






注意事项
1.当抽取特定类(classes)进行训练时,可以使用以下方法:
class_indices = list(range(10, 20)) + list(range(50, 60))+list(range(80,90)) #定义要抽取的类别序号
#根据类别序号抽取训练和测试样本
#CIFAR-100数据集的标签是从0开始的,所以类别序号[10, 19]对应于标签索引[10, 20),
#类别序号[50, 59]对应于标签索引[50, 60)。确保你在定义类别序号时与数据集的类别对应。
#train_sampler和test_sampler,它们是自定义的采样器。采样器用于确定从数据集中选择哪些样本用于训练和测试。
#在这里,train_sampler和test_sampler分别使用train_indices和test_indices来选择相应的样本。
train_indices = [i for i in range(len(train_data)) if train_data.targets[i] in class_indices]
train_sampler = torch.utils.data.sampler.SubsetRandomSampler(train_indices) #创建自定义的采样器,仅选择包含所选类别的样本
test_indices = [i for i in range(len(test_data)) if test_data.targets[i] in class_indices]
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_indices)
print(len(train_sampler))
print(len(test_sampler))
#利用dataloader来加载数据集
train= DataLoader(train_data, batch_size=64, sampler=train_sampler) #在下面的源码解释中可以看出,如果sampler不为默认的None的时候,不用设置shuffle属性了
test = DataLoader(test_data, batch_size=64, sampler=test_sampler)2.原始数据集每个数据由data(图片)和targets(标签)两部分组成,通过train_data.data和train_data.targets调用,图片的维度(shape)为(32, 32, 3),测试代码如下:
# 试验输出
print(train_data.targets[0]) #输出第一个标签值,为19,对应牛的标签
print(type(train_data.targets)) # <class 'list'>,数据集标签类型是列表
print(train_data.data[0].shape) #(32, 32, 3) 原始数据集图像的维度
plt.imshow(train_data.data[0]) #输出了牛的图片
