






Lab 2A被官方指定为中等难度,对于我这种之前很少写多线程的菜鸡而言,真的花费了大量时间,同时对于论文的理解不够深刻,导致我在写这个lab的过程中多次推倒重写其中的逻辑,以及锁使用的不熟练,让程序在执行过程中经常发生有raft节点死锁。
后续记录一下,我写这个lab 2A过程中的踩的坑。
介绍
Lab 2A就是让你实现leader的选举,因此对于选举这块的逻辑务必要理清,否则写的过程中就会不知如何处理LastLogTerm、Term、LastLogIndex。
go test -race -run 2A #这个就是用来进行Lab 2A的测试指令
注意事项
- 在RPC交互过程中使用的数据结构中的元素的首字母必须大写表示公开。
- 我们不仅要完成投票的过程,还需实现heartbeat的功能,一个raft对象成功当上leader后应当周期性地向其他的对象发送heartbeat来打断它们的选举行为并更新它们的状态。
- 确保我们设立的计时器的时间是一个随机数,同时千万要确保这个随机数每次生成的都是不同(如果只是程序开始执行时随机生成一个,后续均使用这个相同的数字的话,这也是不行的)。timeout时间的随机确保,大概率不会有两个对象同时处于选举状态,基本就是谁先超时发起选举,谁就能称为Leader。
- leader发送的heartbeat的频率不能过快,实验中明确说明最快就是每秒10次。
- 实验给定选举一个Leader的时间限制为5秒,因此timeout时间的设定不能太长,不然可能无法在规定时间内选举出一个leader来。
- 在paper中设定的timeout的时间的设定为150-300ms之间的一个随机值。但是在本实验中不应该选择和paper中一样的参数,因为我们的heartbeat的频率不是很高,在视频中,老师也讲到我们这个timeout的时间应该至少设定为heartbeat间隔的2倍以上,如果在两倍以内的话,一个heartbeat包在网络中弄丢一次,那就导致timeout了。但是timeout时间的设定也不应该太高。我设定的timeout的时间为210-420ms,
- 同时,由于我们在实验中需要周期的计时器,我们的timeout检测以及heartbeat的间隔检测都是需要这样的计时器,因此应该是使用两个go routine来分别负责这两个功能,同时时间的检测应该使用time.Sleep()这个函数,这样写起来最简单。
- 同时在写代码的过程中,建议使用插桩法,在必要的地方使用fmt.Printf()来进行输出信息,在后续进行搜查bug区域有很大的作用。
- 不要忘记完成GetState()函数,这个函数是打分程序需要用的。
- 在程序中任何使用for循环的地方可以使用rf.Kill() == false来作为循环判断条件,这样可以有效避免已经挂掉的raft实例继续进行的怪事。
本次实验的内容
- 完善Raft结构体内的信息。
- 完善GetState()函数
- 完善RequestVoteArgs和RequestVoteReply结构体的信息
- 完善RequestVote这个RPC函数,在其中完成投票的逻辑实现。
- 根据RequestVote的例子来进行设计AppendEntries这个RPC的实现,仿照RequestVote,我们需要设计两个结构体,分别对应RPC调用的参数和返回值,以及一个AppendEntries这个RPC函数,这个函数应该要实现raft实例收到AppendEntries后的逻辑。此外还可以仿照sendRequesVote来实现sendAppendEntries函数。
- 完善ticker()函数,这个函数需要做判断是否进入candidate状态,发起投票,并实现投票的功能。
- 设计heartbeat函数,这个函数用于给leader调用,实现给其他的raft实例周期地发送heartbeat。
- 完善Make()函数,这个函数中应该要完成各个raft实例的初始化。
代码阶段
Raft结构体信息完善
我在这里面定义了心跳的间隔时间为100ms,计数器超时的时间设定为210ms-420ms范围内的一个随机数。
在raft结构体内,我添加了paper中Figure2中提及到的变量。
我自己添加的变量为state,lastLogIndex,lastLogTerm。这三个变量就是字面意义,用于RequestVote和AppendEntries函数。
mesMutex和messageCond以及opSelect。
mesMutex:这是一个互斥锁,由于raft结构体中的变量诸多,这么多变量都只用一个锁的话,我觉得会导致go routine之间的性能降低,因此添加了这个互斥锁用于访问opSelect这个使用频率很高的变量。
opSelect:这个变量用于表示发生了什么事件。
=0:这个变量的初始化
=1:follower阶段的计时器超时,应当转变为candidate发起election
=2:candidate收集到了足够的票数,应当转变为leader
=3:candidae在投票选举过程中超时了,应当更新term,发起新的一轮election
= -1:表示raft实例接受到了消息,需要重置timer,并且自己的身份已经转变为了follower。例如:收到来自leader的ae消息;投票给了其他raft实例等
messageCond:这是一个条件变量,以mesMutex作为它的互斥锁。一个raft实例在等待opSelect的变化来决定后续的操作的时候,可以通过wait这个条件变量,当opSelect发生改变的时候,就需要对messageCond进行广播,对等待opSelect的go routine即可被唤醒继续执行。举例来说:一个follower在开始阶段,opSelect=0,需要等待后续事件,如果发生timeout,则opSelect = 1;如果收到投票要求并成功投票,则opSelect = -1,后续需要重置timer等。
