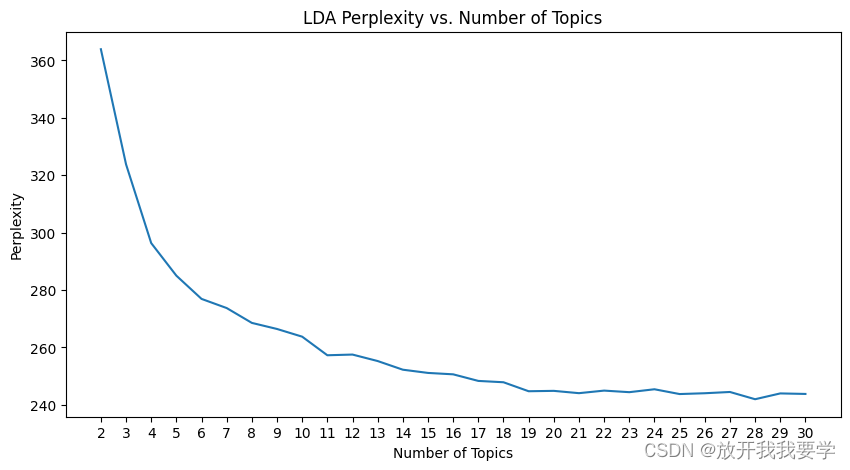
Perplexity困惑度可视化
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 5))
plt.plot(topic_range, perplexity_scores)
plt.title("LDA Perplexity vs. Number of Topics")
plt.xlabel("Number of Topics")
plt.ylabel("Perplexity")
plt.xticks(topic_range)
plt.grid(False) # 设置为False来取消网格显示
plt.show()















 5198
5198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