plt.show()3.在使用DataLoader处理完数据集后,图片的维度(shape)变为torch.Size([3, 32, 32]),这是神经网络能够接受的维度和类型,因此如果需要输出DataLoader处理过后的数据的图片,需要进行维度转换,具体操作见下:
examples = enumerate(test) #将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
batch_idx, (example_imgs, example_labels) = next(examples) #next的作用是返回迭代器的下一个项目,这里相当于取出来了test_data的第一个batch
print(batch_idx) #0
print(example_imgs[0].shape) #torch.Size([3, 32, 32]),经过DataLoader后,数据的维度会从32,32,3变为3,32,32,即神经网络能够接受的维度
print(example_labels[0].shape) #torch.Size([])
fig = plt.figure()
for i in range(64):
img=example_imgs[i] #3,32,32是原本图片数据的维度
img=np.transpose(img,(1,2,0)) #32,32,3需要转换成该维度才能输出3通道图片,即彩色图片
plt.subplot(8, 8, i + 1)
plt.imshow(img)
# plt.savefig('CIFAR100')
plt.show()4.传统的ResNet18网络训练CIFAR100正确度不高,因此本文做了优化,主要是改变了第一层卷积层的卷积核以及最大池化层的参数;优化器的选择;学习率的设置;dropout的设置。
网络结构图如下(图上的参数没有修改,具体参数设置请参考代码):
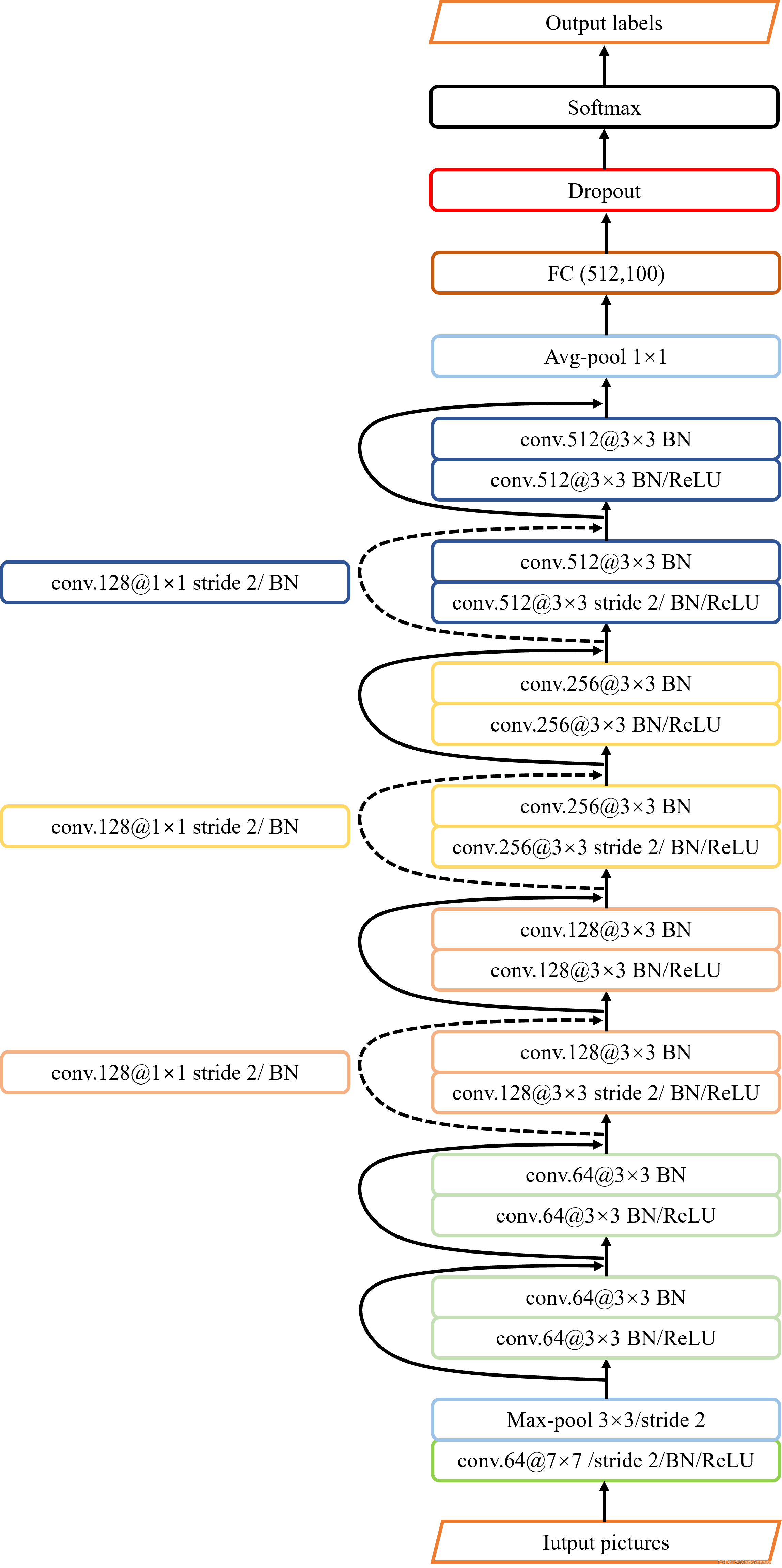
具体代码
具体代码如下:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
import pickle
import time
if torch.cuda.is_available():
device=torch.device("cuda")
else:
device=torch.device("cpu")
mean = [0.5070751592371323, 0.48654887331495095, 0.4409178433670343]
std = [0.2673342858792401, 0.2564384629170883, 0.27615047132568404]
transforms_fn=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean, std)
])
#100 classes containing 600 images each. There are 500 training images and 100 testing images per class.