changeOpSelect函数:由于mesMutex这是一个针对opSelect变量的互斥锁,每次修改这个变量都需要对这个锁操作,因此将修改操作封装到了一个函数中。
注意:我们在查看opSelect变量的同时调用changeOpSelect函数会导致死锁,因为查看opSelect变量前需要申请锁,没有释放锁就直接调用changeOpSelect,由于changeOpSelect又要申请锁,此时将无法获取这个锁从而导致死锁。
type logEntry struct {
}
var HeartBeatInterval = 100 // ms
var TimeOutInterval = 210 // ms
//
// A Go object implementing a single Raft peer.
//
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
peerNum int
// persistent state
currentTerm int
voteFor int
log []logEntry
// volatile state
commitIndex int
lastApplied int
// lastHeardTime time.Time
state string
lastLogIndex int
lastLogTerm int
// Candidate synchronize election with condition variable
mesMutex sync.Mutex // used to lock variable opSelect
messageCond *sync.Cond
// opSelect == 1 -> start election, opSelect == -1 -> stay still, opSelect == 2 -> be a leader, opSelect == 3 -> election timeout
opSelect int
// special state for leader
nextIndex []int
matchIndex []int
}
func (rf *Raft) changeOpSelect(num int) {
rf.mesMutex.Lock()
rf.opSelect = num
rf.mesMutex.Unlock()
}
GetState函数的完善
该函数没有什么好讲的,十分简单,唯一需要注意的就是访问raft结构体内的共享变量时,需要先获取锁,后续也记得需要释放锁。
func (rf *Raft) GetState() (int, bool) {
var term int
var isleader bool
// Your code here (2A).
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state == "leader" {
isleader = true
}
term = rf.currentTerm
return term, isleader
}RequestVoteArgs和RequestVoteReply结构体
这些结构体的内容就是简单的照搬paper即可
type RequestVoteArgs struct {
// Your data here (2A, 2B).
Term int
CandidateId int
LastLogIndex int
LastLogTerm int
}
type RequestVoteReply struct {
// Your data here (2A).
Term int
VoteGrand bool
}RequestVote投票函数
投票逻辑
这个函数是本次实验的关键所在,需要我们理清leader election的逻辑。
一个raft实例收到投票RPC请求时,将会收到RequestVoteArgs,其中的Term、LastLogIndex、LastLogTerm都是我们需要关注的,都会影响投票结果。
论文开始讲解的投票流程十分简单,可用以下伪代码来表示:
if args.Term > rf.currentTerm{
同意,更新Term,重置自身信息
} else if args.Term == rf.currentTerm && rf.voteFor == -1{
同意,重置自身信息
} else{
不同意
}
显然这个投票流程是不严谨的,举例表示:
logIndex 1 2
raft1: 1 1(term=1,leader)
raft2: 1 1(term=1)
raft3: 1 此时timeout,term变为2,发起election,term最大,成为leader
三个raft节点,当前raft1为leader,raft1在Term 1下,收到了2条log,并且这两条log已经同步到了大部分节点,可进行commit执行,但是raft1在将index= 2的log发往raft3之前宕机了,此时raft3超时发起election,将自身term变为2,即可成为leader并可强迫其他节点与自身同步,将已经提交的index = 2的log给去除了。
因此,paper在后面部分也提到了election restriction,投票时,节点应当先考虑candidate的log记录是否比自己新,如果比自己的旧就直接拒绝,这可以确保选举出来的leader中的log肯定比大多数的节点的log新,从而确保那些已经commit了的log在leader中肯定也有,因为那些已经commit的log是超过半数的节点拥有的,而leader必须获得超过半数的节点的支持,必定比超过半数的节点的log记录新,因此那些已经commit的log肯定是有的。
那么如何判断谁的log更新呢?
