







1. 概述
为了使JDBC更加易于使用,Spring在JDBC API上定义了一个抽象层,以此建立一个JDBC存取框架。
作为Spring JDBC框架的核心,JDBC模板的设计目的是为不同类型的JDBC操作提供模板方法,通过这种方式,可以在尽可能保留灵活性的情况下,将数据库存取的工作量降到最低。
可以将Spring的JdbcTemplate看作是一个小型的轻量级持久化层框架,和我们之前使用过的DBUtils风格非常接近。
2. 环境准备
1 导入JAR包
- 1)IOC容器所需要的JAR包
commons-logging-1.1.1.jar
spring-beans-4.0.0.RELEASE.jar
spring-context-4.0.0.RELEASE.jar
spring-core-4.0.0.RELEASE.jar
spring-expression-4.0.0.RELEASE.jar - 2)JdbcTemplate所需要的JAR包
spring-jdbc-4.0.0.RELEASE.jar
spring-orm-4.0.0.RELEASE.jar
spring-tx-4.0.0.RELEASE.jar - 3)数据库驱动和数据源
druid-1.1.9.jar
mysql-connector-java-5.1.7-bin.jar
2 创建连接数据库基本信息属性文件
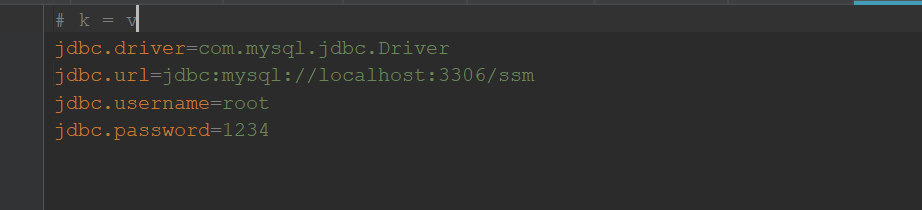
创建一个db.properties的文件
里面以k=v 的形式编写数据库基本配置:
如:
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/ssm
jdbc.username=root
jdbc.password=1234
3 在Spring配置文件中配置相关的bean
spring中可用两种方式引入文件:
①用包里面的方式
<bean class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="location" value="db.properties"/>
</bean>
②用context:property-placeholder标签引入
<context:property-placeholder location="db.properties"/>
这里我们用第二种方式引入文件并创建数据源:
<!--引入资源文件-->
<context:property-placeholder location="db.properties"/>
<!--创建数据源-->
<bean id="dataSourse" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
- 再通过数据源配置jdbcTemplate
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSourse"/>
</bean>
3.持久化操作
- 1)增删改
JdbcTemplate.update(String, Object…)
如这里增加一个数据:
@Test
public void test(){
// jdbcTemplate.update("insert into emp values(null ,'张三',30,'男')");
String sql = "insert into emp values(null ,?,?,?)";
jdbcTemplate.update(sql,"李四",24,"女");
}
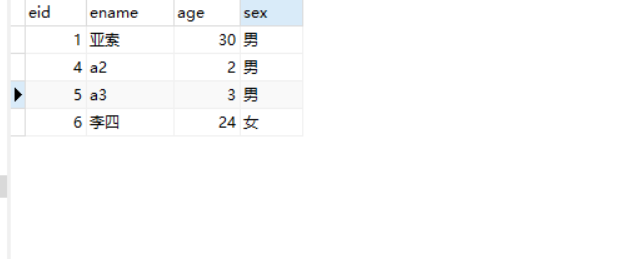
结果:
删除和修改与增加同理!
@Test
public void test2(){
String sql = "delete from emp where eid = ?";
jdbcTemplate.update(sql,2);
}
@Test
public void test3(){
String sql = "update emp set ename = ? where eid = ?";
jdbcTemplate.update(sql,"亚索",1);
}
- 2)批量增删改
JdbcTemplate.batchUpdate(String, List<Object[]>)
Object[]封装了SQL语句每一次执行时所需要的参数
List集合封装了SQL语句多次执行时的所有参数
//批量增删改
@Test
public void testBatchUpdata(){
String sql = "insert into emp values(null ,?,?,?)";
List<Object[]> list = new ArrayList<>();
list.add(new Object[]{"a1",1,"男"});
list.add(new Object[]{"a2",2,"男"});
list.add(new Object[]{"a3",3,"男"});
jdbcTemplate.batchUpdate(sql,list);
}
结果:

这里需要注意一个问题:
①不能使用通配符批量删除和修改:
如:

这里会发现,最终运行结果,只是删除了eid为1的数据,2和3并没有被删除。
是因为通配符赋值后在mysql中会通过setstring默认加上’‘两个单引号,如上面的1,2,3.就会变成’1,2,3’。
如果非要这么做可以用拼接:

模糊查询也不可以用通配符赋值

赋值之后同理会被加两个单引号,就和%旁边的单引号冲突。
如果非要这样一样可用拼接:

赋值之后成这样:

形成的单引号就会把+省略掉,成:
- 3)查询单行
JdbcTemplate.queryForObject(String, RowMapper, Object…)
JdbcTemplate.queryForObject(String, Class, Object…)
…

单条查询:
@Test
public void testQueryForObject(){
String sql = "select eid,age,ename,sex from emp where eid = ?";
RowMapper<emp> rowMapper = new BeanPropertyRowMapper<>(emp.class);//将列名与属性名进行映射
emp emp = jdbcTemplate.queryForObject(sql,new Object[] {7},rowMapper);
System.out.println(emp);
}
结果:

查询数据数量:
@Test
public void testQueryForObject(){
String sql = "select count(*) from emp";
Integer count = jdbcTemplate.queryForObject(sql, Integer.class);
System.out.println(count);
}
结果:

- 4)查询多行
JdbcTemplate.query(String, RowMapper, Object…)
RowMapper对象依然可以使用BeanPropertyRowMapper
@Test
public void testQuery(){
String sql = "select eid,ename,age,sex from emp";
RowMapper<emp> rowMapper = new BeanPropertyRowMapper<>(emp.class);
List<emp> emps = jdbcTemplate.query(sql, rowMapper);
for (emp emp:emps
) {
System.out.println(emp);
}
}
结果:
















 1075
1075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