#训练集
train_data=torchvision.datasets.CIFAR100('./cifar100_data',train=True,transform=transforms_fn,download=True)
#测试集
test_data=torchvision.datasets.CIFAR100('./cifar100_data',train=False,transform=transforms_fn,download=True)
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集的长度为{}".format(train_data_size))
print("测试数据集的长度为{}".format(test_data_size))
# 试验输出
print(train_data.targets[0]) #输出第一个标签值,为19,对应牛的标签
print(type(train_data.targets)) # <class 'list'>,数据集标签类型是列表
print(train_data.data[0].shape) #(32, 32, 3) 原始数据集图像的维度
plt.imshow(train_data.data[0]) #输出了牛的图片
plt.show()
class_indices = list(range(10, 20)) + list(range(50, 60))+list(range(80,90)) #定义要抽取的类别序号
#根据类别序号抽取训练和测试样本
#CIFAR-100数据集的标签是从0开始的,所以类别序号[10, 19]对应于标签索引[10, 20),
#类别序号[50, 59]对应于标签索引[50, 60)。确保你在定义类别序号时与数据集的类别对应。
#train_sampler和test_sampler,它们是自定义的采样器。采样器用于确定从数据集中选择哪些样本用于训练和测试。
#在这里,train_sampler和test_sampler分别使用train_indices和test_indices来选择相应的样本。
train_indices = [i for i in range(len(train_data)) if train_data.targets[i] in class_indices]
train_sampler = torch.utils.data.sampler.SubsetRandomSampler(train_indices) #创建自定义的采样器,仅选择包含所选类别的样本
test_indices = [i for i in range(len(test_data)) if test_data.targets[i] in class_indices]
test_sampler = torch.utils.data.sampler.SubsetRandomSampler(test_indices)
print(len(train_sampler))
print(len(test_sampler))
#利用dataloader来加载数据集
train= DataLoader(train_data, batch_size=64, sampler=train_sampler) #在下面的源码解释中可以看出,如果sampler不为默认的None的时候,不用设置shuffle属性了
test = DataLoader(test_data, batch_size=64, sampler=test_sampler)
examples = enumerate(test) #将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
batch_idx, (example_imgs, example_labels) = next(examples) #next的作用是返回迭代器的下一个项目,这里相当于取出来了test_data的第一个batch
print(batch_idx) #0
print(example_imgs[0].shape) #torch.Size([3, 32, 32]),经过DataLoader后,数据的维度会从32,32,3变为3,32,32,即神经网络能够接受的维度
print(example_labels[0].shape) #torch.Size([])
fig = plt.figure()
for i in range(64):
img=example_imgs[i] #3,32,32是原本图片数据的维度
img=np.transpose(img,(1,2,0)) #32,32,3需要转换成该维度才能输出3通道图片,即彩色图片
plt.subplot(8, 8, i + 1)
plt.imshow(img)
# plt.savefig('CIFAR100')
plt.show()
# examples = enumerate(test_data) #将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
# batch_idx, (example_data, example_targets) = next(examples)
# fig = plt.figure()
# for i in range(100):
# plt.subplot(4,25,i+1)
# plt.tight_layout()
# plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
# plt.title("Ground Truth: {}".format(example_targets[i]))
# plt.xticks([])
# plt.yticks([])
# plt.show()
#定义残差块ResBlock