这个公式用以下伪代码来表示
if rf.lastLogTerm > args.LastLogTerm{
candidate的Log比rf的旧,rf不支持
} else if rf.lastLogTerm < args.LastLogTerm{
candidate的log比rf的新,后续根据Term和VoteFor来选择是否支持
} else {
// 这种情况就是两者的lastLogTerm相等,那就是比较LastLogIndex
if rf.lastLogIndex > args.LastLogIndex{
candidate的Log比rf的旧,rf不支持
} else if rf.lastLogIndex < args.LastLogIndex{
candidate的log比rf的新,后续根据Term和VoteFor来选择是否支持
} else {
// Log一致
根据Term和VoteFor来选择是否支持
}
}
为什么LastLogTerm相比更小,那就一定过时呢?
因为,Term=n和Term=n-1相比,n是在(n-1)后面的一轮Term,为了能够成为Term n的leader那么必须拥有Term (n-1)中的大多数节点都有的log,而后续节点收到Term n的leader的log必然是同步了leader上Term= 0 ~(n-1) 的所有log。因此一个节点拥有term n的log,那么表明它一定拥有term 0~(n-1)的所有提交的log。
为什么相同的LastLogTerm的情况下LastLogIndex更大,那么Log记录就越新?
这个也是同理的,一个follower在接受到index = n的log的时候,那么它必然也是已经同步了index在n之前的所有log。
投票后应该采取的措施
一个raft节点投赞成票给candidate后,都会做的
1、重置计时器
2、如果发现Candidate的Term比自己的大,那么应该要更新自己的Term
3、将自己的voteFor设定为candidateId
如果这个节点是Candidate/Leader的话,还需要将自己的state转变为follower。
重置计时器,我们可以通过设置opSelect为-1来通知节点计时器需要重置,如果处于candidate状态则取消投票,变为follower的初始状态,并重新开始计时器;如果仅仅处于follower状态,回到follwer的初始状态,重新开始计时器。
由于raft节点可能处于等待opSelect,即在messageCond.Wait()语句中堵塞着,因此我们还需要进行messageCond.Broadcast()让它及时处理。
以下为RequestVote函数的代码实现,里面可能有大量的注释代码,那些是我当时调试过程中用到的。
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (2A, 2B).
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Term = rf.currentTerm
if args.LastLogTerm < rf.lastLogTerm || args.Term < rf.currentTerm {
// fmt.Printf(" raft%d lastlogterm:%d term:%d refuse raft%d lastlogterm:%d term:%d\n", rf.me, rf.lastLogTerm, rf.currentTerm, args.CandidateId, args.LastLogTerm, args.Term)
reply.VoteGrand = false
return
} else if args.LastLogTerm > rf.lastLogTerm {
// grant the candidate
if rf.currentTerm == args.Term && rf.voteFor != -1 {
// the follower has voted for another one
// fmt.Printf(" raft%d lastlogterm:%d term:%d refuse raft%d lastlogterm:%d term:%d\n", rf.me, rf.lastLogTerm, rf.currentTerm, args.CandidateId, args.LastLogTerm, args.Term)
reply.VoteGrand = false
} else {
// rf.currentTerm > args.Term or the follower has not voted for anyone
// if rf.currentTerm < args.Term {
// fmt.Printf(" raft%d update term from %d to %d\n", rf.me, rf.currentTerm, args.Term)
// }
rf.currentTerm = args.Term
rf.voteFor = args.CandidateId
// fmt.Printf(" raft%d lastlogterm:%d term:%d grand raft%d lastlogterm:%d term:%d\n", rf.me, rf.lastLogTerm, rf.currentTerm, args.CandidateId, args.LastLogTerm, args.Term)
reply.VoteGrand = true
// stop the follower from initiating election, and refresh the timer
rf.changeOpSelect(-1)
rf.state = "follower"
rf.messageCond.Broadcast()
}
} else {
// args.LastLogTerm == rf.lastLogTerm is determined
if args.LastLogIndex >= rf.lastLogIndex {
