







原论文地址:https://arxiv.org/abs/1608.06993
用Keras写的pre-model代码地址:https://github.com/flyyufelix/DenseNet-Keras
一、主要原理
其借鉴了ResNet的思想,用dense connectivity的方式更加缩短了头尾之间层的连接,使得
在前向传播过程中,每一层都与其他所有层相连
于是一个有L层的DenseNet就有L(L+1)/2个连接,每一层都将之前所有层输出的feature map 连结起来作为自己的输入,然后再把自己的输出输送给之后的所有层
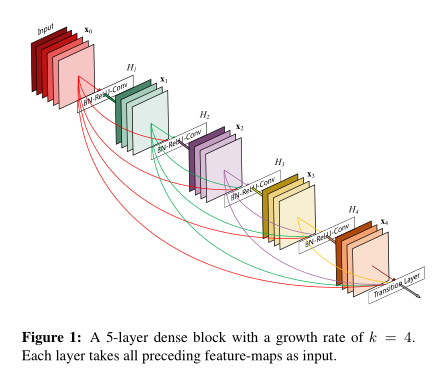
这个网络的优点如下:
1.减轻了梯度弥散的问题,使模型不容易过拟合
2.增强了特征在各个层之间的流动,因为每一层都与初始输入层还有最后的由loss function得到的梯度直接相连
3.大大减少了参数个数,提高训练效率
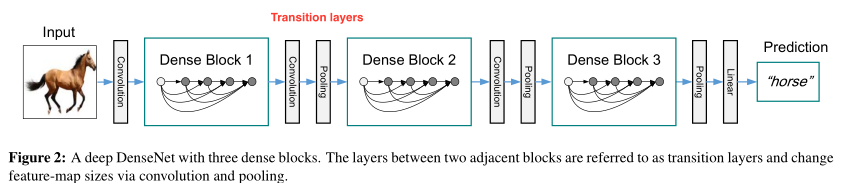
【与ResNet比较】
ResNet是引入了一个skip-connection使得每一层的输出为经过非线性变化的结果加上恒等于输入的函数
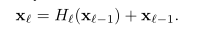
而DenseNet为了更加提高信息在层与层之间的流动,它将每一层都与之后的每一层相连
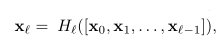
H括号里的就是0到 l-1层的所有feature maps的连结,这里的H是指BN+ReLU+3*3卷积的组合(同ResNet)
【几个特殊的地方】
1.Transition layers
由于在dense block中每经过一个conv_block,就要增加growth_rate个feature map,所以需要在一个dense block后加入transition layers来压缩一定数量的feature maps,保证训练的高效性。
2.在一个dense block里,每个conv_block的输出会与输入接在一起传递给下一个Conv block,以此类推,使得每个conv_block都彼此相连,且把feature map都连结起来,而不是加起来
【代码的研读】
这里是训练ImageNet用的121层的网络结构,各个层配置如下:

from keras.models import Model
from keras.layers import Input, merge, ZeroPadding2D
from keras.layers.core import Dense, Dropout, Activation
from keras.layers.convolutional import Convolution2D
from keras.layers.pooling import AveragePooling2D, GlobalAveragePooling2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
import keras.backend as K
from custom_layers import Scale
def DenseNet(nb_dense_block=4, growth_rate=32, nb_filter=64, reduction=0.0, dropout_rate=0.0, weight_decay=1e-4, classes=1000, weights_path=None):
'''Instantiate the DenseNet 121 architecture,
# Arguments
nb_dense_block: number of dense blocks to add to end
growth_rate: number of filters to add per dense block
nb_filter: initial number of filters
reduction: reduction factor of transition blocks. 1-theta
dropout_rate: dropout rate
weight_decay: weight decay factor
classes: optional number of classes to classify images
weights_path: path to pre-trained weights
# Returns
A Keras model instance.
'''
eps = 1.1e-5
# compute compression factor
compression = 1.0 - reduction
# Handle Dimension Ordering for different backends
global concat_axis
if K.image_dim_ordering() == 'tf':
concat_axis = 3# 通道数在第三维
img_input = Input(shape=(224, 224, 3), name='data')
else:
concat_axis = 1
img_input = Input(shape=(3, 224, 224), name='data')
# From architecture for ImageNet (Table 1 in the paper)
nb_filter = 64
nb_layers = [6,12,24,16] # For DenseNet-121
# Initial convolution
x = ZeroPadding2D((3, 3), name='conv1_zeropadding')(img_input)
x = Convolution2D(nb_filter, 7, 7, subsample=(2, 2), name='conv1', bias=False)(x)
x = BatchNormalization(epsilon=eps, axis=concat_axis, name='conv1_bn')(x)
x = Scale(axis=concat_axis, name='conv1_scale')(x)
x = Activation('relu', name='relu1')(x) #(?,112,112,64)
x = ZeroPadding2D((1, 1), name='pool1_zeropadding')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), name='pool1')(x) #(?,56,56,64)
# Add dense blocks
for block_idx in range(nb_dense_block - 1):
stage = block_idx+2
x, nb_filter = dense_block(x, stage, nb_layers[block_idx], nb_filter, growth_rate, dropout_rate=dropout_rate, weight_decay=weight_decay)
# Add transition_block
x = transition_block(x, stage, nb_filter, compression=compression, dropout_rate=dropout_rate, weight_decay=weight_decay)
nb_filter = int(nb_filter * compression)
final_stage = stage + 1
x, nb_filter = dense_block(x, final_stage, nb_layers[-1], nb_filter, growth_rate, dropout_rate=dropout_rate, weight_decay=weight_decay)
x = BatchNormalization(epsilon=eps, axis=concat_axis, name='conv'+str(final_stage)+'_blk_bn')(x)
x = Scale(axis=concat_axis, name='conv'+str(final_stage)+'_blk_scale')(x)
x = Activation('relu', name='relu'+str(final_stage)+'_blk')(x)
x = GlobalAveragePooling2D(name='pool'+str(final_stage))(x)
x = Dense(classes, name='fc6')(x)
x = Activation('softmax', name='prob')(x)
model = Model(img_input, x, name='densenet')
if weights_path is not None:
model.load_weights(weights_path)
return model
def conv_block(x, stage, branch, nb_filter, dropout_rate=None, weight_decay=1e-4):
'''Apply BatchNorm, Relu, bottleneck 1x1 Conv2D, 3 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