class ResBlock(nn.Module):
def __init__(self,inchannel,outchannel,stride=1):
super(ResBlock, self).__init__()
#定义残差块里连续的2个卷积层
self.block_conv=nn.Sequential(
nn.Conv2d(inchannel,outchannel,kernel_size=3,stride=stride,padding=1),
nn.BatchNorm2d(outchannel),
nn.ReLU(),
# nn.MaxPool2d(2),
nn.Conv2d(outchannel,outchannel,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(outchannel)
)
# shortcut 部分
# 由于存在维度不一致的情况 所以分情况
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != outchannel:
self.shortcut = nn.Sequential(
# 卷积核为1 进行升降维
# 注意跳变时 都是stride!=1的时候 也就是每次输出信道升维的时候
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
def forward(self,x):
out1=self.block_conv(x)
out2=self.shortcut(x)+out1
out2=F.relu(out2) #F.relu()是函数调用,一般使用在foreward函数里。而nn.ReLU()是模块调用,一般在定义网络层的时候使用
return out2
#构建RESNET18
class ResNet_18(nn.Module):
def __init__(self,ResBlock,num_classes):
super(ResNet_18, self).__init__()
self.in_channels = 64 #输入layer1时的channel
#第一层单独卷积层
self.conv1=nn.Sequential(
# (n-f+2*p)/s+1,n=28,n=32
# nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3),
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1), #64
nn.BatchNorm2d(64),
nn.ReLU(),
# nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
nn.MaxPool2d(kernel_size=1, stride=1, padding=0) #64
# nn.Dropout(0.25)
)
self.layer1=self.make_layer(ResBlock,64,2,stride=1) #64
self.layer2 = self.make_layer(ResBlock, 128, 2, stride=2) #32
self.layer3 = self.make_layer(ResBlock, 256, 2, stride=2) #16
self.layer4 = self.make_layer(ResBlock, 512, 2, stride=2) #8
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) #torch.nn.AdaptiveAvgPool2d()接受两个参数,分别为输出特征图的长和宽,其通道数前后不发生变化。
#即这里将输入图片像素强制转换为1*1
# self.linear=nn.Linear(2*2*512,512)
# self.linear2=nn.Linear(512,100)
self.linear=nn.Linear(512*1*1,num_classes)
self.dropout = nn.Dropout(0.3)
# 这个函数主要是用来,重复同一个残差块
def make_layer(self, block, out_channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
x=self.conv1(x)
# x=self.dropout(x)
x=self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x=self.avgpool(x)
x = x.view(x.size(0), -1)
x=self.linear(x)
x=self.dropout(x)
return x
#网络模型
model=ResNet_18(ResBlock,num_classes=100)
model.to(device)
print(model)
#损失函数
loss_fn=nn.CrossEntropyLoss() #对于cross_entropy来说,他首先会对input进行log_softmax操作,然后再将log_softmax(input)的结果送入nll_loss;而nll_loss的input就是input。
#在多分类问题中,如果使用nn.CrossEntropyLoss(),则预测模型的输出层无需添加softmax层!!!
#如果是F.nll_loss,则需要添加softmax层!!!
loss_fn.to(device)
learning_rate=0.01
optimizer=torch.optim.SGD(params=model.parameters(),lr=learning_rate, momentum=0.9,weight_decay=0.0001)