if rf.currentTerm == args.Term && rf.voteFor != -1 {
// fmt.Printf(" raft%d lastlogterm:%d term:%d refuse raft%d lastlogterm:%d term:%d\n", rf.me, rf.lastLogTerm, rf.currentTerm, args.CandidateId, args.LastLogTerm, args.Term)
reply.VoteGrand = false
} else {
// if rf.currentTerm < args.Term {
// fmt.Printf(" raft%d update term from %d to %d\n", rf.me, rf.currentTerm, args.Term)
// }
rf.currentTerm = args.Term
rf.voteFor = args.CandidateId
// fmt.Printf(" raft%d lastlogterm:%d term:%d grand raft%d lastlogterm:%d term:%d\n", rf.me, rf.lastLogTerm, rf.currentTerm, args.CandidateId, args.LastLogTerm, args.Term)
reply.VoteGrand = true
// stop the follower from initiating election, and refresh the timer
rf.changeOpSelect(-1)
rf.state = "follower"
rf.messageCond.Broadcast()
}
} else {
// args.LastLogIndex < rf.lastLogIndex
// fmt.Printf(" raft%d lastlogterm:%d term:%d refuse raft%d lastlogterm:%d term:%d\n", rf.me, rf.lastLogTerm, rf.currentTerm, args.CandidateId, args.LastLogTerm, args.Term)
reply.VoteGrand = false
}
}
}AppendEntries相关的实现
Leader会周期性地给其他节点发送ae消息,这个RPC调用首先需要实现参数和返回值的结构体设计,结构体的设计直接参照paper即可。同时仿照sendRequestVote写了sendAppendEntries函数。
type AppendEntriesArgs struct {
Term int
LeaderId int
PrevLogIndex int
PrevLogTerm int
Entries []logEntry
LeaderCommit int
}
type AppendEntriesReply struct {
Term int
Success bool
}
func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply) bool {
ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
return ok
}
由于Lab 2A中,仅仅涉及到投票,因此我们无需考虑Log相关的东西,因此十分简单。
节点收到ae消息后,会做以下的措施:
1、检查Leader的Term是否更大,如果没有的话,那就直接返回false以及自己的term。如果是的话,那么进入下一步。
2、认可这个Leader,Term和Leader保持一致,让自己回到follower的初始状态,重新开始计时器,并通过messageCond.Broadcast()来让节点来及时处理。
以下是AppendEntries RPC函数的代码实现
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Term = rf.currentTerm
if args.Term < rf.currentTerm {
reply.Success = false
} else {
// fmt.Printf("raft%d receive ae from leader%d\n", rf.me, args.LeaderId)
reply.Success = true
// if rf.currentTerm < args.Term {
// fmt.Printf("raft%d update term from %d to %d\n", rf.me, rf.currentTerm, args.Term)
// }
rf.currentTerm = args.Term
rf.state = "follower"
rf.changeOpSelect(-1)
rf.messageCond.Broadcast()
}
}RPC调用的注意点!!!!!!!!!!
注意!!!!!在进行RPC调用的时候千万不能持有锁,如果调用过程中持有锁将导致在RPC调用堵塞过程中其他活动也被堵塞。
RPC调用过程中释放锁,在RPC调用结束后,我们千万也要注意,在调用过程中可能发生了大量的事情,可能此RPC的调用已经过期不再具有任何效用。举个例子:在term=5的时候,发起RPC收集票数,当RPC返回收集了足够的票数,但是此时在获取锁来查看状态时,检查发现term=6,那么不能变为leader,因为本次RPC的结果是让该节点成为了term=5的leader,而非term=6的leader。
注意!!!!!在进行RPC调用的时候,应该放到一个新开的协程中进行,避免RPC的堵塞让一个协程的后续的工作也堵塞了。
例如:在投票阶段,candidate应该同时向其他raft节点发起投票RPC,要想实现同时发起的话,那么每次的投票RPC都交给一个新的协程来负责,否则每向一个节点发起投票RPC,就必须等该节点回应后才能向下一个节点发起投票RPC。
for循环和go routine的注意点!!!!
