







1 Logistic regression
在这部分的练习中,你将建立一个逻辑回归模型来预测一个学生是否能进入大学。假设你是一所大学的行政管理人员,你想根据两门考试的结果,来决定每个申请人是否被录取。你有以前申请人的历史数据,可以将其用作逻辑回归训练集。对于每一个训练样本,你有申请人两次测评的分数以及录取的结果。为了完成这个预测任务,我们准备构建一个可以基于两次测试评分来评估录取可能性的分类模型。
1.1 Visualizing the data
在开始实施算法之前,最好将数据可视化
添加库
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report
读取训练集数据
path = 'ex2data1.txt'
data = pd.read_csv(path, header=None, names=['exam 1 score', 'exam 2 score', 'admitted'])
# print(data.head())
# print(data.describe())
将正向类和负向类以散点图形式画出
# 将录取和未录取数据分开
positive = data[data.admitted.isin(['1'])]
negative = data[data.admitted.isin(['0'])]
# 可视化训练集数据
fig, ax = plt.subplots(figsize=(6, 5))
ax.scatter(positive['exam 1 score'], positive['exam 2 score'], c='black', marker='+', label='admitted')
ax.scatter(negative['exam 1 score'], negative['exam 2 score'], c='yellow', marker='o', label='not admitted')
ax.legend(loc=2) # 数据点注释
ax.set_xlabel('exam 1 score')
ax.set_ylabel('exam 2 score')
ax.set_title('trainging data')

1.2 sigmoid 函数
def sigmoid(x):
return np.exp(x) / (1 + np.exp(x))
1.3 代价函数
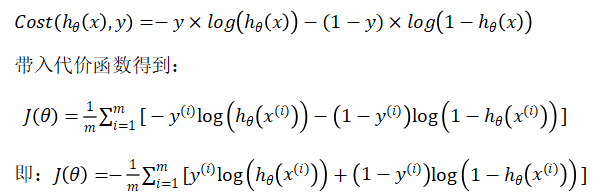
def computecost(X, y, theta):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(np.dot(X, theta.T))))
second = np.multiply((1 - y), np.log(1 - sigmoid(np.dot(X, theta.T))))
return np.sum(first - second) / (len(X))
1.4 梯度下降

def gradientdescent(X, y, theta, alpha, epoch):
temp = np.matrix(np.zeros(theta.shape))
m = X.shape[0]
cost = np.zeros(epoch)
for i in range(epoch):
A = sigmoid(np.dot(X, theta.T))
temp = theta - (alpha / m) * (A - y).T * X
theta = temp
cost[i] = computecost(X, y, theta)
return theta, cost
1.5 训练 theta 参数
在训练之前先将学生成绩进行归一化处理
data.insert(0, 'Ones', 100)
cols = data.shape[1] # 列数
X = data.iloc[:, 0:cols - 1]
y = data.iloc[:, cols - 1:cols]
# theta = np.zeros(X.shape[1])
theta = np.ones(3)
X = np.matrix(X)
X = X / 100 # 归一化
y = np 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2020
2020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