train_acc_list = []
train_loss_list = []
test_acc_list = []
test_loss_list=[]
epochs=50
for epoch in range(epochs):
print("-----第{}轮训练开始------".format(epoch + 1))
train_loss=0.0
test_loss=0.0
train_sum,train_cor,test_sum,test_cor=0,0,0,0
#训练步骤开始
model.train()
for batch_idx,(data,target) in enumerate(train):
data,target=data.to(device),target.to(device)
optimizer.zero_grad() # 要将梯度清零,因为如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加
# output = model(data)
output = model(data)
# loss = loss_fn(output, target)
loss = loss_fn(output, target)
loss.backward()
optimizer.step() # 更新所有的参数
# 计算每轮训练集的Loss
train_loss += loss.item()
_, predicted = torch.max(output.data, 1) # 选择最大的(概率)值所在的列数就是他所对应的类别数,
# train_cor += (predicted == target).sum().item() # 正确分类个数
train_cor += (predicted == target).sum().item() # 正确分类个数
train_sum += target.size(0) # train_sum+=predicted.shape[0]
#测试步骤开始
model.eval()
# with torch.no_grad():
for batch_idx1,(data,target) in enumerate(test):
data, target = data.to(device), target.to(device)
output = model(data)
loss = loss_fn(output, target)
test_loss+=loss.item()
_, predicted = torch.max(output.data, 1)
test_cor += (predicted == target).sum().item()
test_sum += target.size(0)
print("Train loss:{} Train accuracy:{}% Test loss:{} Test accuracy:{}%".format(train_loss/batch_idx,100*train_cor/train_sum,
test_loss/batch_idx1,100*test_cor/test_sum))
train_loss_list.append(train_loss / batch_idx)
train_acc_list.append(100 * train_cor / train_sum)
test_acc_list.append(100 * test_cor/ test_sum)
test_loss_list.append(test_loss / batch_idx1)
#保存网络
torch.save(model,"CIFAR100_epoch{}.pth".format(epochs))
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
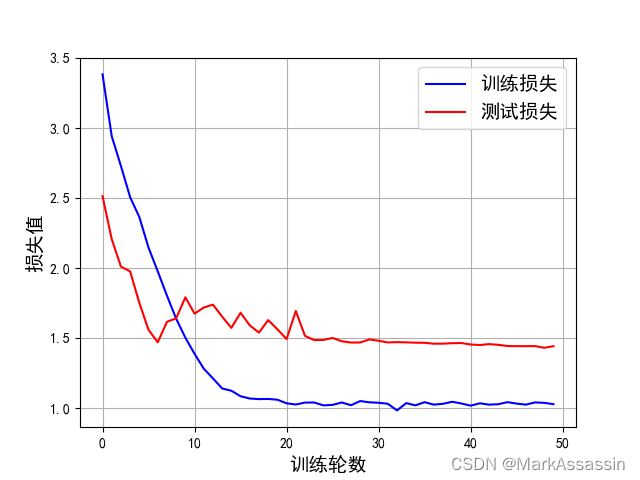
fig=plt.figure()
plt.plot(range(len(train_loss_list)),train_loss_list,'blue')
plt.plot(range(len(test_loss_list)),test_loss_list,'red')
plt.legend(['训练损失','测试损失'],fontsize=14,loc='best')
plt.xlabel('训练轮数',fontsize=14)
plt.ylabel('损失值',fontsize=14)
plt.grid()
# plt.savefig('CIFAR100_figLOSS_6')
plt.show()
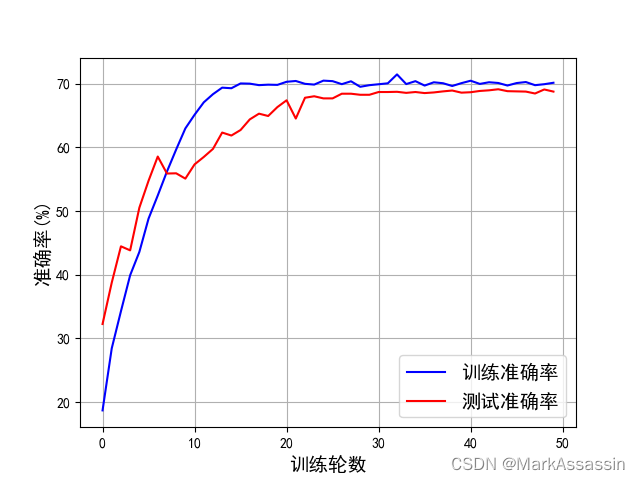
fig=plt.figure()
plt.plot(range(len(train_acc_list)),train_acc_list,'blue')
plt.plot(range(len(test_acc_list)),test_acc_list,'red')
plt.legend(['训练准确率','测试准确率'],fontsize=14,loc='best')
plt.xlabel('训练轮数',fontsize=14)
plt.ylabel('准确率(%)',fontsize=14)
plt.grid()
# plt.savefig('CIFAR100_figAccuracy_6')
plt.show()
训练结果

















 3315
3315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