leader向其他节点同时发送heartbeats,Candidate向其他节点同时发送RequestVote RPC的时候,我是通过for循环和go routine配合来实现的,看下面的演示代码
for index := 0; index < peerNum; index++{
if index == rf.me{
continue
}
go func(){
// 发送给index号的raft节点
// 执行下面两个函数两个中的一个
rf.sendRequestVote(index)// 如果是投票RPC就是这个函数
rf.sendHeartBeat(index)// 如果是发送heartbeat就是这个函数
}()
}
以上的代码是有问题的,因为go routine中使用的index是不确定的,你发起go routine时,index为1,但是该 go routine执行时,index被更新了,那么go routine也会使用被更新的index值。当然大概率是,所有go routine执行时,index的值均为peerNum - 1。
因此正确的代码应该如下所示:
将这个index作为func的一个形参,值传递,那么就不会受到影响了。
for index := 0; index < peerNum; index++{
if index == rf.me{
continue
}
go func(){
// 发送给index号的raft节点
// 执行下面两个函数两个中的一个
rf.sendRequestVote(index)// 如果是投票RPC就是这个函数
rf.sendHeartBeat(index)// 如果是发送heartbeat就是这个函数
}(index)
}
ticker()函数的完善
ticker()函数是大多数节点一直在运作的函数。下面讲解这个函数的任务流程:
1、作为follower,初始化opSelect = 0,以及设定timer来计时,查看是否发生超时。若收到ae或者投票给了其他节点,opSelect会被设定为-1。若timer时间到了,发现opSelect 不等于 -1则表明这段时间内,节点没有收到ae或者投票,那么就是发生超时了,将opSelect设定为1,否则这段时间节点发生了事情,已经重新发起了一个新的计时器,该计时器没有意义,无需将opSelect设定为1
我这里将那些在进行过程中会发生堵塞或睡眠无法马上返回,可能会变成无效的过时的事件称为非即时事件,执行那些事件的协程即为非即时协程,例如:candidate向其他节点发起投票RPC调用的事件、计时器事件。而那些不会堵塞或进入睡眠状态的,会立马执行结束的事件就可以叫作即时事件,例如:处理投票请求,处理ae消息等。即时事件不会造成上述的影响。而即时事件的发生会让opSelect设定为-1。
注意:我们这里的timer事件就是一个非即时事件(创建一个新的协程来计时判断是否超时),如果该raft收到消息需要重新发起了一个新的timer的话,那么这个旧的timer就已经作废了,我们需要确保这个旧的非即时事件(旧的timer事件)不会影响到后面的结果。我用term和currentTermTimes这两个变量来保存状态,currentTermTimes记录的是raft节点在当前term下已经计时器重置了多少次。计时器协程在调用time.Sleep进行计时前,需要保存下当前的term和currentTermTimes,如果计时结束后,这两个值保持不变表明,在这期间节点没有重置计时器,这个计时器并非是过时的,是有效的。
这种检查非即时事件是否有效的方法,后续也会用。
2、若发现opSelect==1,则转变状态为candidate,并向其他节点发起RequestVote RPC调用,进入步骤3
若发现opSelect==-1,回到初始步骤1
3、发起投票,同理再开启一个投票阶段的timer,如果timer时间到了,发现opSelect不等于-1就表明发生超时了,将opSelect设定为3表明投票阶段超时。
在初始阶段发生的事件只可能将opSelect改变为-1或1,因此节点发现opSelect非这两个数字,即可判断为过时的无效的非即时协程带来的事件通知,无视,然后继续wait即可。
在投票阶段发生的只可能将opSelect改变为-1、2、3、4,因此节点发现opSelect非这几个数字,即可判断为过时的无效非即时协程带来的事件通知,无视,然后继续wait即可。
4、投票阶段,ticker再发起两个新协程:负责投票的协程vThread和投票阶段计时器协程tThread。然后进入堵塞状态,等待消息。
负责投票的协程vThread:通过创建新的协程来向其他raft节点发起投票RPC调用,并创建一个条件变量voteCond,并voteCond.Wait(),每个投票RPC调用成功后,都会voteCond.Broadcast()来唤醒vThread。
注意:投票RPC返回的结果有多种情况,负责RPC的协程需要区分来处理:
reply.Term > rf.currentTerm:表明candidate本身的term就已经过时了,应当回到初始状态步骤1去。将opSelect设置为4,并唤醒vThread使其结束投票,同时还需唤醒ticker使其回到初始状态步骤1去。
reply.VoteGrand == true:表明一个节点支持,那么就gandNum++,并唤醒vThread来检查一下票数是否足够,若足够则检查成为leader的其余条件是否满足,检查投票时的term和当前的term是否一致,若不一致则表明本次投票已经过时了,作废处理;若一致则满足条件改状态为leader,设置opSelect为2,唤醒ticker协程使得进入下一阶段开始发送heartbeats。
reply.VoteGrand == false:表明一个节点不赞成,那么就refuseNum++,并唤醒vThread来检查是否已经收到全部的raft节点的投票结果,若已经收到了全部的票了refuseNum+grandNum == peerNum,那么就结束本投票协程。等待后续,要么是超时重新发起选举,要么是收到通知需要回到初始状态步骤1.
投票阶段计时器协程tThread:就是初始阶段的计时器一样,设立一个随机时间,如果到时了,那么就尝试将opSelect设置为3,若opSelect为-1或4表明节点已经不是candidate,投票阶段已经结束了,那么就直接退出即可,否则是将opSelect设置为3并通知ticker协程重新开一起一次投票。
5、ticker被唤醒后,确认消息:
如果opSelect == 2,表明节点已经是leader了,那么开启一个新的协程来周期地发送heartbeats,堵塞本协程直到该节点不再是leader了,然后回到初始状态步骤1去,此处的同步简单可以用unbuffered channel来实现。
如果opSelect == 3,表明投票阶段超时了,需要重新开启新的投票
如果opSelect == 4/-1,表明节点已经不是candiate了,需要回到初始状态步骤1去。
以下是ticker()函数的代码实现
// The ticker go routine starts a new election if this peer hasn't received
// heartsbeats recently.
func (rf *Raft) ticker() {
rf.mu.Lock()
var recordTerm = rf.currentTerm
rf.mu.Unlock()
var timeMutex sync.Mutex
var currentTermTimes = 0
for rf.killed() == false {
// fmt.Printf("raft%d as follower start a ticker\n", rf.me)
// Your code here to check if a leader election should
// be started and to randomize sleeping time using
// time.Sleep().
rf.mu.Lock()
timeMutex.Lock()
if recordTerm != rf.currentTerm {
recordTerm = rf.currentTerm
currentTermTimes = 0
}
currentTermTimes++
rf.mu.Unlock()
timeMutex.Unlock()
rand.Seed(time.Now().UnixNano())
sleepTime := rand.Intn(TimeOutInterval) + TimeOutInterval
// fmt.Printf("%v raft%d sleep %d\n", time.Now(), rf.me, sleepTime)
// initialize opSelect variable to test if it will time out
rf.changeOpSelect(0)
go func() {
rf.mu.Lock()
timeMutex.Lock()
var term = rf.currentTerm
var times = currentTermTimes
rf.mu.Unlock()
timeMutex.Unlock()
time.Sleep(time.Duration(sleepTime) * time.Millisecond)
rf.mesMutex.Lock()
defer rf.mesMutex.Unlock()
rf.mu.Lock()
defer rf.mu.Unlock()
timeMutex.Lock()
defer timeMutex.Unlock()
if rf.opSelect != -1 && term == rf.currentTerm && times == currentTermTimes {
rf.opSelect = 1
rf.messageCond.Broadcast()
}
}()
// if recv a ae or rv , opSelect = -1; if timeout, opSelect = 1
// fmt.Printf("raft%d apply for mesMutex\n", rf.me)
rf.mesMutex.Lock()
rf.messageCond.Wait()
for rf.opSelect == 2 || rf.opSelect == 3 {
// fmt.Printf("raft%d's opSelect is 2/3 , it should be -1/1. Stay waiting\n", rf.me)
rf.messageCond.Wait()
}
if rf.opSelect == -1 {
// fmt.Printf("%v raft%d receive a valid message and reset the ticker\n", time.Now(), rf.me)
rf.mesMutex.Unlock()
continue
} else if rf.opSelect == 1 {
// start election
rf.mesMutex.Unlock()
// we should start two thread.
// one thread is a timer to check if the election has timed out
// the other one is responsible for initiating the elction
voteLoop:
for rf.killed() == false {
// if timeout , launch a new election
// ch is used to determine if the election is successful or timeout
rf.mu.Lock()
rf.state = "candidate"
rf.currentTerm++
rf.voteFor = rf.me
var voteArgs = &RequestVoteArgs{}
voteArgs.Term = rf.currentTerm
voteArgs.LastLogTerm = rf.lastLogTerm
voteArgs.LastLogIndex = rf.lastLogIndex
voteArgs.CandidateId = rf.me
rf.mu.Unlock()
var voteMutex sync.Mutex
var voteCond = sync.NewCond(&voteMutex)
rf.changeOpSelect(0)
go func() {
// launch a election
var grandNum = 1
var refuseNum = 0
// fmt.Printf("%v raft%d start election, term:%d\n", time.Now(), rf.me, voteArgs.Term)
rf.mu.Lock()
timeMutex.Lock()
var term = rf.currentTerm
var times = currentTermTimes
var peerNum = rf.peerNum
rf.mu.Unlock()
timeMutex.Unlock()
for index := 0; index < peerNum; index++ {
if index == rf.me {
continue
}
go func(index int) {
var reply = &RequestVoteReply{}
if rf.sendRequestVote(index, voteArgs, reply) {
rf.mu.Lock()
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.state = "follower"
rf.mu.Unlock()
// fmt.Printf("%v raft%d turn back to follower\n", time.Now(), rf.me)
rf.changeOpSelect(4)
rf.messageCond.Broadcast()
voteCond.Broadcast()
return
}
rf.mu.Unlock()
if reply.VoteGrand {
voteCond.L.Lock()
// fmt.Printf("%v raft%d receive a grand from raft%d, term:%d\n", time.Now(), rf.me, index, voteArgs.Term)
grandNum++
voteCond.L.Unlock()
voteCond.Broadcast()
} else {
voteCond.L.Lock()
// fmt.Printf("%v raft%d receive a refuse from raft%d, term:%d\n", time.Now(), rf.me, index, voteArgs.Term)
refuseNum++
voteCond.L.Unlock()
voteCond.Broadcast()
}
}
}(index)
}
var voteSuccess = false
for {
voteCond.L.Lock()
voteCond.Wait()
rf.mu.Lock()
if rf.state == "follower" {
rf.mu.Unlock()
voteCond.L.Unlock()
return
}
// rf.mesMutex.Unlock()
// rf.mu.Lock()
var peerNum = rf.peerNum
rf.mu.Unlock()
if grandNum >= (peerNum/2)+1 {
voteSuccess = true
// fmt.Printf("%v raft%d successfully gets most of votes\n", time.Now(), rf.me)
voteCond.L.Unlock()
break
} else if grandNum+refuseNum == peerNum {
// fmt.Printf("%v raft%d doesn't get most of votes\n", time.Now(), rf.me)
voteCond.L.Unlock()
break
}
voteCond.L.Unlock()
}
// rf.mu.Lock()
// defer rf.mu.Unlock()
if voteSuccess {
rf.mesMutex.Lock()
defer rf.mesMutex.Unlock()
rf.mu.Lock()
defer rf.mu.Unlock()
timeMutex.Lock()
defer timeMutex.Unlock()
if rf.opSelect != -1 && rf.opSelect != 4 && term == rf.currentTerm && times == currentTermTimes {
// suceess means the node successfully becomes a leader
rf.opSelect = 2
rf.state = "leader"
rf.messageCond.Broadcast()
}
// if a node has collected exactly half of the votes, it will wait util timeout and initiate next election
}
}()
go func() {
rand.Seed(time.Now().UnixNano())
sleepTime := rand.Intn(TimeOutInterval) + TimeOutInterval
// fmt.Printf("%v raft%d sleep %d to wait for election\n", time.Now(), rf.me, sleepTime)
rf.mu.Lock()
timeMutex.Lock()
var term = rf.currentTerm
var times = currentTermTimes
rf.mu.Unlock()
timeMutex.Unlock()
time.Sleep(time.Duration(sleepTime) * time.Millisecond)
rf.mesMutex.Lock()
defer rf.mesMutex.Unlock()
rf.mu.Lock()
defer rf.mu.Unlock()
timeMutex.Lock()
defer timeMutex.Unlock()
if rf.opSelect != -1 && rf.opSelect != 4 && term == rf.currentTerm && times == currentTermTimes {
rf.opSelect = 3
rf.state = "leader"
rf.messageCond.Broadcast()
}
}()
rf.mesMutex.Lock()
rf.messageCond.Wait()
for rf.opSelect == 1 || rf.opSelect == 0 {
rf.messageCond.Wait()
}
switch rf.opSelect {
case 2:
rf.mesMutex.Unlock()
// fmt.Printf("%v raft%d is leader now.\n", time.Now(), rf.me)
var leaderch = make(chan int)
go rf.heartBeats(leaderch)
<-leaderch
break voteLoop
case 3:
rf.mesMutex.Unlock()
// fmt.Printf("%v tiemout, raft%d restart a election\n", time.Now(), rf.me)
continue
case 4:
fallthrough
case -1:
rf.mesMutex.Unlock()
// fmt.Printf("%v raft%d stop election\n", time.Now(), rf.me)
break voteLoop
}
}
}
}
}
heartBeats函数的实现
heartBeats函数由leader调用,需要周期性向其他raft节点发送ae消息。
这个心跳的周期,本实验中明确规定了,不能超过每秒10次,因此我设定的频率就是每秒10次,同样通过time.Sleep来实现。
由于Lab 2A仅需实现election功能,因此无需考虑log的事情,那么该函数的逻辑也是十分简单的。每个周期内,向其他的raft节点发送ae消息,同样这个发送ae消息是一个rpc调用,应新开一个协程来进行发送ae,避免堵塞heartBeats协程。
如果ae消息发送后收到的返回消息中,发现有raft节点的term值比自身还高,那表明自身已经过时, 将自己变为follower,并更新自身的Term值,同时将voteFor初始化为-1。
以下为heartBeats函数的代码实现
func (rf *Raft) heartBeats(ch chan int) {
// fmt.Printf("raft%d start sending heartbeats\n", rf.me)
for rf.killed() == false {
_, isLeader := rf.GetState()
if !isLeader {
break
}
rf.mu.Lock()
var peerNum = rf.peerNum
var args AppendEntriesArgs
args.LeaderId = rf.me
args.Term = rf.currentTerm
rf.mu.Unlock()
for index := 0; index < peerNum; index++ {
if index == rf.me {
continue
}
go func(index int) {
var reply AppendEntriesReply
if rf.sendAppendEntries(index, &args, &reply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if reply.Term > rf.currentTerm {
// fmt.Printf("raft%d find a higher term, turn back to follower\n", rf.me)
rf.state = "follower"
rf.currentTerm = reply.Term
rf.voteFor = -1
}
}
}(index)
// fmt.Printf("leader%d send heartbeat to raft%d\n", rf.me, index)
}
// fmt.Printf("leader%d sleep %d\n", rf.me, HeartBeatInterval)
time.Sleep(time.Duration(HeartBeatInterval) * time.Millisecond)
// fmt.Printf("leader%d next heartbeats\n", rf.me)
}
// fmt.Printf("raft%d stop sending heartbeats\n", rf.me)
ch <- 1
}Make()函数的完善
Make函数的职责就是完成raft节点的初始化,十分简单,直接下代码实现即可。
//
// the service or tester wants to create a Raft server. the ports
// of all the Raft servers (including this one) are in peers[]. this
// server's port is peers[me]. all the servers' peers[] arrays
// have the same order. persister is a place for this server to
// save its persistent state, and also initially holds the most
// recent saved state, if any. applyCh is a channel on which the
// tester or service expects Raft to send ApplyMsg messages.
// Make() must return quickly, so it should start goroutines
// for any long-running work.
//
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me
// Your initialization code here (2A, 2B, 2C).
rf.messageCond = sync.NewCond(&rf.mesMutex)
// rf.voteCond = sync.NewCond(&rf.mu)
rf.peerNum = len(peers)
rf.voteFor = -1
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
// start ticker goroutine to start elections
go rf.ticker()
return rf
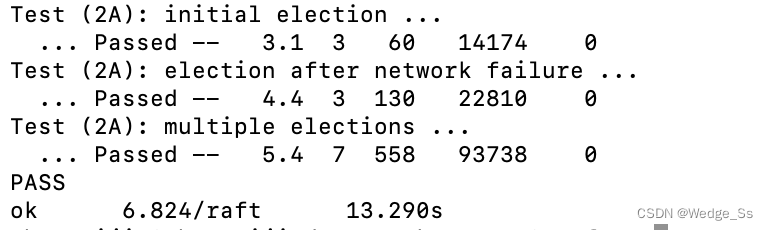
}运行结果图














 1164
1164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









